导读 : 今天主要和大家交流的是网易在数据湖 Iceberg 的一些思考与实践。从网易在数据仓库建设中遇到的痛点出发,介绍对数据湖 Iceberg 的探索以及实践之路。
主要内容包括:
01 数据仓库平台建设的痛点
痛点一 :

我们凌晨一些大的离线任务经常会因为一些原因出现延迟,这种延迟会导致核心报表的产出时间不稳定,有些时候会产出比较早,但是有时候就可能会产出比较晚,业务很难接受。
为什么会出现这种现象的发生呢?目前来看大致有这么几点要素:
痛点二 :
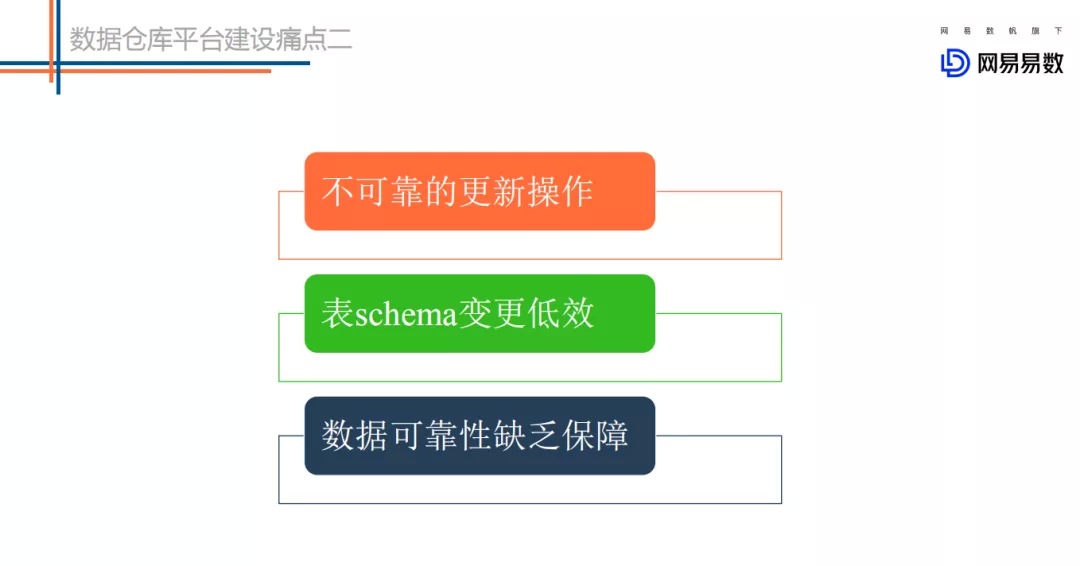
针对一些细琐的一些问题而言的。这里简单列举了三个场景来分析:
痛点三 :
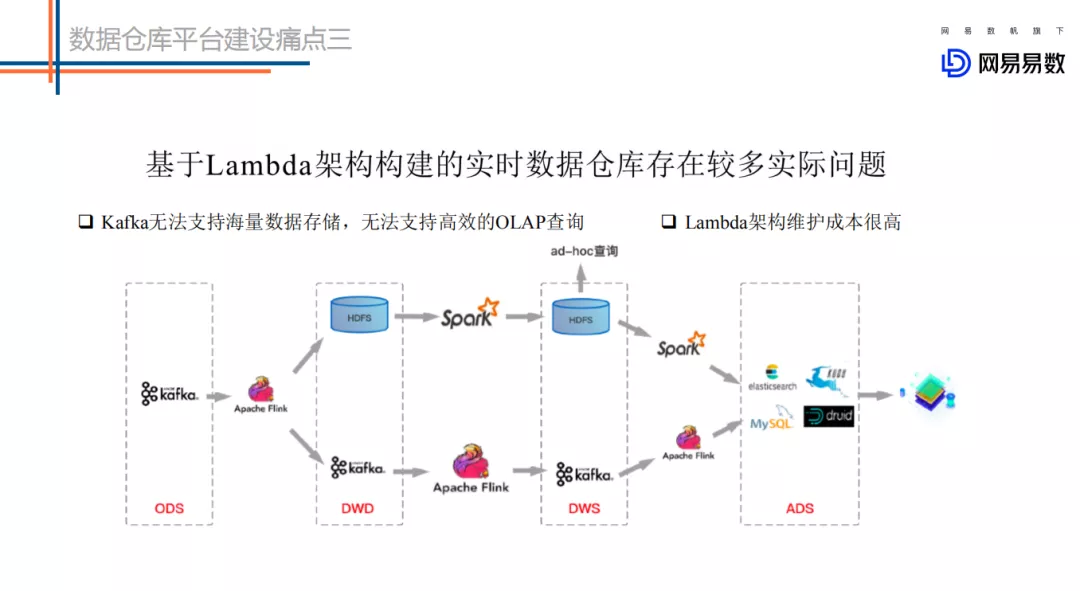
基于 Lambda 架构建设的实时数仓存在较多的问题。如上图的这个架构图,第一条链路是基于 kafka 中转的一条实时链路(延迟要求小于 5 分钟),另一条是离线链路(延迟大于 1 小时),甚至有些公司会有第三条准实时链路(延迟要求 5 分钟~一小时),甚至更复杂的场景。
痛点四 :
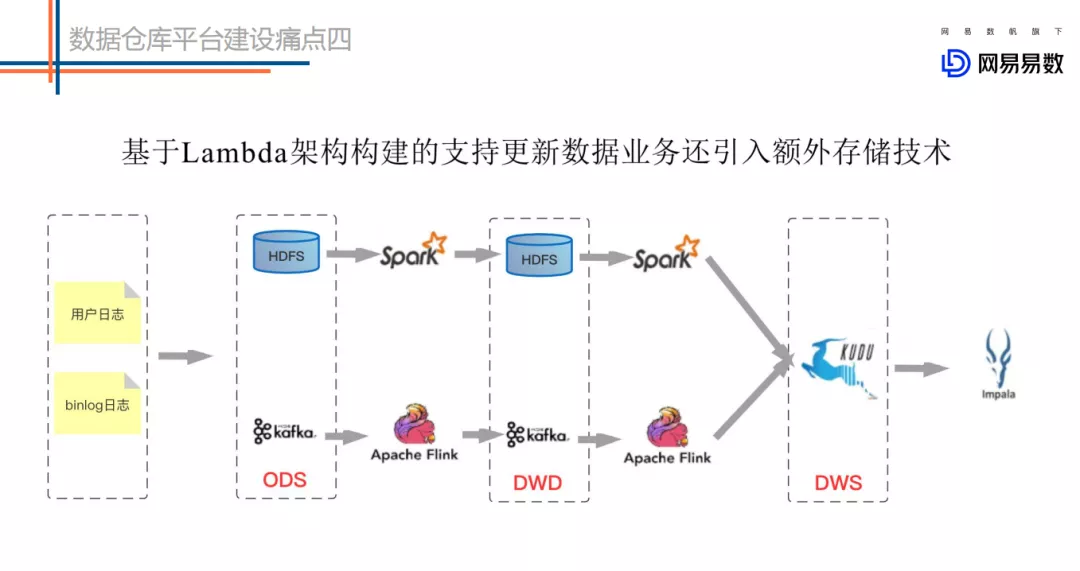
不能友好地支持高效更新场景。大数据的更新场景一般有两种,一种是 CDC ( Change>
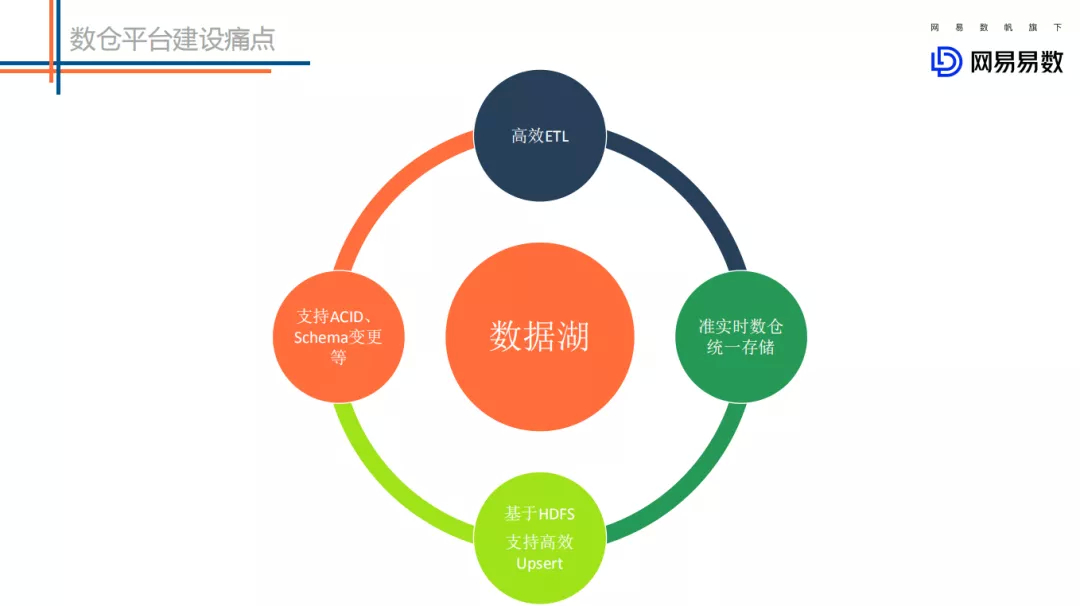
上面就是针对目前数仓所涉及到的四个痛点的大致介绍,因此我们也是通过对数据湖的调研和实践,希望能在这四个方面对数仓建设有所帮助。接下来重点讲解下对数据湖的一些思考。
02 数据湖 Iceberg 核心原理
1. 数据湖开源产品调研

数据湖大致是从 19 年开始慢慢火起来的,目前市面上核心的数据湖开源产品大致有这么几个:
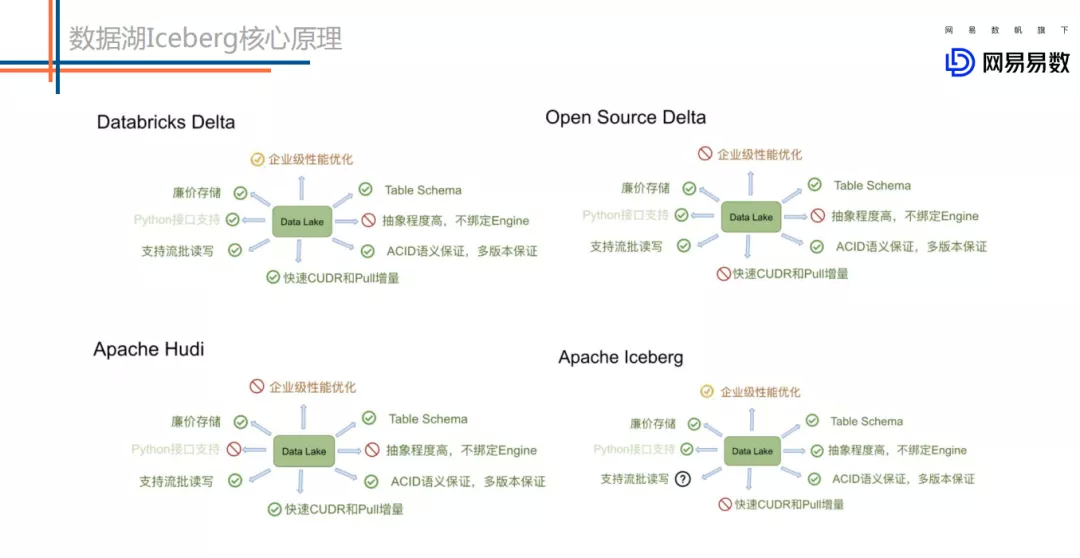
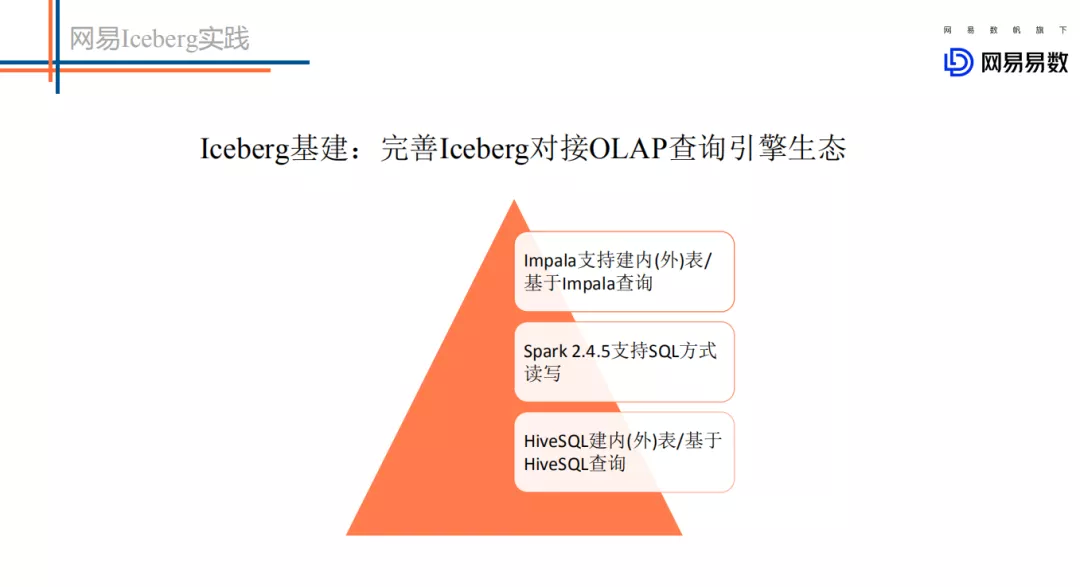
上图是来自阿里 Flink 团体针对数据湖方案的一些调研对比,总体来看这些方案的基础功能相对都还是比较完善的。我说的基础功能主要包括:
2. 当然还有一些不同点 :
3. 我们选择 Iceberg 的原因 :
4. 接下来我们重点介绍一下 Iceberg :

这是来自官方对于 Iceberg 的一段介绍,大致就是 Iceberg 是一个开源的基于表格式的数据湖。关于 table format 再给大家详细介绍下:
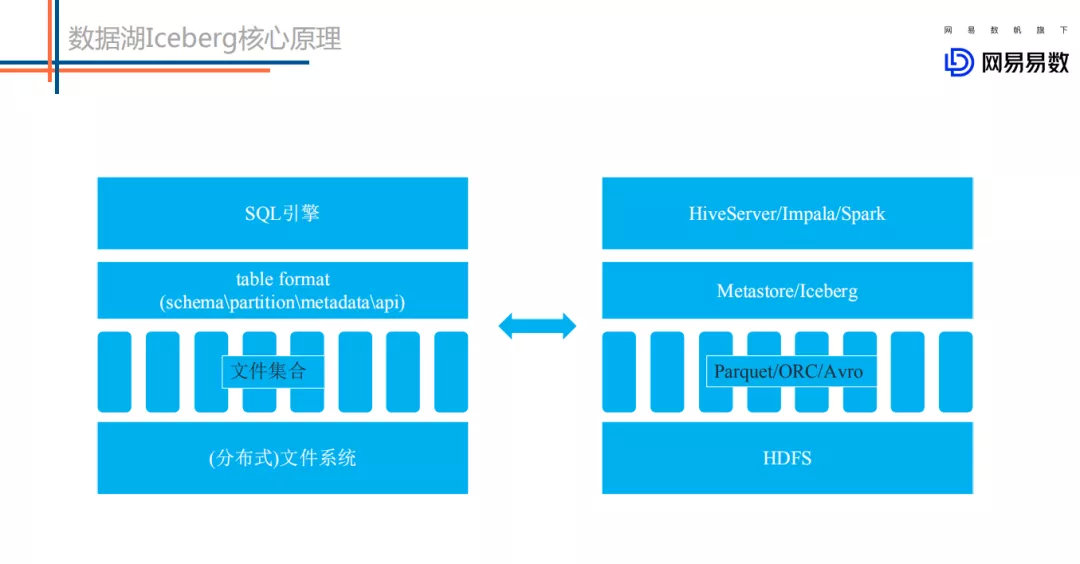
左侧图是一个抽象的数据处理系统,分别由 SQL 引擎、table format、文件集合以及分布式文件系统构成。右侧是对应的现实中的组件,SQL 引擎比如 HiveServer、Impala、Spark 等等,table format 比如 Metastore 或者 Iceberg,文件集合主要有 Parquet 文件等,而分布式文件系统就是 HDFS。
对于 table format,我认为主要包含 4 个层面的含义,分别是表 schema 定义(是否支持复杂数据类型),表中文件的组织形式,表相关统计信息、表索引信息以及表的读写 API 实现。详述如下:
和 Iceberg 差不多相当的一个组件是 Metastore。不过 Metastore 是一个服务,而 Iceberg 就是一个 jar 包。这里就 Metastore 和 Iceberg 在表格式的 4 个方面分别进行一下对比介绍:
① 在 schema 层面上没有任何区别 :

都支持 int、string、bigint 等类型。
② partition 实现完全不同 :
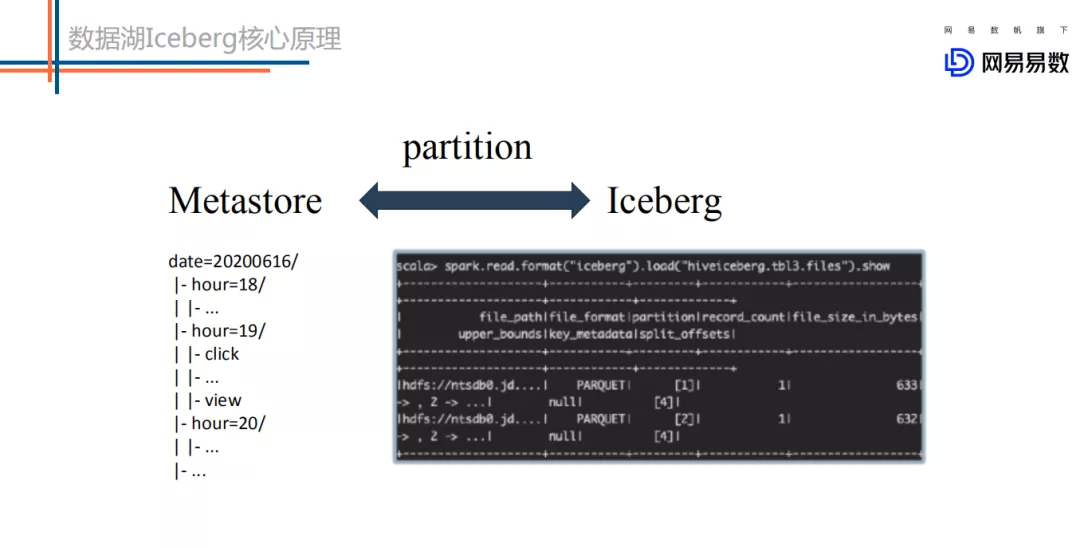
两者在 partition 上有很大的不同:
metastore 中 partition 字段不能是表字段,因为 partition 字段本质上是一个目录结构,不是用户表中的一列数据。基于 metastore,用户想定位到一个 partition 下的所有数据,首先需要在 metastore 中定位出该 partition 对应的所在目录位置信息,然后再到 HDFS 上执行 list 命令获取到这个分区下的所有文件,对这些文件进行扫描得到这个 partition 下的所有数据。
iceberg 中 partition 字段就是表中的一个字段。Iceberg 中每一张表都有一个对应的文件元数据表,文件元数据表中每条记录表示一个文件的相关信息,这些信息中有一个字段是 partition 字段,表示这个文件所在的 partition。
很明显,iceberg 表根据 partition 定位文件相比 metastore 少了一个步骤,就是根据目录信息去 HDFS 上执行 list 命令获取分区下的文件。
试想,对于一个二级分区的大表来说,一级分区是小时时间分区,二级分区是一个枚举字段分区,假如每个一级分区下有 30 个二级分区,那么这个表每天就会有 24 * 30 = 720 个分区。基于 Metastore 的 partition 方案,如果一个 SQL 想基于这个表扫描昨天一天的数据的话,就需要向 Namenode 下发 720 次 list 请求,如果扫描一周数据或者一个月数据,请求数就更是相当夸张。这样,一方面会导致 Namenode 压力很大,一方面也会导致 SQL 请求响应延迟很大。而基于 Iceberg 的 partition 方案,就完全没有这个问题。
③ 表统计信息实现粒度不同 :

Metastore 中一张表的统计信息是表/分区级别粒度的统计信息,比如记录一张表中某一列的记录数量、平均长度、为 null 的记录数量、最大值\最小值等。
Iceberg 中统计信息精确到文件粒度,即每个数据文件都会记录所有列的记录数量、平均长度、最大值\最小值等。
很明显,文件粒度的统计信息对于查询中谓词(即 where 条件)的过滤会更有效果。
④ 读写 API 实现不同 :
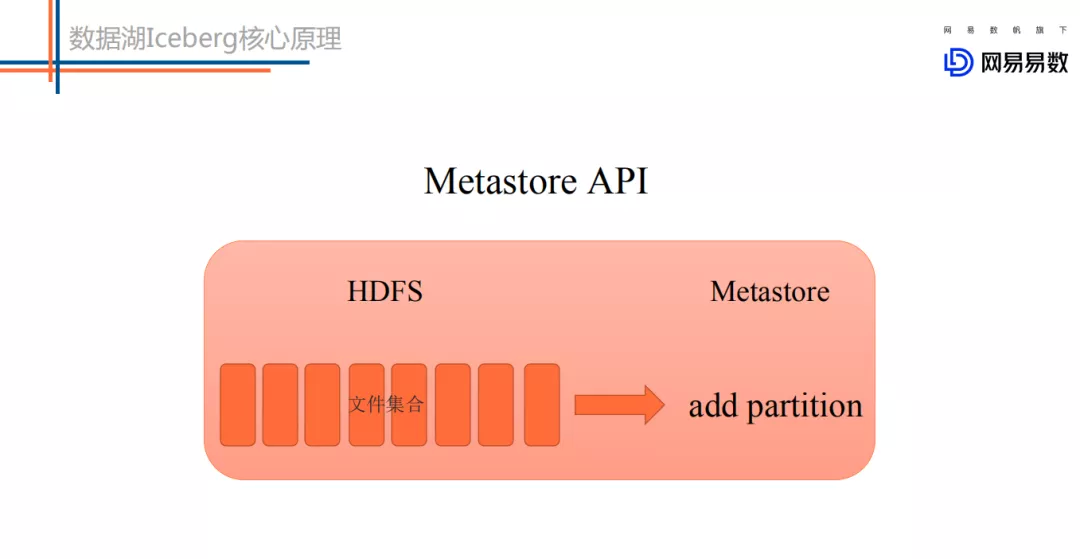
metastore 模式下上层引擎写好一批文件,调用 metastore 的 add partition 接口将这些文件添加到某个分区下。
