大家好,我是卷皮 BI 团队负责人柴楹,今天在这里给大家分享一下卷皮的 BI 和大数据的一些东西。
BI& 大数据是什么?
首先我们来聊一下 BI 和大数据。BI 和大数据到底有什么关系和不同。

BI 主要有三方面的技术,包括 DW,OLAP,DM 。目标就是提高企业经营和决策的质量和效率。
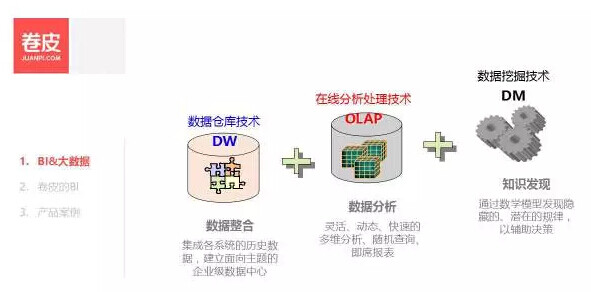
数据仓库(Data Warehouse) 是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理和决策。 OLAP: On-Line Analytical Processing 使分析人员、管理人员能够从多种角度对从原始数据中转化出来的、能够真正为用户所理解的、并真实反映数据维特性的信息,进行快速、一致、交互地访问,从而获得对数据的更深入了解的一类软件技术。 (OLAP 委员会的定义)。 Data Mining 是通过数学模型发现隐藏的、潜在的规律,以辅助决策。
传统 BI 和数据仓库大约是 98-99 年从国外进入中国,经过十几年的发展,更多的是做企业级的数据中心,主要应用在电信业和银行业,需求更多的是做报表和进行一些分析等等。传统的 BI 主要想实现从宏观到微观、从广度到深度、从定量到定性各种层次的决策分析。
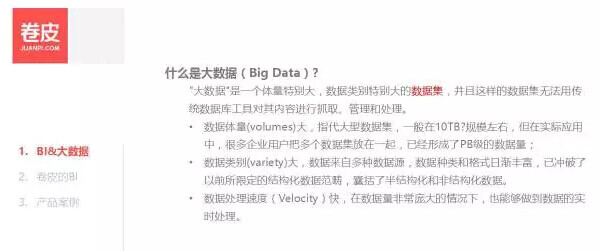
大数据是什么 ?通俗的讲,就是体量特别大的数据集,这个数据集大到无法用传统的数据库工具或者分析工具进行处理。大数据主要有三个特点:
第一,数据体量巨大 。从 TB 级别,跃升到 PB 级别。
第二,数据类型繁多 ,例如网络日志、视频、图片、地理位置信息等等各种结构化非结构化的数据。
第三,处理速度快 。1 秒定律。最后这一点也是和传统的数据挖掘技术有着本质的不同。
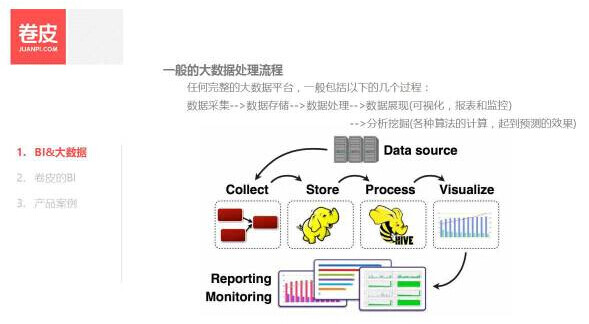
一般的大数据平台都有几个过程: 数据采集、数据存储、数据处理和数据展现,当然处理的数据也提供做分析和挖掘 。
大数据在 08 年的时候还没有很多人提及,但是随着互联网的快速发展,技术的变革,大数据越来越流行,现在也是逢技术论坛,必谈大数据。
大数据同传统 BI 比较,多了一个专门的数据采集阶段,主要是因为数据种类多,数量大,从结构化的数据到非结构化的数据。但是其存储、处理及可视化的思想等都和传统 BI 如出一辙。
总结一下,大数据是从 BI 中发展来的,但现在 BI 也借助着互联网和大数据的快速发展,有了第二春,因为无论数据方面,还是技术方面,大数据都给 BI 提供了翔实的基础。
以上是抛砖引玉的给大家介绍一下 BI 和大数据,具体的我就不展开了,有兴趣的同学可以自己去多了解一下。下面我来介绍一下我们卷皮的 BI 体系。
卷皮的 BI

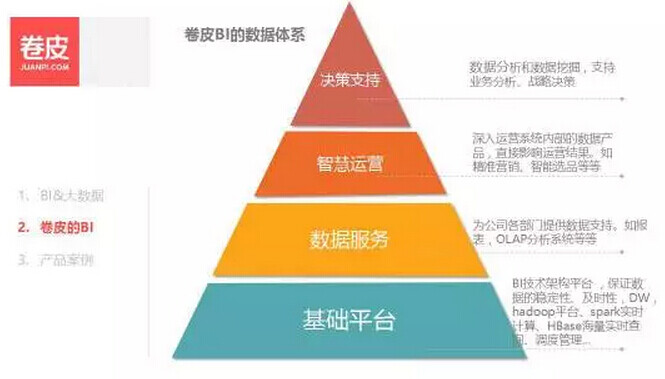
首先介绍一下我们卷皮 BI 的数据体系,分为四层:
第一层是基础平台层 ,包括 BI 所有的数据的接入,加工等等;
第二层是数据服务层 ,主要给业务部门提供报表和 OLAP 分析系统、给分析师提供自助取数平台等等;
第三层是智慧运营层 ,主要是把数据以数据产品的方式渗透到业务部门的日常工作中,例如精细化的运营,针对不同的区域或者人群进行不同的运营策略;
第四层是决策支持 。当然决策支持可以说是在数据服务层和智慧运营层都在做,因为也是以数据支撑每一个具体的业务决策。但是这里讲的第四层的决策更多是以重大决策为主。举个例子:公司选择区域扩张策略,或者仓库选址,还有新业务模式探索等等方向性的决策。
目前我们 BI 团队处于第三层阶段,正在推进各项智慧运营数据产品的建设。
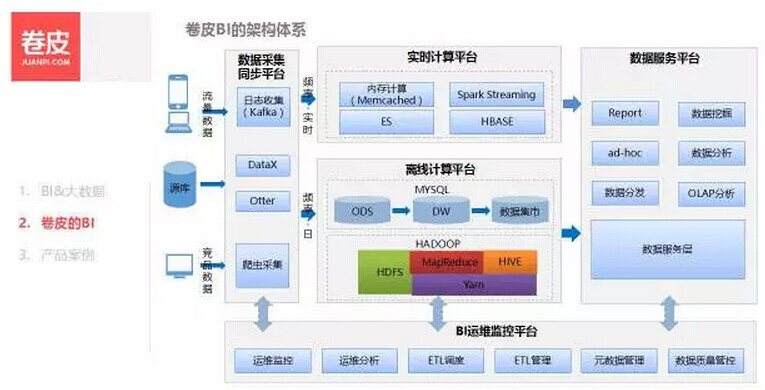
接下来介绍一下我们卷皮 BI 的 架构体系 。我们主要有五大基础平台:
一、数据采集同步平台 :负责接入所有的数据源,用户行为的数据是通过埋点直接生产到 kafka,数据库之间的抽取用的阿里开源的 alt="">
我们 BI 的产品体系主要有两条线,也就是两只脚走路。
先说一下数据服务线的数据产品,这部分产品主要是支撑公司内所有的数据需求,满足不同层次的人看数据的需要。因为这个也是 BI 的基础,基本的数据服务你满足,后面业务部门才能配合一起做其他智慧运营的数据产品。智慧运营线主要想将数据渗透到公司业务部门人员工作的每一个环节中,辅助业务部门人员能够更加好的做好运营工作。具体的应用有精准化营销系统、个性化的推荐系统、鹰眼的反欺诈系统和智能选品系统等。
以上就是我们卷皮 BI 的数据、架构和产品的体系。
卷皮的三个数据产品
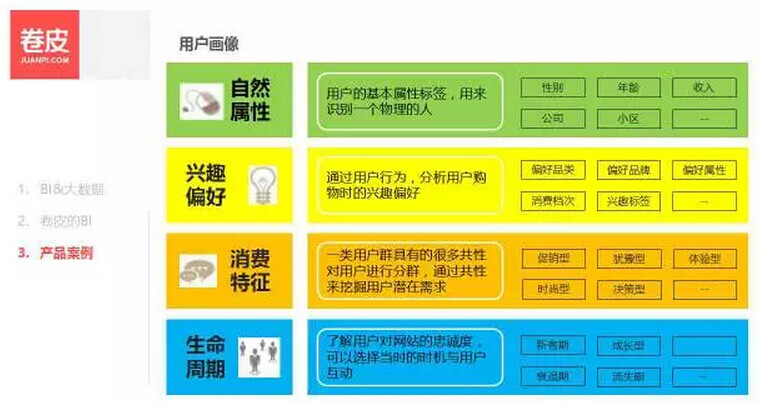
第一是 用户画像 。卷皮是电商平台,我们必须要充分的了解我们的用户,所以卷皮 BI 也基于自有的用户消费数据、行为数据,进行相应的算法模型去挖掘用户的特征,给用户打上各种标签。当然也接入一些外部的数据来验证我们的标签。目前的用户标签, 主要分为四个方面:自然属性,兴趣偏好,消费特征,生命周期。
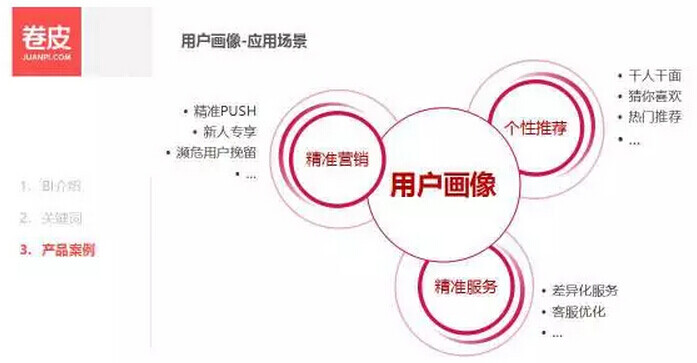
然后基于用户画像,我们团队的精准化小组,就在做以下三个方面的事情:

第二个,就是我们的 鹰眼系统 ,也就是反欺诈系统。目前定位是主要是实时的甄别异常订单。鹰眼系统主要做两方面的事情,识别坏人和识别坏事。目前我们的鹰眼系统一共有 4 个子系统:鹰眼马甲系统、鹰眼售后系统、鹰眼订单甄别、鹰眼诚信系统。
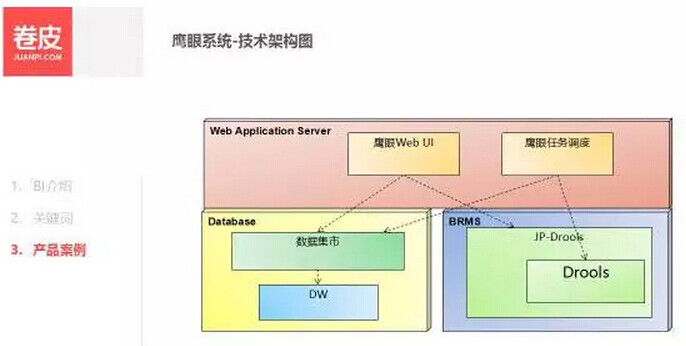
鹰眼系统的核心模块是 BRMS(业务规则管理系统),基于规则引擎 (Drools)。工作人员可通过 Web UI 制定规则,形成规则库,每个规则都有个阈值。实时的数据结合数据集市的历史数据,在规则引擎里面进行判断,如果超出的规则的阈值,则进行相应的操作,如告警,转人工审核等。
鹰眼的 WebUI 是我们自己开发的界面,便于我们的业务运营人员,基于一些现有的指标来配置规则,调整阈值。JP-drools 是在 drools 我们在外面封装了一层,主要是为了做到分布式部署、历史库共享和规则的热部署。
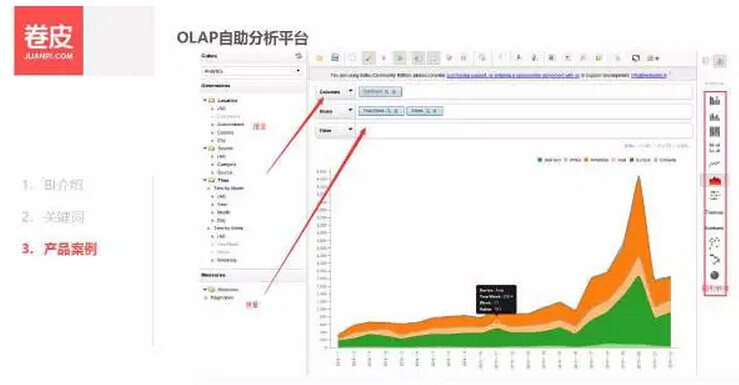
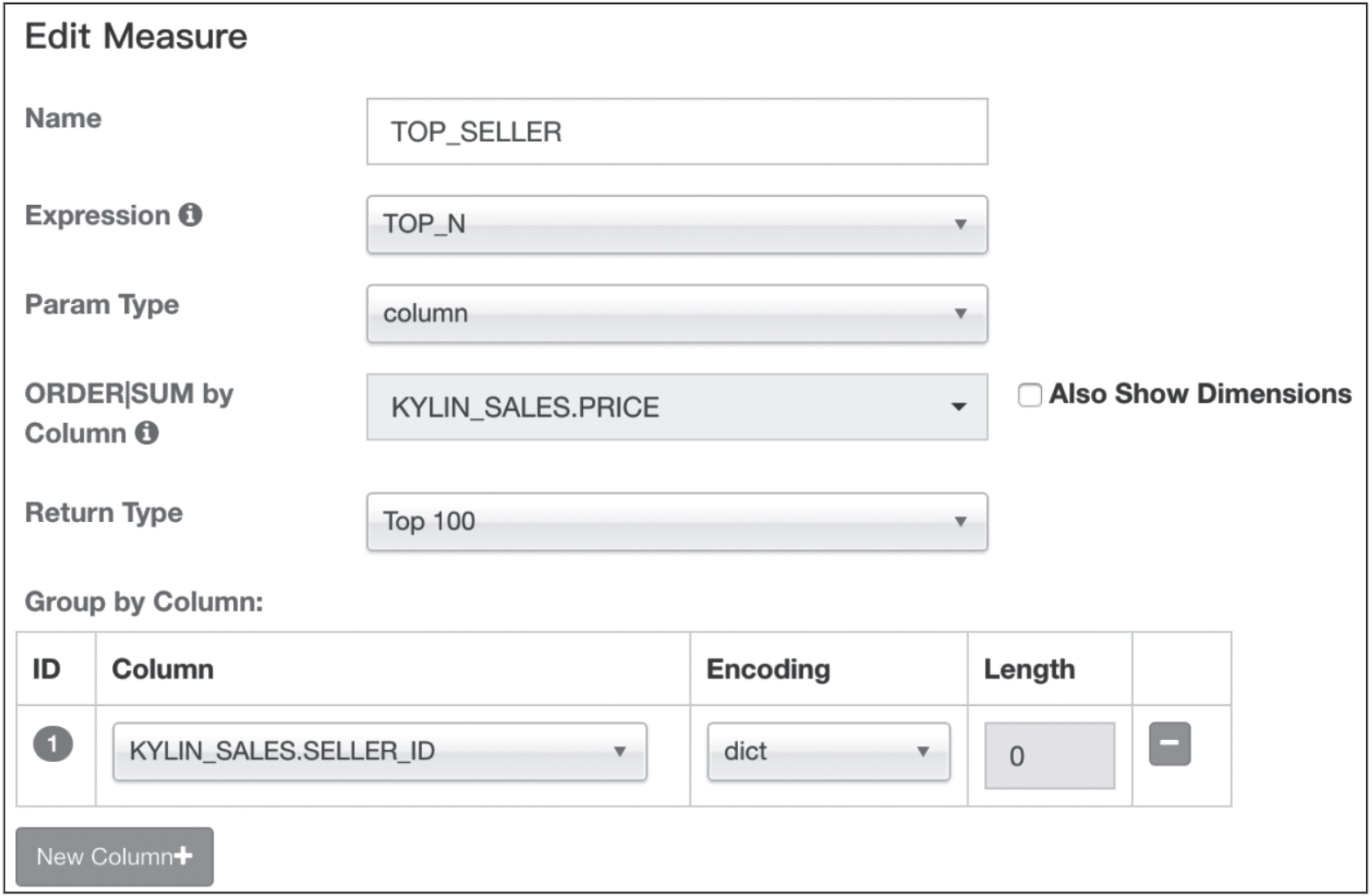
最后这个产品是 OLAP 分析系统 ,图片是一个截图,左边这边有维度和度量,通过拖拽到中间的行或者列进行生成相应的表格,右边可以把表格的数据变成各种图形。业内这种类型的分析工具其实比较多,例如 Microstrategy,Tableau 等。但这些都是商业的,我们更多还是基于开源来做。
我们主要用了如下几个 开源的项目 :
提供了一个多维分析的用户操作界面,可以通过简单拖拉拽的方式迅速生成报表,它的主要工作是根据事先配置好的 schema,将用户的操作转化成 MDX 语句提供给 Mondrian 引擎执行。
是一个 OLAP 分析的引擎,主要工作是根据事先配置好的 schema,将输入的多维分析语句 MDX (Multidimensional Expressions ) 翻译成目标数据库/数据引擎的执行语言(比如 SQL)。
是一个分布式 SQL 查询引擎, 它被设计为用来专门进行高速、实时的数据分析。它支持标准的 ANSI SQL,包括复杂查询、聚合(aggregation)、连接(join)和窗口函数(window functions)。
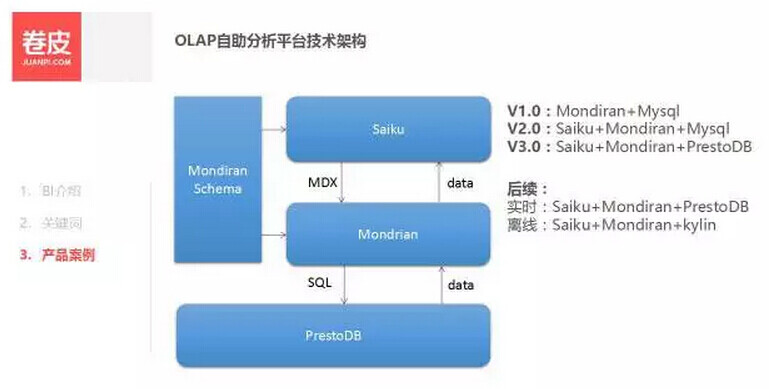
当前这个架构是我们第三个版本的架构。
第一个版本我们是直接用的 Mondrian+Mysql,但是我们发现 Mondrian 的界面太丑了,所以在第二版加入了 Saiku。但是随着业务数据量的增加,Mysql 的查询性能很快就到瓶颈了,所以在第三个版本用 Presto 替代了 Mysql。
