

想要先睹为快的读者,可直接克隆该项目的 GitHub 代码库。代码库中的文档正在持续改进中,并完全可用。代码库地址为:mvallim/kubernetes-under-the-hood
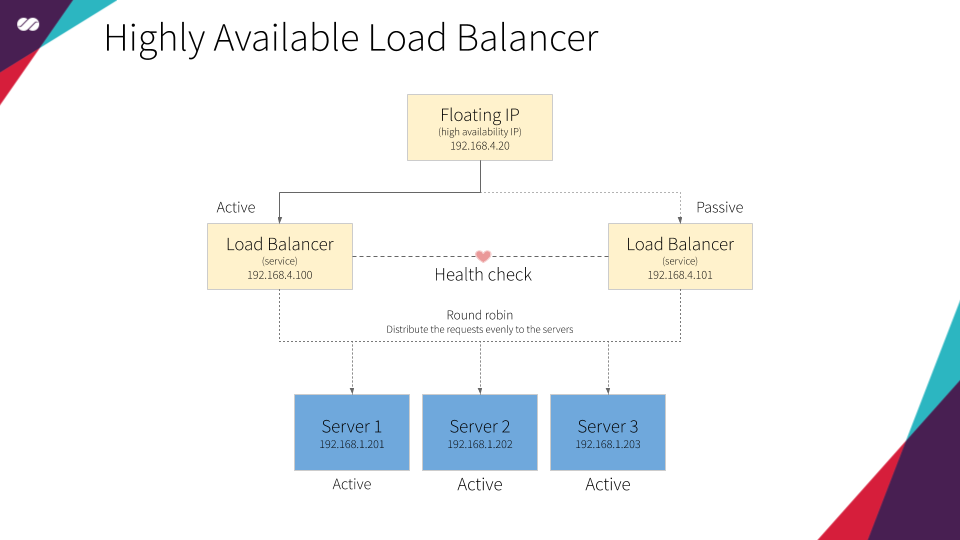
引用自:正如前文中提及,我们将使用 HAProxy 创建用于 Kubernetes API 的负载均衡器(Load Balancer)。
考虑如下应用场景:只有一个 HAProxy 实例提供负载均衡的情况将会如何?这里我们引出架构单点故障(,Single Point of Failure)的概念。即无论由于何种原因导致单个 HAProxy 失败,就会完全失去对 Kubernetes API 的访问。当然,考虑到该组件在架构中的重要地位,我们应尽量避免这种情况的发生。
正如前文所述,为解决上述问题,需将 HAProxy 添加到支持浮动 IP 并配置至少两个 HAProxy 服务的高可用集群中。
总而言之,我们将构建支持负载均衡的高可用集群。
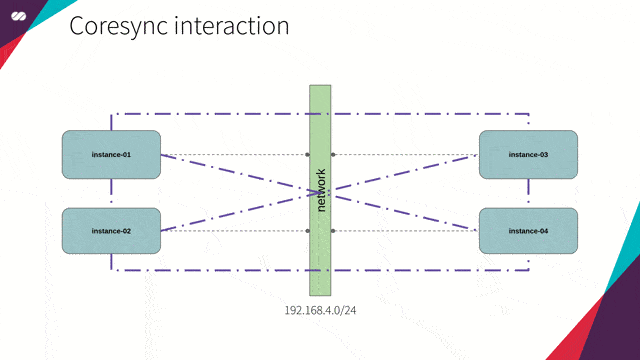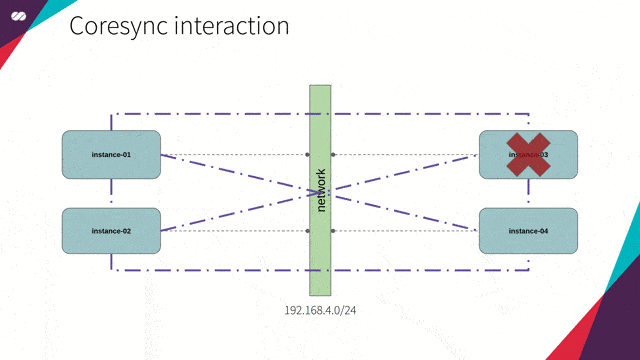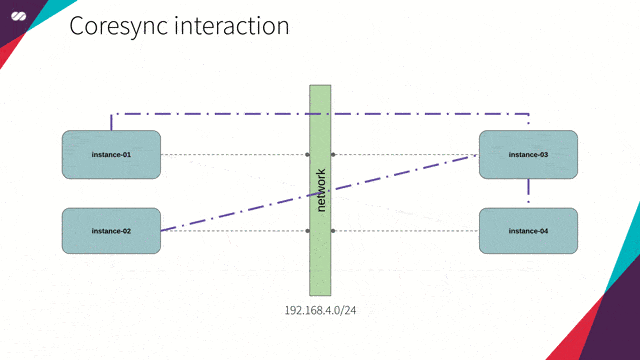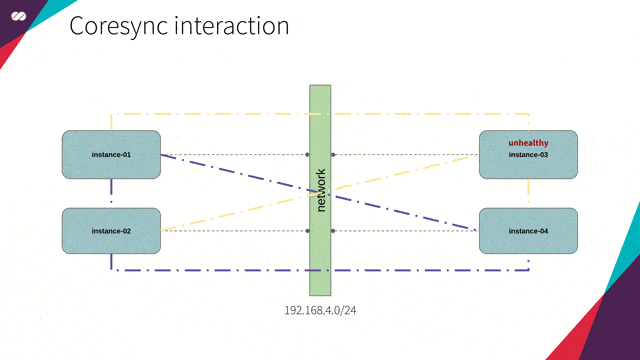
引用自:主要目的包括两方面:维持集群的状态(即掌握节点加入和离开集群的时间),以及将消息分发给集群中所有成员。
维持集群状态
节点加入集群
要掌握集群的更新状态,集群的所有节点都应该安装并统一配置 Corosync。一个安装了 Corosync 的集群节点,在每次启动时会产生如下会话:

节点离开集群
一个节点在加入该“独一无二俱乐部”之后,它需要了解集群中所有节点。同样,集群中其它节点也会按对待先前加入的节点一样,以同样方式了解新节点。
为了掌握一个节点何时离开集群,Corosync 会持续监控节点成员的健康状况。由此,假设如下场景:
引用自:《LINUX Journal》指出,“权威的 Linux 平台开源高可用性堆栈,是构建在 Pacemaker 集群资源管理器之上的。”
在集群中,Pacemaker 创建并配置可由 Corosync 建立和管理的资源。
Pacemaker 的主要目的是支持集群中的负载均衡器高可用。为此,我们使用 Pacemaker 定义浮动 IP 和 HAProxy 资源。上述资源设置在由 Corosync 集群管理的集群中。
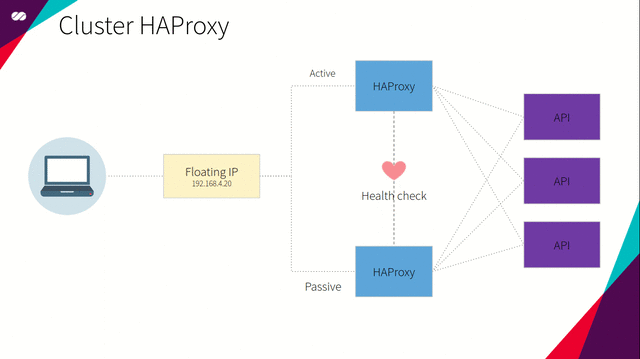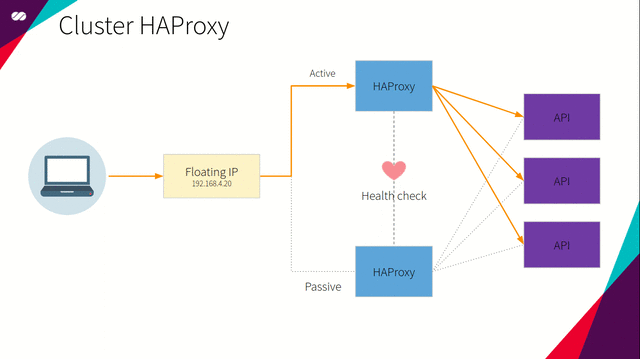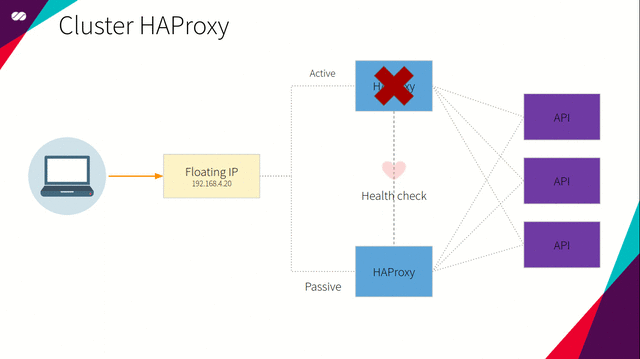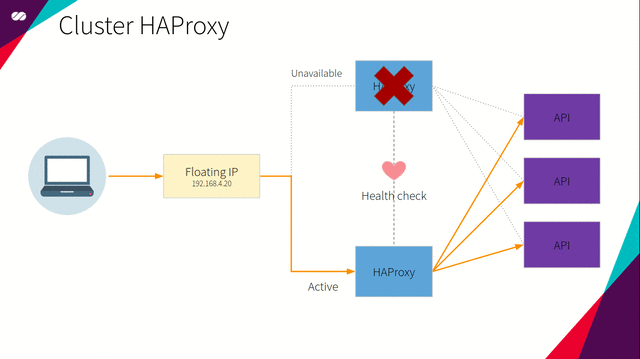
