编者按 :本文节选自华章科技大数据技术丛书 《Apache Kylin 权威指南(第 2 版)》一书中的部分章节。
Rowkey 优化
前面章节的侧重点是减少 Cube 中 Cuboid 的数量,以优化 Cube 的存储空间和构建性能,统称以减少 Cuboid 的数量为目的的优化为 Cuboid 剪枝。在本节中,将重点通过对 Cube 的 Rowkey 的设置来优化 Cube 的查询性能。
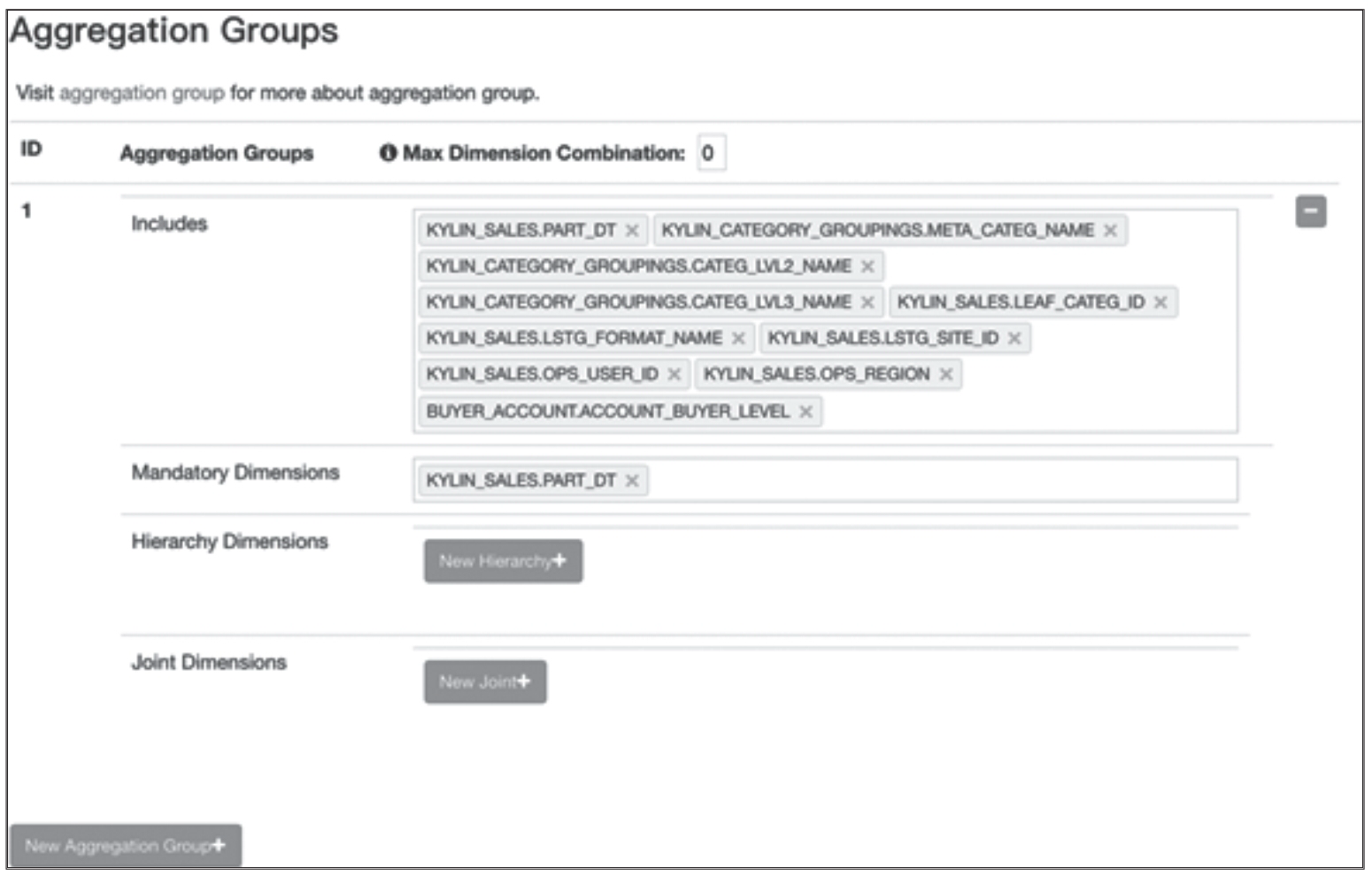
Cube 的每个 Cuboid 中都包含大量的行,每个行又分为 Rowkey 和 Measure 两个部分。每行 Cuboid 数据中的 Rowkey 都包含当前 Cuboid 中所有维度的值的组合。Rowkey 中的各个维度按照 Cube Designer→Advanced Setting→RowKeys 中设置的顺序和编码进行组织,如图 1 所示。

图 1 Rowkey 的设置页面
在 Rowkeys 设置页面中,每个维度都有几项关键的配置,下面将一一道来。
调整 Rowkey 顺序
在 Cube Designer→Advanced Setting→Rowkeys 部分,可以上下拖动每一个维度来调节维度在 Rowkey 中的顺序。这种顺序对于查询非常重要,因为目前在实现中,Kylin 会把所有的维度按照显示的顺序黏合成一个完整的 Rowkey,并且按照这个 Rowkey 升序排列 Cuboid 中所有的行,参照前一章的图 16。
不难发现,对排序靠前的维度进行过滤的效果会非常好,比如在图 16 中的 Cuboid 中,如果对 D1 进行过滤,它是严格按照顺序进行排列的;如果对 D3 进行过滤,它仅是在 D1 相同时在组内顺序排列的。
