自 2017 年下半年开展实时计算业务以来,我们数据智能部基于 Spark Streaming 搭建了一系列相关系统用于实时数据处理,构建了公司日志数据实时处理流>
在使用 Spark Streaming 构建实时计算平台的过程中,我们也遇到了一系列问题,本文将从以下四个方面( 技术选型、平台现状、经验总结、未来展望)阐述我们构建实时平台的经历。
技术选型
技术选型会考虑技术成熟度、社区活跃度、行业使用度、后期学习成本与改造成本、与现有技术栈整合成本、后续集群维护成本等各项因素。
目前行业内实时计算领域可供选择的处理引擎包括:Storm/JStorm、Spark Streaming、Flink 等。公司内有专门的 SRE 团队维护了一套稳定的 Hadoop 集群用于处理数据任务,为了降低后期单独维护成本,我们考虑选择一款可以 On Yarn 运行的实时处理引擎,另外长期来看,对于实时计算和离线计算引擎要实现统一、结合。
目前行业内以及团队内技术栈,综合各种选型因素,我们最终选择 Spark Streaming 来构建实时计算平台。
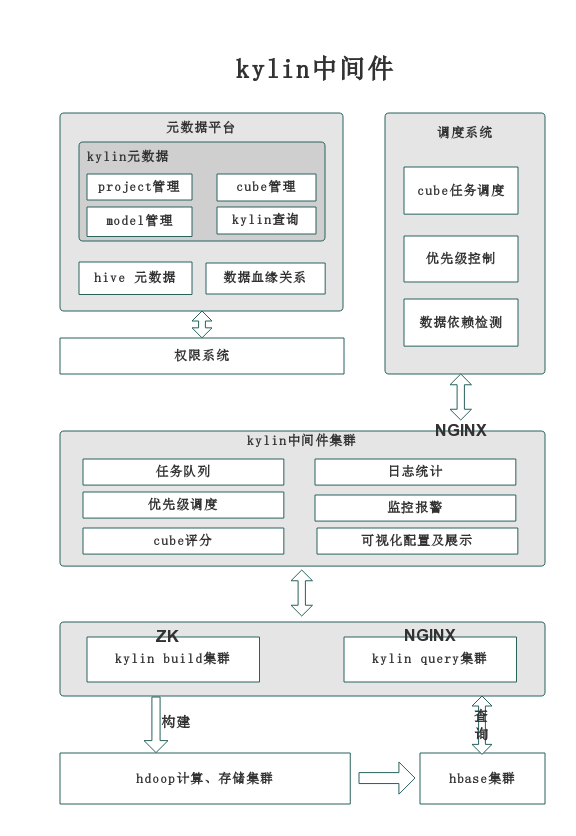
平台现状
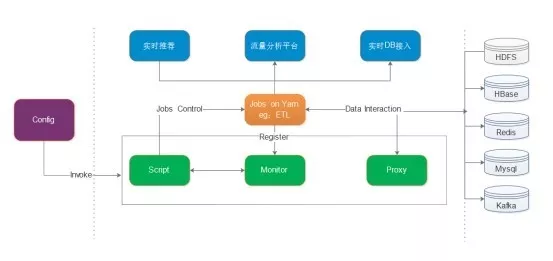
下面对上图的内容做以下介绍:
经验总结
hadoop2.7.3
spark 客户端:spark-1.6.2-bin-hadoop2.6.tgz
kafka 集群:0.9.0.1 和 0.10.2 两套集群
Spark Streaming Direct Approach
问题一:各个组件版本配合
问题二:Exactly Once 语义保证
1)实时计算领域比较常见的词之一:Exactly Once 语义的保证需要从数据源、数据处理、数据存储三个维度实现,对于数据存储来说,大多数存储系统支持幂等操作,比如:HDFS、HBase、Redis、ES 等;MySQL 等关系型存储系统支持事务保证,所以,对于 Exactly Once 语义的保证,更多的精力放在数据处理这个过程;
2)Spark Streaming 确切来说并不是真正意义上的实时计算引擎,它更偏向于微批处理系统,不同于 Storm 单条日志 ACK 机制,Spark Streaming 每个可用时间内提供给我们的是一批数据,我们需要自行实现 Exactly Once 语义保证;
3)Spark 自带的 Checkpoint 机制经过测试,难以保证 Exactly Once 语义,会出现数据重复或者丢失,具体结果取决于应用失败的瞬间,Spark Streaming 当前的处理状态(是否已经处理完最后一批次数据、是否存在等待队列等);应用失败后,基于 Checkpoint 恢复时不仅耗时较长,同时由于代码逻辑变更,从 Checkpoint 恢复会导致诸如反序列化失败等情况,所以难以依赖 Checkpoint 机制实现 Exactly Once 语义
4)对此,我们对于每个批次待处理的日志获取其 untilOffsets,并在当前批次成功处理完成后保存在 zk 中;应用重启后将 zk 中的 offsets 与 Kafka brokers 中的 offsets 进行相关合并逻辑后作为 fromOffsets 传入,从 fromOffsets 处开始消费 Kafka 日志,我们来分析下这样做会有什么问题?
当批次数据处理失败时,untilOffsets 未保存,下次启动后,将会有数据重复,针对这种情况,对于下游系统是 kv 类型且支持幂等操作的话,那么不用做单独处理;否则我们需要在启动后的第一批次需要进行本批次的防重处理,基于单条日志产生一个 uuid 即可;
5)当我们进行每个批次的 offsets 进行保存时要注意在 Driver 端进行,由于每个时间批次都会产生对应的 KafkaRDD 对象,所以对于每个批次产生的 offsets 我们需要按照时间维度进行保存,等待后续处理逻辑结束后,按照时间维度查询出对应的 offsets 即可,当然也可以采用队列的方式,按照先后次序进行 offsets 存取。
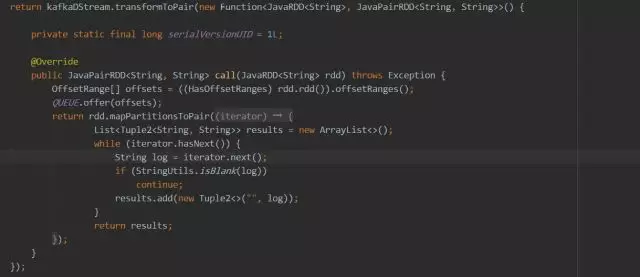

问题三:优雅关闭
spark.streaming.stopGracefullyOnShutdown 选项设置为 true,然后 kill -SIGTERM 即可,但是寻找 AM-PID 的过程比较麻烦,因此我们采用下面的方式实现停止,基于下面的原理,也可以方便的提供 stop 脚本,便于服务封装:
应用启动后设置外部标记,并启动后台线程定期检测标记位,标记位变更后,调用 ssc 上下文,优雅关闭即可。
问题四:Kafka 大数据量调优
目前在处理的一个 topic,每秒有 5 万+的写入,当然,这个量不算多,问题是:当应用由于各种其它因素需要暂停消费时,下一次再次启动后就会有大量积压消息需要进行处理,此时为了保证应用能够正常处理积压数据,需要进行相关调优。
另外对于某个时刻,某个 topic 写入量突增时,会导致整个 kafka 集群进行 topic 分区的 leader 切换,而此时 Streaming 程序也会受到影响。
所以针对以上问题我们进行了如下调优:
1.spark.streaming.concurrentJobs=10:提高 Job 并发数,读过源码的话会发现,这个参数其实是指定了一个线程池的核心线程数而已,没有指定时,默认为 1。
2.spark.streaming.kafka.maxRatePerPartition=2000:设置每秒每个分区最大获取日志数,控制处理数据量,保证数据均匀处理。
3.spark.streaming.kafka.maxRetries=50:获取 topic 分区 leaders 及其最新 offsets 时,调大重试次数。
4.在应用级别配置重试
spark.yarn.maxAppAttempts=5
spark.yarn.am.attemptFailuresValidityInterval=1h
此处需要 【注意】 :
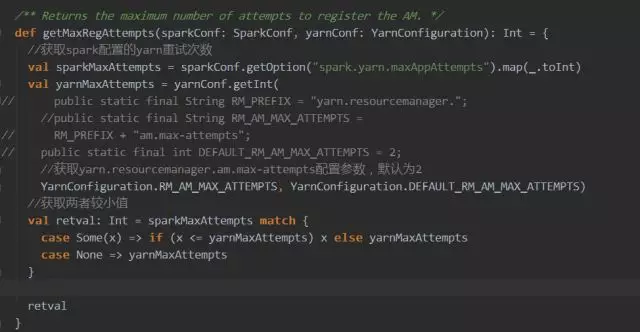
spark.yarn.maxAppAttempts 值不能超过 hadoop 集群中 yarn.resourcemanager.am.max-attempts 的值,原因可参照下面的源码或者官网配置。
未来展望
目前的实时计算平台与行业内阿里、腾讯等大型互联网公司相比,存在一定差距和不足。
后续我们将投入精力在以下方面进行设计和完善:
作者介绍:
张智源,数据智能部,16 年 10 月加入链家,先后负责设计实现大数据权限平台、实时计算平台,专注于大数据生态圈技术研究。
原文链接: