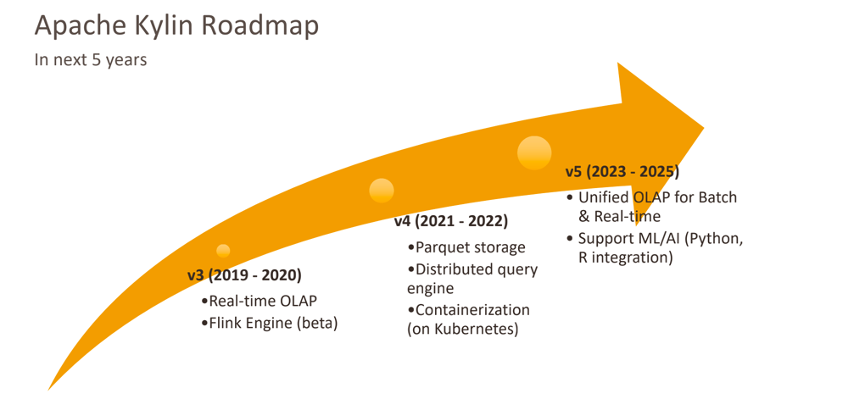
Apache Kylin 社区日前正式发布了 4.0.0-beta 版本。Apache Kylin 是一个开源的分布式分析引擎,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析 (OLAP) 能力,支持对超大规模数据进行亚秒级查询。
Apache Kylin 4.0.0-beta 是继 Kylin 4.0.0-alpha 之后的一个重要版本。当前的 4.0.0-beta 是 Kylin 4.x 发布的第二个测试版本,修复了 4.0.0-alpha 中的若干 bug,并且补充了一些对 Kylin 3.x 原有功能的支持,包括System Cube,Hadoop 3 的支持,部分高级函数,Cube Planner Phase 1等等。
Kylin 4 使用 Parquet 这种真正的列式存储来代替 HBase 存储,从而提升文件扫描性能;同时,Kylin 4 重新实现了基于 Spark 的构建引擎和查询引擎,使得计算和存储的分离变为可能,更加适应云原生的技术趋势。
在互联网企业中的典型使用场景和相关性能测试结果为:
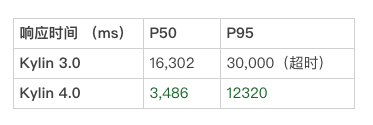
场景一(简单查询)
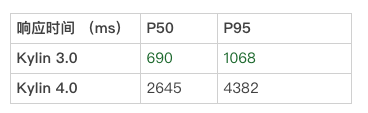
通过以上结果展示,可见在没有做查询优化的情况下, Kylin 4.0 简单查询 的查询响应时间表现不及 Kylin 3.0。通过初步沟通和测试,经过 ShardBy Column 优化手段后,简单查询的查询响应时间可以降低 1~2s,与 Kylin 3.0的性能变得更加接近。
Kylin 4.0 简单查询的查询响应时间表现不及 Kylin 3.0 的原因,经分析主要如下:
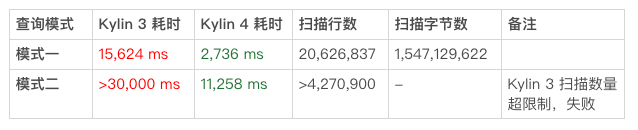
场景二(返回结果行数多的查询)
这些 SQL 的模式主要是如下两类:
由于 IN 子句中包含过多的可选值,加上 package 是高基维度,导致 Kylin 在扫描和二次聚合的压力都非常大,Kylin 3.0 不适合进行这样的“导出式”查询。但 Kylin 4.0 利用 Spark 计算引擎的能力,能够在十分可观的时间内得出需要的结果。这里举个例子:
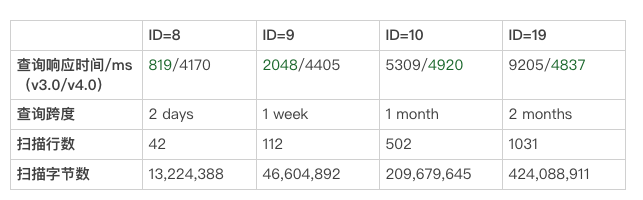
场景三(时间跨度大的查询)
这 4 个查询的 SQL 除了在时间范围上不同其他完全相同。从数据不难看出,时间跨度增长一倍,Kylin 3.0 需要扫描的数据量和查询响应时间也相应地增长近一倍。而 Kylin 4.0 使用 Spark 分布式计算,更高的并行度带来的优势便体现了出来。
当前 Kylin 4.0.0-beta 已经成为一个相对稳定的版本,在多个早期用户的测试验证中都验证了构建和查询功能基本达到相对完备的程度,但是目前仍有不少在性能和功能上的提升空间。
本次发布共添加了 25 个新功能以及改进,修复了 14 个问题,详情请访问:
本次发布重要更新:
[KYLIN-4857] - 为 Kylin 4 重构 System Cube
[KYLIN-4842] - 为 Kylin 4 支持 grouping sets 函数
[KYLIN-4829] - 为查询引擎支持线程级别的 Spark 参数配置
[KYLIN-4813] - 为构建引擎重新开发日志系统
[KYLIN-4858] - 支持在 CDH 6.X 上部署 Kylin 4
[KYLIN-4818] - Kylin 4 支持 Cuboid 行数统计
[KYLIN-4817] - 为 Kylin 4 重构 Cube 迁移工具
下载 Apache Kylin 4.0.0-beta 源代码及二进制安装包,请访问下载页面:
官方 wiki: