一、背景
HULK 是美团的容器集群管理平台。在 HULK 之前,美团的在线服务大部分部署都是在 VM 上,在此期间,我们遇到了很大的挑战,主要包括以下两点:
因为美团很多业务都具有明显的高低峰特性,大家一般会根据最高峰的流量情况来部署机器资源,然而在业务低峰期的时候,往往用不了那么多的资源。在这种背景下,我们希望打造一个容器集群管理平台来解决上述的痛点问题,于是 HULK 项目就应运而生了。
HULK 平台包含容器以及弹性调度系统,容器可以统一运行环境、提升交付效率,而弹性调度可以提升业务的资源利用率。在漫威里有个叫 HULK 的英雄,在情绪激动的时候会变成“绿巨人”,情绪平稳后则恢复人身,这一点跟我们容器的“弹性伸缩”特性比较相像,故取名为“HULK”。
总的来讲,美团 HULK 的演进可以分为 1.0 和 2.0 两个阶段,如下图所示:
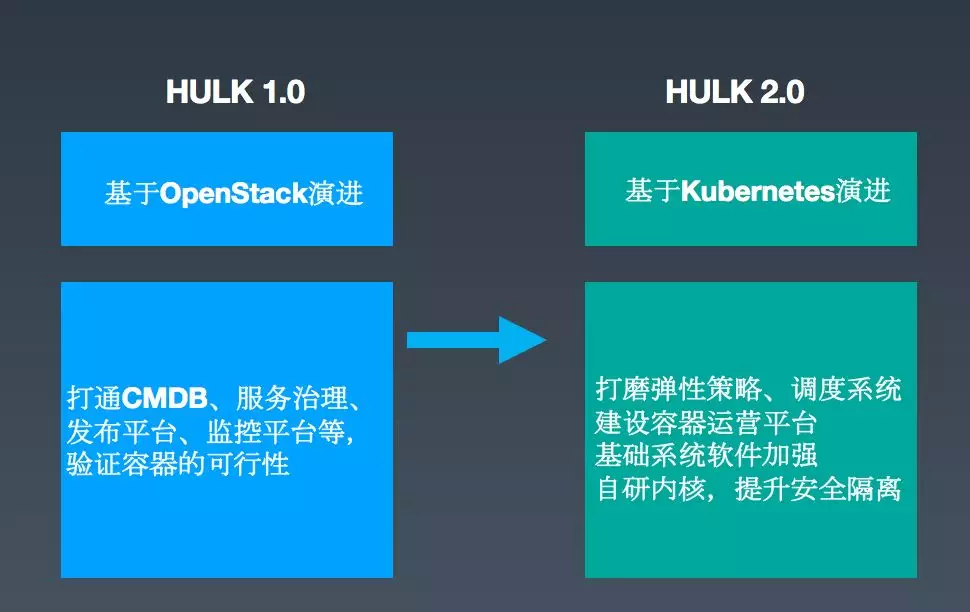
在早期,HULK 1.0 是基于 OpenStack 演进的一个集群调度系统版本。这个阶段工作的重点是将容器和美团的基础设施进行融合,比如打通 CMDB 系统、公司内部的服务治理平台、发布平台以及监控平台等等,并验证容器在生产环境的可行性。2018 年,我们将底层的 OpenStack 升级为容器编排标准Kubernetes,然后把这个版本称之为 HULK 2.0,新版本还针对在 1.0 运营过程中遇到的一些问题,对系统专门进行了优化和打磨,主要包括以下几个方面:
截止发稿时,美团生产环境已经有 1 万个应用在使用容器,生产环境容器数超过 10 万。
二、HULK2.0 集群调度系统总体架构图

上图中,最上层是集群调度系统对接的各个平台,包括服务治理、发布平台、测试部署平台、CMDB 系统、监控平台等,我们将这些系统打通,业务就可以无感知地从 VM 迁移到容器中。其中:
最底层的 HULK Agent 是我们在每个 Node 上的代理程序。此前,在美团技术团队官方博客上,我们也分享过底层的镜像管理和容器运行时相关内容,参见《美团容器技术研发实践》一文。而本文将重点阐述容器编排(调度系统)和容器弹性(弹性伸缩平台),以及团队遇到的一些问题以及对应的解决方案,希望对大家能有所启发。
三、调度系统痛点、解法
3.1 业务扩缩容异常
痛点 :集群运维人员排查成本较高。
为了解决这个问题,我们可以先看一下调度系统的简化版架构,如下图所示:
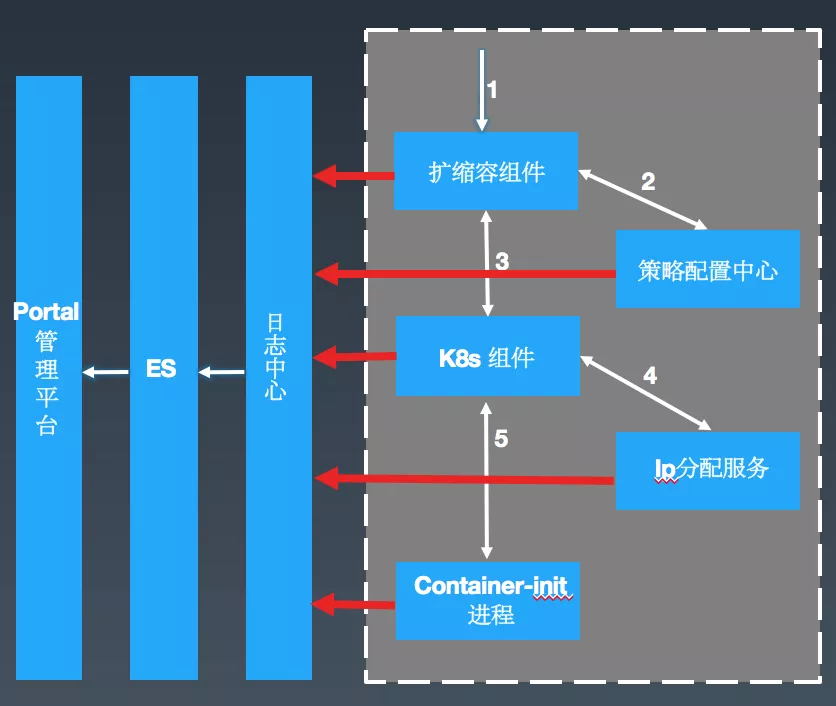
可以看到,一次扩缩容请求基本上会经历以下这些流程:
a. 用户或者上层系统发起扩缩容请求。
b. 扩缩容组件从策略配置中心获取对应服务的配置信息。
c. 将对应的配置信息提交到美团自研的一个 API 服务(扩展的 K8s 组件),然后 K8s 各 Master 组件就按照原生的工作流程开始 Work。
d. 当某个实例调度到具体 Node 上的时候,开始通过 IP 分配服务获取对应的 Hostname 和 IP。
e. Container-init 是一号进程,在容器内部拉起各个 Agent,然后启动应用程序。针对已经标准化接入的应用,会自动进行服务注册,从而承载流量。
而这些模块是由美团内部不同同学分别进行维护,每次遇到问题时,就需要多个同学分别核对日志信息。可想而知,这种排查问题的方式的成本会有多高。
解法 :类似于分布式调用链中的 TraceId,每次扩缩容会生成一个 TaskId,我们在关键链路上进行打点的同时带上 TaskId,并按照约定的格式统一接入到美团点评日志中心,然后在可视化平台 HULK Portal 进行展示。
落地效果 :
3.2 业务定制化需求
痛点 :每次业务的特殊配置都可能变更核心链路代码,导致整体系统的灵活性不够。
具体业务场景如下:
解法 :建设一体化的调度策略配置中心,通过调度策略配置中心,可定制化调度规则。
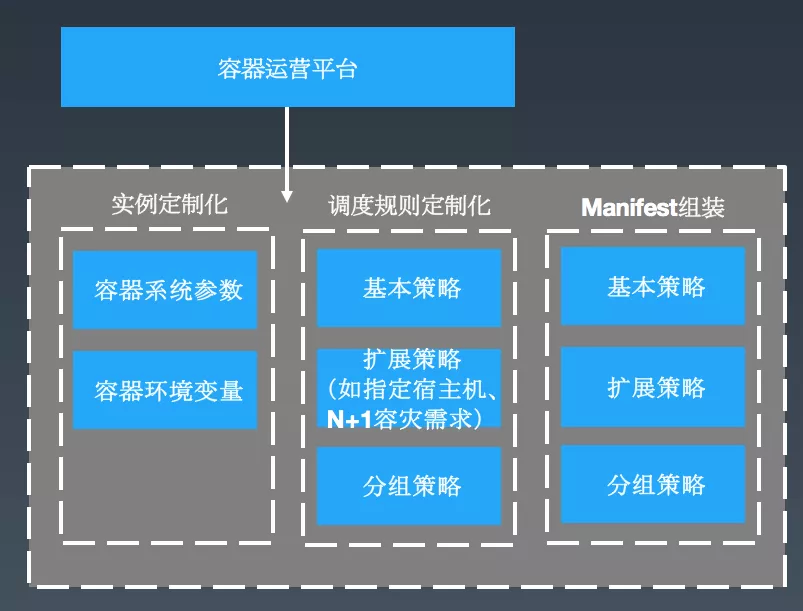
在策略配置中心,我们会将这些策略进行 Manifest 组装,然后转换成 Kubernetes 可识别的 YAML 文件。
落地效果 :实现了平台自动化配置,运维人员得到解放。
3.3 调度策略优化
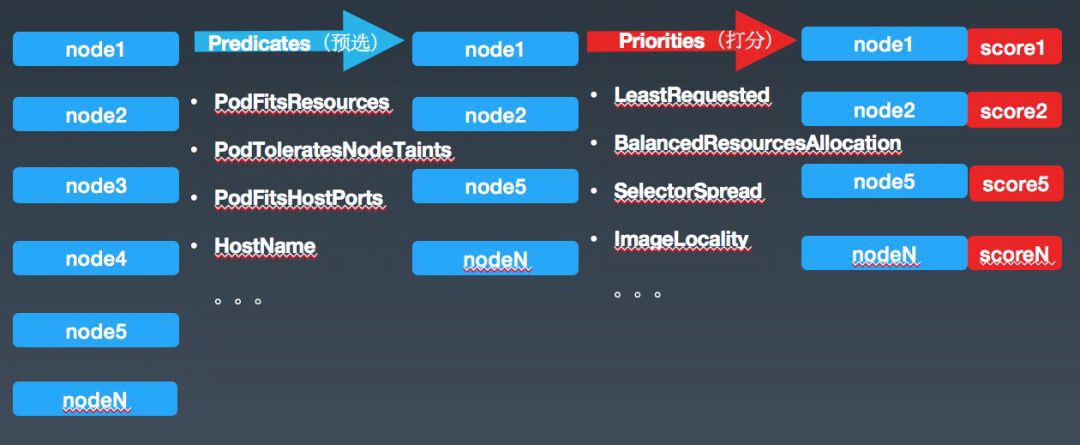
接下来,介绍一下 Kubernetes 调度器 Scheduler 的默认行为:它启动之后,会一直监听 ApiServer,通过 ApiServer 去查看未 Bind 的 Pod 列表,然后根据特定的算法和策略选出一个合适的 Node,并进行 Bind 操作。具体的调度策略分为两个阶段:Predicates 预选阶段和 Priorities 打分阶段。
Predicates 预选阶段(一堆的预选条件):PodFitsResources 检查是否有足够的资源(比如 CPU、内存)来满足一个 Pod 的运行需求,如果不满足,就直接过滤掉这个 Node。Priorities 打分阶段(一堆的优先级函数):
将以上优先级函数算出来的值加权平均算出来一个得分(0-10),分数越高,节点越优。
痛点一 :当集群达到 3000 台规模的时候,一次 Pod 调度耗时 5s 左右(K8s 1.6 版本)。如果在预选阶段,当前 Node 不符合过滤条件,依然会判断后续的过滤条件是否符合。假设有上万台 Node 节点,这种判断逻辑便会浪费较多时间,造成调度器的性能下降。
解法 :当前 Node 中,如果遇到一个预选条件不满足(比较像是短路径原则),就将这个 Node 过滤掉,大大减少了计算量,调度性能也得到大幅提升。
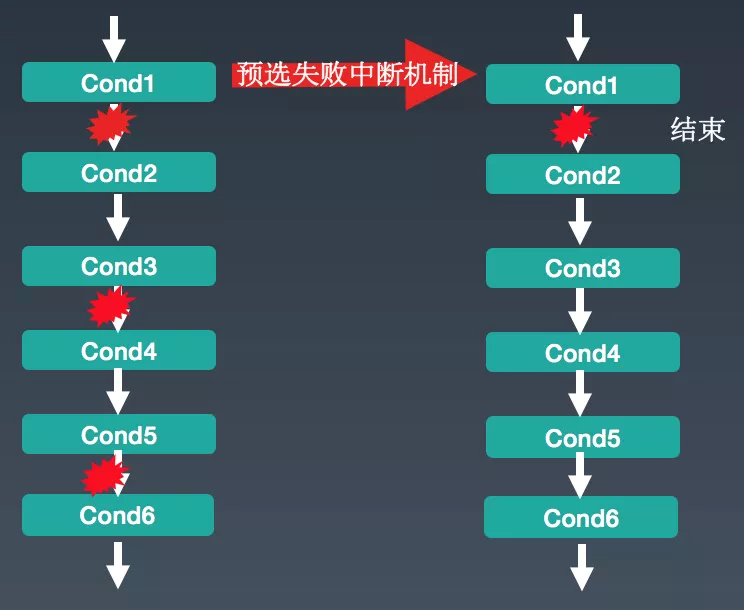
成效 :生产环境验证,提升了 40%的性能。这个方案目前已经成为社区 1.10 版本默认的调度策略,技术细节可以参考GitHub上的PR。
痛点二 :资源利用率最大化和服务 SLA 保障之间的权衡。
解法 :我们基于服务的行为数据构建了服务画像系统,下图是我们针对某个应用进行服务画像后的树图展现。
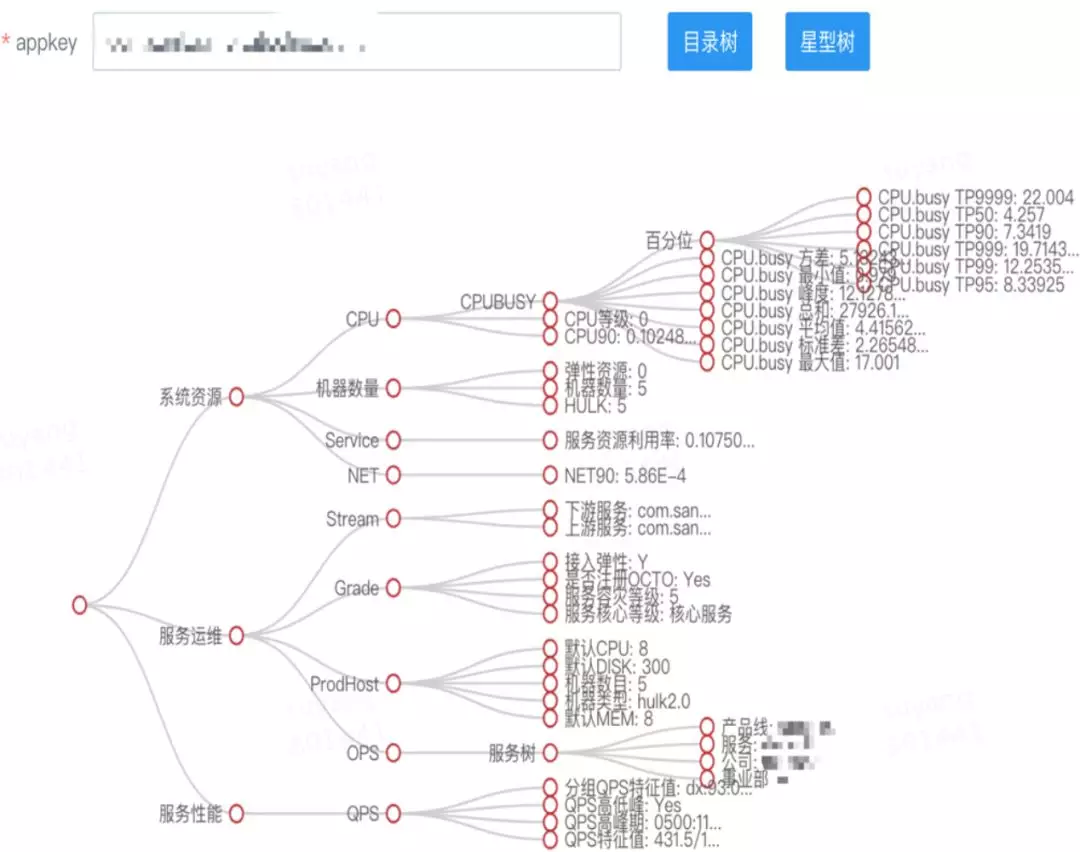
调度前 :可以将有调用关系的 Pod 设置亲和性,竞争相同资源的 Pod 设置反亲和性,相同宿主机上最多包含 N 个核心应用。
调度后 :经过上述规则调度后,在宿主机上如果依然出现了资源竞争,优先保障高优先级应用的 SLA。
3.4 重编排问题
痛点 :
(1)容器重启/迁移场景:
(2)驱逐场景:Kubelet 会自动杀死一些违例容器,但有可能是非常核心的业务。
解法 :
(1)容器重启/迁移场景:
(2)关闭原生的驱逐策略,通过外部组件来做决策。
四、弹性伸缩平台痛点、解法
弹性伸缩平台整体架构图如下:
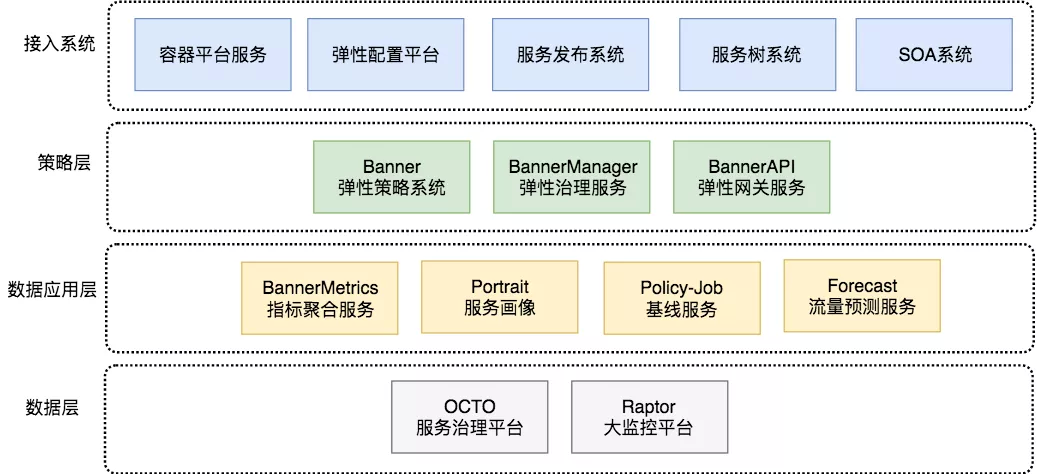
注:Raptor 是美团点评内部的大监控平台,整合了、等监控产品。