如果在一个比较靠后的维度进行过滤,那么这个过滤的执行就会非常复杂。以目前的 HBase 存储引擎为例,Cube 的 Rowkey 就对应 HBase 中的 Rowkey,是一段字节数组。我们目前没有创建单独的每个维度上的倒排索引,因此对于在比较靠后的维度上的过滤条件,只能依靠 HBase 的 Fuzzy Key Filter 来执行。尽管 HBase 做了大量相应的优化,但是在对靠后的字节运用 Fuzzy Key Filter 时,一旦前面维度的基数很大,Fuzzy Key Filter 的寻找代价就会很高,执行效率就会降低。所以,在调整 Rowkey 的顺序时需要遵循以下几个原则:
选择合适的维度编码
2.4.3 节介绍过,Apache Kylin 支持多种维度编码方式,用户可以针对数据特征,选择合适的编码方式,从而减小数据的存储空间。在具体使用过程中,如果用错了编码方式,可能会导致构建和查询的一系列问题。这里要注意的事项包括:
按维度分片
在 3.3 节中介绍过,系统会对 Cuboid 中的数据在存储时进行分片处理。默认情况下,Cuboid 的分片策略是对于所有列进行哈希计算后随机分配的。也就是说,我们无法控制 Cuboid 的哪些行会被分到同一个分片中。这种默认的方法固然能够提高读取的并发程度,但是它仍然有优化的空间。按维度分片提供了一种更加高效的分片策略,那就是按照某个特定维度进行分片(Shard By Dimension)。简单地说,当你选取了一个维度用于分片后,如果 Cuboid 中的某两行在该维度上的值相同,那么无论这个 Cuboid 最终被划分成多少个分片,这两行数据必然会被分配到同一个分片中。
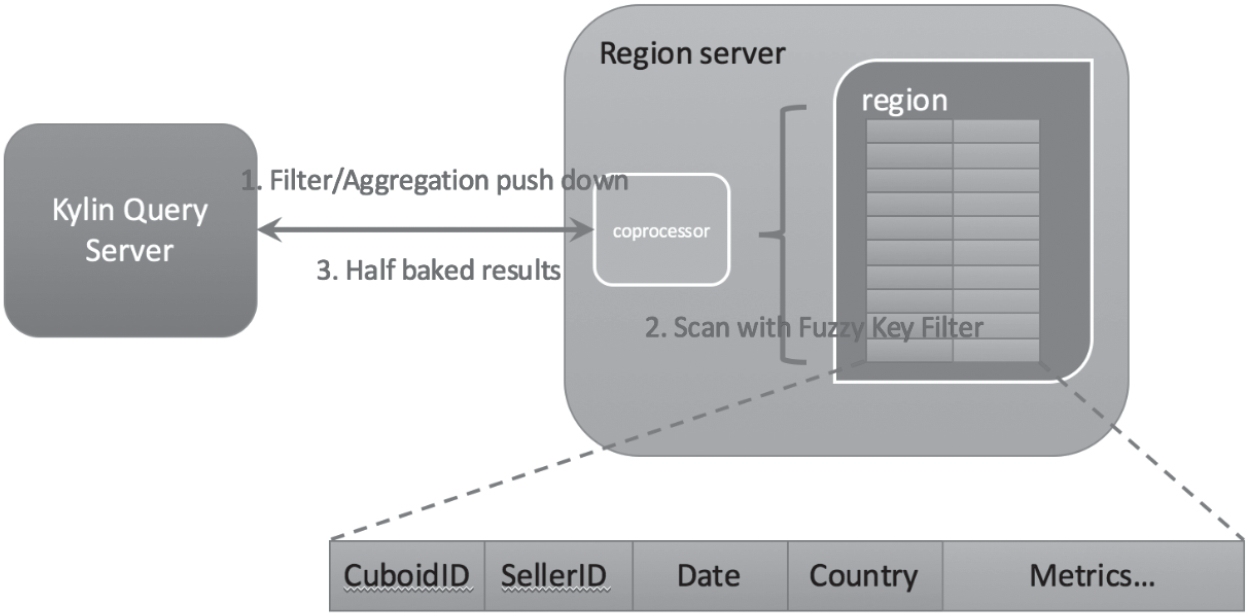
这种分片策略对查询有着极大的好处。我们知道,Cuboid 的每个分片会被分配到存储引擎的不同物理机器上。Kylin 在读取 Cuboid 数据的时候会向存储引擎的若干机器发送读取的 RPC 请求。在 RPC 请求接收端,存储引擎会读取本机的分片数据,并在进行一定的预处理后发送 RPC 回应(如图 2 所示)。