在这套架构里面 Saiku 提供了界面的支持,Mondrain 提供了 schema 到 MDX 的转换,并构建 SQL 语句,向 Prestodb 查询数据,Prestodb 执行查询任务,返回其结果,Saiku 显示结果,输出报表。整个 OLAP 系统我们需要关注 Saiku 的二次开发,Mondrain schema.xml 生成及其读取数据和维表方面的优化。
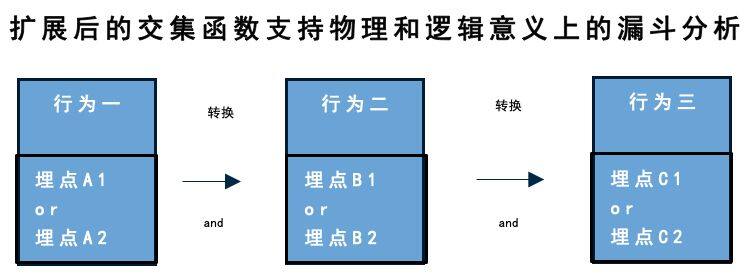
但是当前这个架构目前也逐渐遇到瓶颈,对于像具体到每一个用户成单路径的数据的分析时候查询还是需要比较久的时间,所以我们现在依然在调整,希望把 kylin 加入进来。
kylin 是 apache 软件基金会的顶级项目,一个开源的分布式多维分析工具。Kylin 通过预计算所有合理的维度组合下各个指标的值并把计算结果存储到 HBASE 中的方式,大大提高分布式多维分析的查询效率。Kylin 接收 sql 查询语句作为输入,以查询结果作为输出。对于可以离线分析的业务数据,可以用 kylin 的框架,而对于实时分析的业务数据还是可以用来 Presto 支持。
以上就是我们卷皮 BI 的一些经验的分享。最后送给大家一句话: 数据本身不是最终价值,带有分析的数据,渗透到业务中,影响到决策才产生价值 。
Q1:查询 HBase 中的数据有没有用什么 SQL 引擎呢?有的话用的是什么 SQL 查询引擎?
Q2:hadoop 平台的部署是通过? ambari 这些吗?
Q3:老师好,能否大概讲解一下怎么根据用户画像做推荐,这里面用到什么技术点。
Q4:我们现在 olap 目前正在使用 apache kylin,saiku 和 kykin 结合怎么样,有过调研没?
Q5:BI 挖掘的用户画像和鹰眼系统,有什么离线指标来评价相关的数据质量?
Q6:数据 meta 管理是怎么做的?
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至editors@cn.infoq.com。也欢迎大家通过新浪微博(,@丁晓昀),微信(微信号:InfoQChina)关注我们。