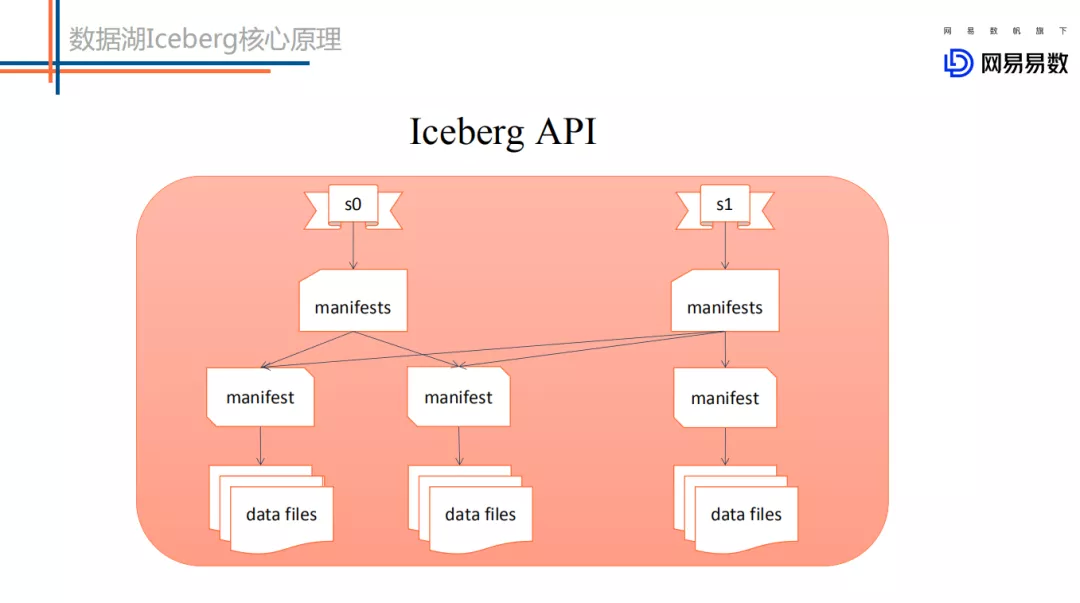
Iceberg 模式下上层业务写好一批文件,调用 iceberg 的 commit 接口提交本次写入形成一个新的 snapshot 快照。这种提交方式保证了表的 ACID 语义。同时基于 snapshot 快照提交可以实现增量拉取实现。
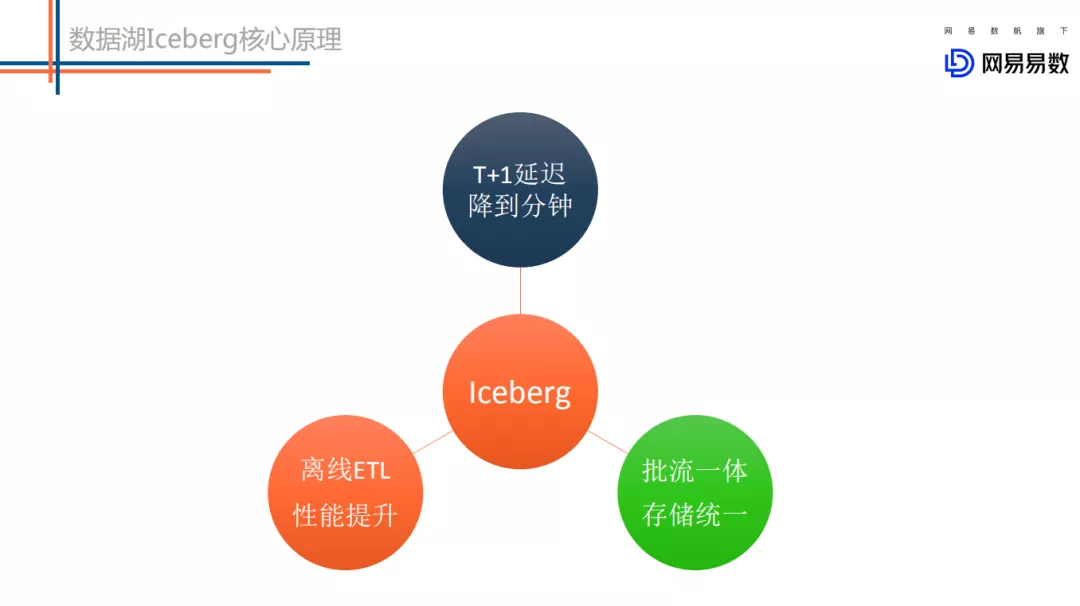
总结下 Iceberg 相对于 Metastore 的优势 :
Iceberg 的提升体现在 :
03 数据湖 Iceberg 社区现状
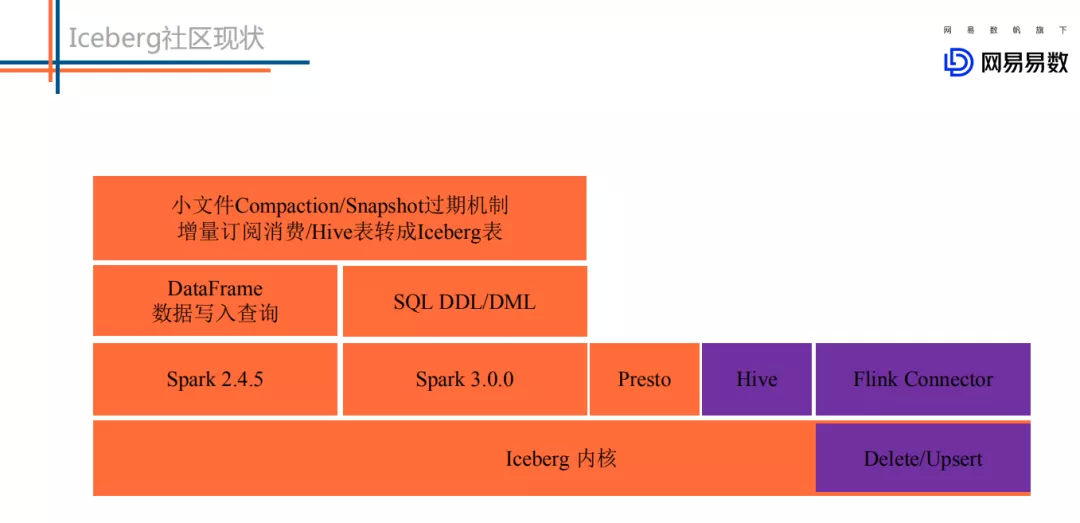
目前 Iceberg 主要支持的计算引擎包括 Spark2.4.5、Spark 3.x 以及 Presto。同时,一些运维工作比如 snapshot 过期、小文件合并、增量订阅消费等功能都可以实现。