以 HBase 存储引擎为例,不同的 Region 代表不同的 Cuboid 分片,在读取 Cuboid 数据的时候,HBase 会为每个 Region 开启一个 Coprocessor 实例来处理查询引擎的请求。查询引擎将查询条件和分组条件作为请求参数的一部分发送到 Coprocessor 中,Coprocessor 就能够在返回结果之前对当前分片的数据做一定的预聚合(这里的预聚合不是 Cube 构建的预聚合,是针对特定查询的深度的预聚合)。
图 2 存储引擎执行 RPC 查询
如果按照维度划分分片,假设是按照一个基数比较高的维度 seller_id 进行分片的,那么在这种情况下,每个分片承担一部分 seller_id,各个分片不会有相同的 seller_id。所有按照 seller_id 分组(group by seller_id)的查询都会变得更加高效,因为每个分片预聚合的结果会更加专注于某些 seller_id,使得分片返回结果的数量大大减少,查询引擎端也无须对各个分片的结果做分片间的聚合。按维度分片也能让过滤条件的执行更加高效,因为由于按维度分片,每个分片的数据都更加“整洁”,便于查找和索引。
图书简介 :src="https://static001.infoq.cn/resource/image/f2/84/f22bf661636663e27a8b1fdbc5e15184.png"/>
相关阅读 :
Apache Kylin权威指南(一):背景历史和使命
Apache Kylin权威指南(二):工作原理
Apache Kylin权威指南(三):技术架构
Apache Kylin权威指南(四):核心概念
Apache Kylin权威指南(五):Getting Started
Apache Kylin权威指南(六):Cuboid剪枝优化
Apache Kylin权威指南(七):剪枝优化工具