Pacemaker 使用了声明式方法。这意味着我们在创建配置文件中,需要指定每个节点上存在哪些资源,以及这些资源间的相关性。对我们而言,相关性定义了浮动 IP 和 HAProxy 资源间的相互依赖关系。相关性意味着资源间相互依赖。对于特定节点,如果 HAProxy 处于活动(Active)状态,那么在同一节点中浮动 IP 也应保持活动状态,反之亦然。
简而言之,如果某个节点处于活动状态,我们希望为该节点指派浮动 IP 和 HAProxy,并在节点上得到执行。同时,所有其它节点将处于非活动状态,直到该节点或该节点所附加的资源由于某种原因产生失败。一旦上述情况发生,活动节点所指派的资源将“迁移”到非活动节点,或在所有依赖条件得到满足的情况下在非活动节点上启动。这时,所选定的节点将成为活动节点,先前的活动节点转变为非活动状态。过程如下图所示:
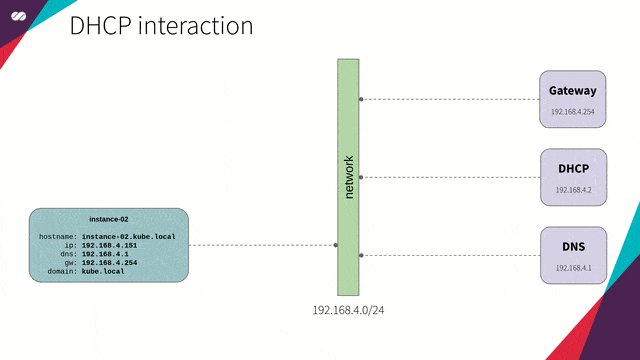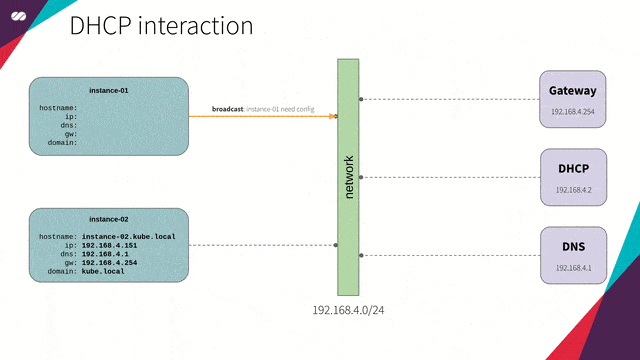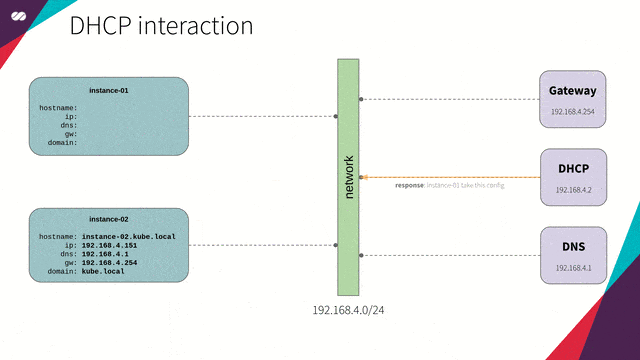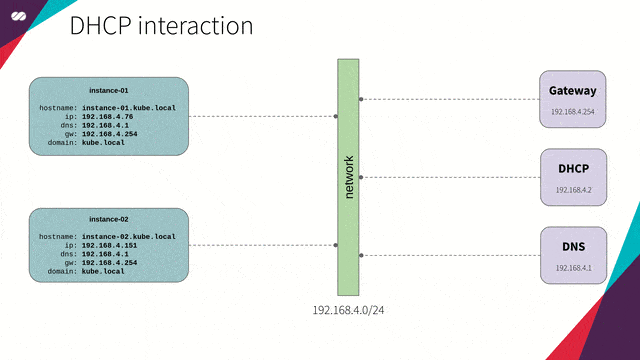
引用自:我们使用 dnsmasq,为主机(节点)提供 DNS 和 DCHP 功能。
DHCP 和 DNS 可同步工作。也就是说,对于每台加入网络的新主机,DHCP 将更新 DNS 服务,并将主机名映射到所提供的 IP 上。这样,我们可以通过名字而非 IP 指定主机,无需操心具体的 IP 地址。
下面给出一个更实际的例子。当我们在云平台(例如 GCP、AWS、Azure 等)上创建一个新实例时,所创建的每个新实例将立刻在内部 DNS 中收到一个 IP、DNS 解析项、路由表项和主机注册项。最终,上述配置将由 DHCP 及 DNS 在后台实现。
VirtualBox
引用自:。
鉴于实际的裸金属服务器不可能直接访问,为模拟数据中心内的机器和网络,我们将使用 VirtualBox 这种开源替代解决方案。
VirtualBox 技术栈支持本系列文章介绍的所有理念。
cloud-init
引用自:用于实例初始化的。它支持实例在启动时自动配置,在数秒内将通用 Linux 镜像转换为经配置后的服务器,快速简单。
在最新 Linux 发行版中提供的 cloud-init 工具,适用于执行服务、用户和软件包的设置。其中,cloud-config 文件格式是脚本最广泛使用的格式。
cloud-config 文件是一种特殊的脚本,设计用于 cloud-init 工具处理。它们通常用于在服务器首次启动时的配置。
下面的 Youtube 视频给出了 cloud-init 运行情况。降低视频速度,可查看运行细节。
引用自:假定一家企业要租用会议中心。会议中心所提供的会议室大小各异,即有适合 Google I/O 和 AWS re:Invent 如此规模大会的会议室,也有适合满足用户任何年度聚会需要的会议规模。
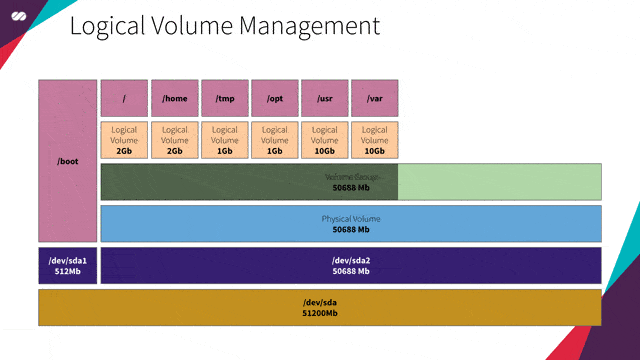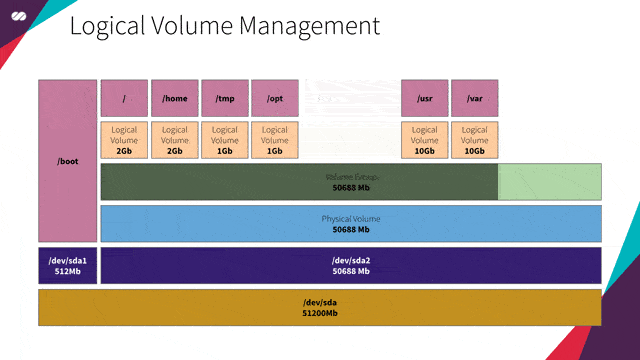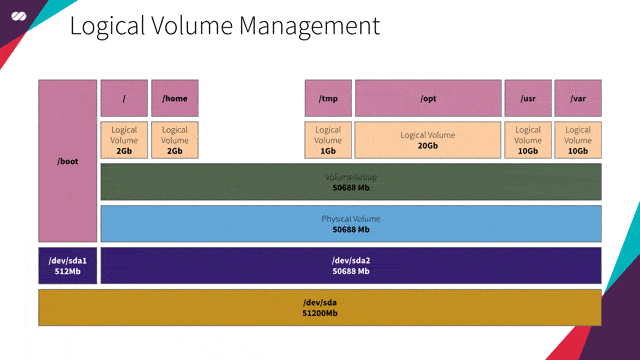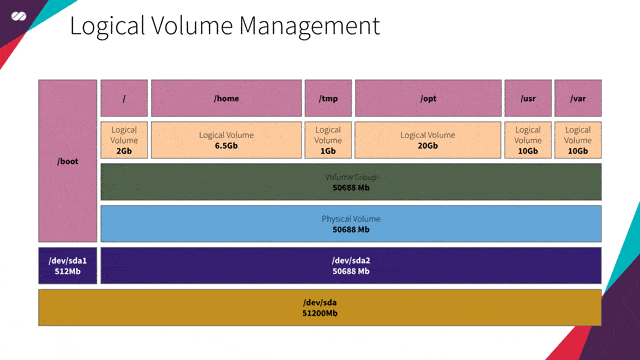
为最大化使用会议室空间的效率,每个场地基本上都是一个没有任何固定空间划分的巨大机库。LVM 配置允许企业将整体空间划分为大小各异的空间。
以 Google I/O 大会为例。会议期间可分配更大的空间用于主题演讲。主题演讲结束之后,可以将空间重新配置为更小的部分,用于大会中其他分会的会场。
这基本上就是 LVM 允许我们对磁盘所进行的操作。LVM 支持我们在无需实现明确服务器用途的情况下配置服务器。我们无需知道服务器将运行哪些服务,也不需要了解这些服务将生成的预期数据量。LVM 还允许我们实时操作和调整卷的大小,类似于上面例子中会议场地空间分配一样。
就我们的特定需求而言,我们要创建一个虚拟机镜像,作为许多其他镜像(例如 Gateway、HAProxy、Kubernetes 主节点或工作节点和 Gluster 等)的基础。不同的服务具有不同的空间需求(在此需分隔的会议空间就是/var、/usr、/tmp、/opt、/etc 等),LVM 将可提供根据需要调整分区卷大小的灵活性,而无需事先操心具体细节。
引用自:上文中已介绍了 Gluster 的作用。
引用自:,最初基于技术开发,但是现在技术栈已成独立。它不仅提供运行容器服务,而且更易于创建、构建、上载和控制镜像版本。
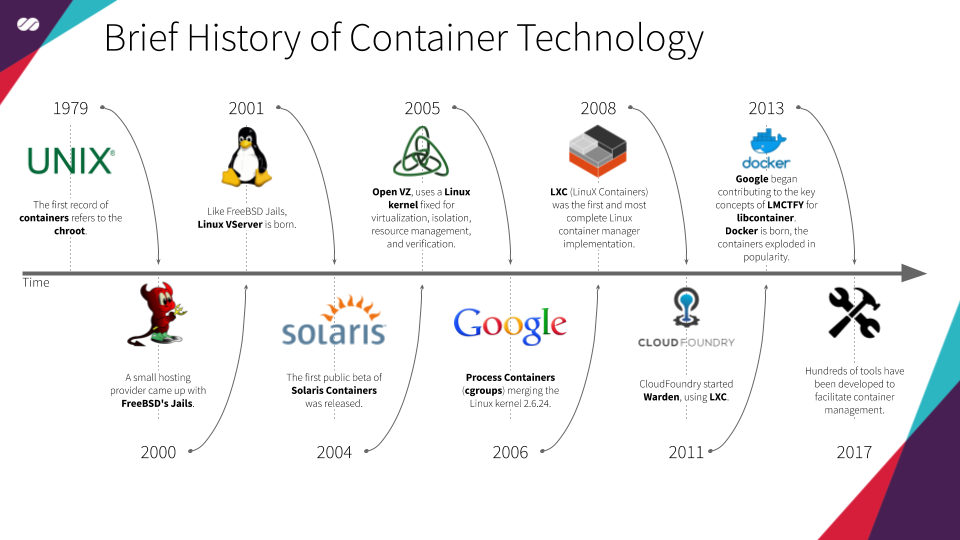
上面给出的容器简史,摘自维基等文献。
Docker 本质上是一种以容器格式打包软件的方法。那么这样做有何意义?这意味着,用户的所有软件及依赖项(例如软件库,配置等)都打包在容器中,这使得应用移植更为轻松,无需操心应用部署环境间可能存在的潜在差异。
该方法的一大优势是,用户可在任何其他环境或新机上启动容器,而不会出现意外错误或其他配置问题。因为用户应用所需的所有内容都打包在同一容器中。通过这种方式,容器实现了可预测、可重复和不可变的管理。
有人可能会提出,通过虚拟化也可以实现同样的目标。该说法并没有问题,二者实际在结果上是相同的。但最大的区别在于,使用容器技术时,用户能更好地利用资源。用户的操作系统资源能得到更好的共享,应用无需占用整个操作系统。为了更好地理解上述理念,可查看下图:
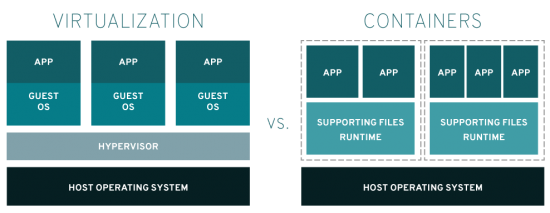
图片来自:尽管上述优势听起来真的很棒,但用户在 Docker 容器上运行应用生态系统时,究竟会发生什么?容器会大大降低系统管理工作的效率、操作繁琐并容易出错。为解决上述问题,Kubernetes 应运而生。Kubernetes 是一种开源容器编排系统,提供应用部署、扩展和管理的自动化,实现容器管理的智能化和整洁化。
Kubernetes
引用自:正如上文所述,Kubernetes 是一种开源容器编排系统,用于自动化应用的部署、扩展和管理,并可实现容器管理的智能化并整洁化。
Kubernetes 的内部机制,将在本系列后续文章中介绍。
引用自:引用自:原文链接:
Kubernetes Journey — Up and running out of the cloud — Technology Stack