在此基础上,目前社区正在开发的功能主要有 Hive 集成、Flink 集成以及支持 Update/Delete 功能。相信下一个版本就可以看到 Hive/Flink 集成的相关功能。
04 网易数据湖 Iceberg 实践之路
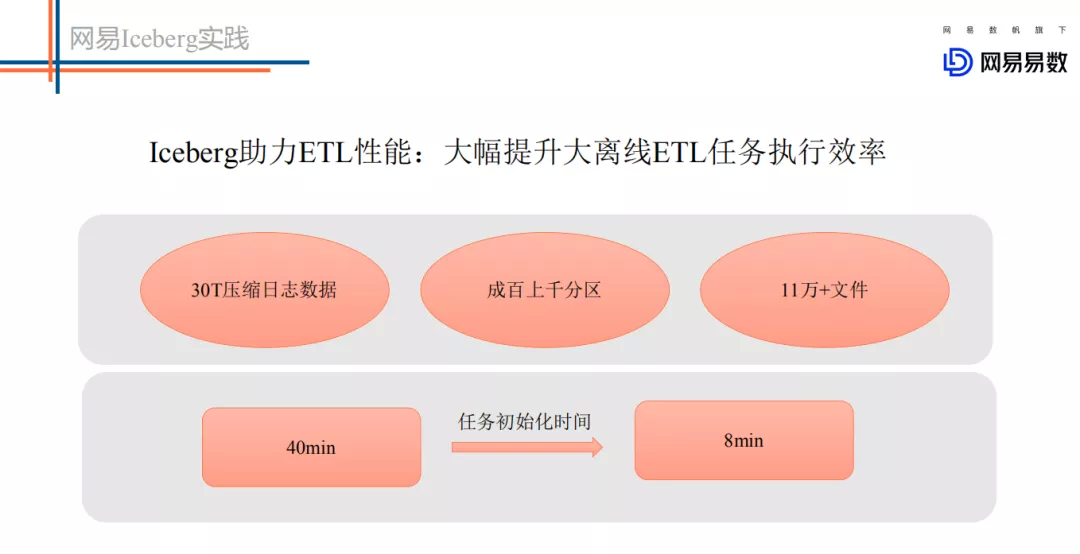
Iceberg 针对目前的大数量的情况下,可以大大提升 ETL 任务执行的效率,这主要得益于新 Partition 模式下不再需要请求 NameNode 分区信息,同时得益于文件级别统计信息模式下可以过滤很多不满足条件的数据文件。
当前 iceberg 社区仅支持 Spark2.4.5,我们在这个基础上做了更多计算引擎的适配工作。主要包括如下:
今天的分享就到这里,谢谢大家。
作者介绍 :
范欣欣 ,网易大数据技术专家
范欣欣,网易大数据技术专家。他与 Apache HBase PMC 成员、小米公司 HBase 工程师胡争合著的新书《HBase 原理与实践》,这也是业界第一本专门阐述 HBase 原理的书。
本文来自>
原文链接 :
网易数据湖探索与实践