在弹性伸缩平台演进的过程中,我们主要遇到了以下 5 个问题。
4.1 多策略决策不一致
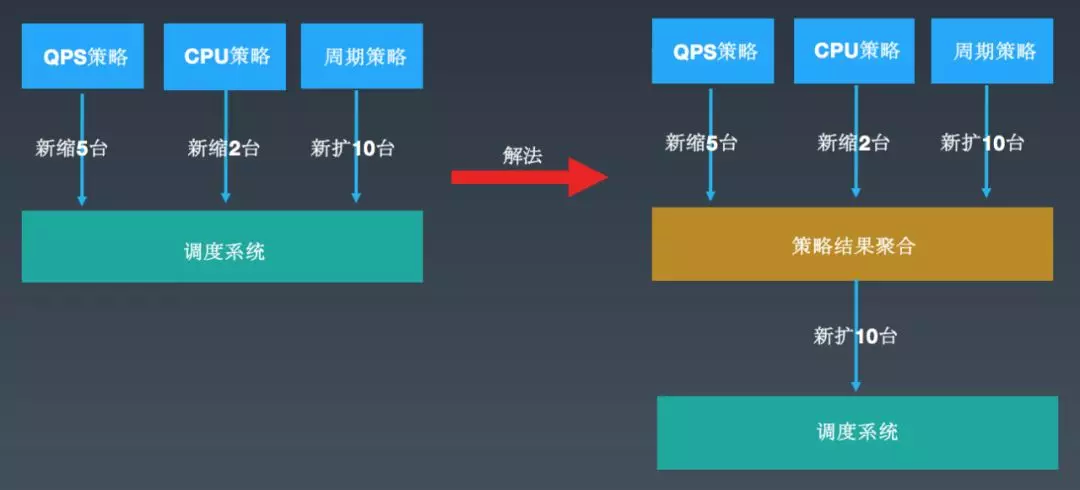
如上图所示,一个业务配置了 2 条监控策略和 1 条周期策略:
早期的设计是各条策略独自决策,扩容顺序有可能是:缩 5 台、缩 2 台、扩 10 台;也有可能是:扩 10 台、缩 5 台、缩 2 台,就会造成一些无效的扩缩行为。
解法 :增加一个聚合层(或者把它称之为策略协商层),提供一些聚合策略:默认策略(多扩少缩)和权重策略(权重高的来决策扩缩行为),减少了大量的无效扩缩现象。
4.2 扩缩不幂等
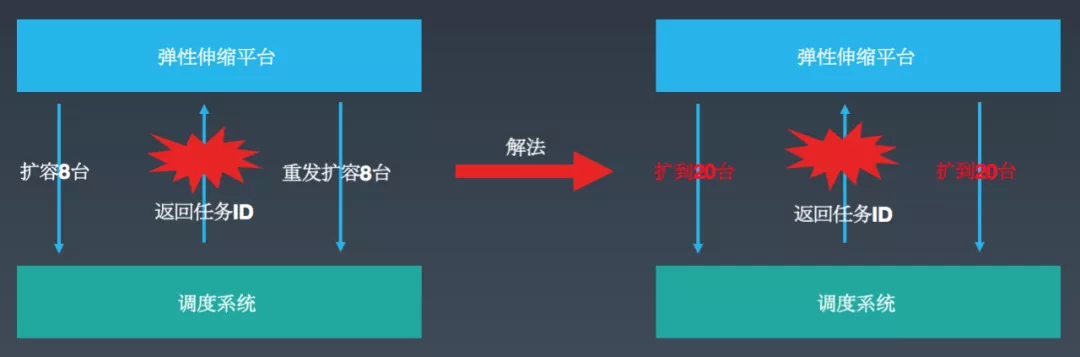
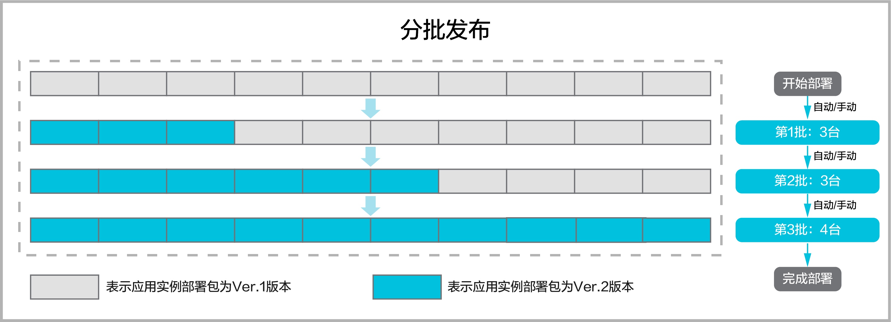
如上图所示,聚合层发起具体扩缩容的时候,因之前采用的是增量扩容方式,在一些场景下会出现频繁扩缩现象。比如,原先 12 台,这个时候弹性伸缩平台告诉调度系统要扩容 8 台,在返回 TaskId 的过程中超时或保存 TaskId 失败了,这个时候弹性伸缩平台会继续发起扩容 8 台的操作,最后导致服务下有 28 台实例(不幂等)。
解法 :采用按目标扩容方式,直接告诉对端,希望能扩容到 20 台,避免了短时间内的频繁扩缩容现象。
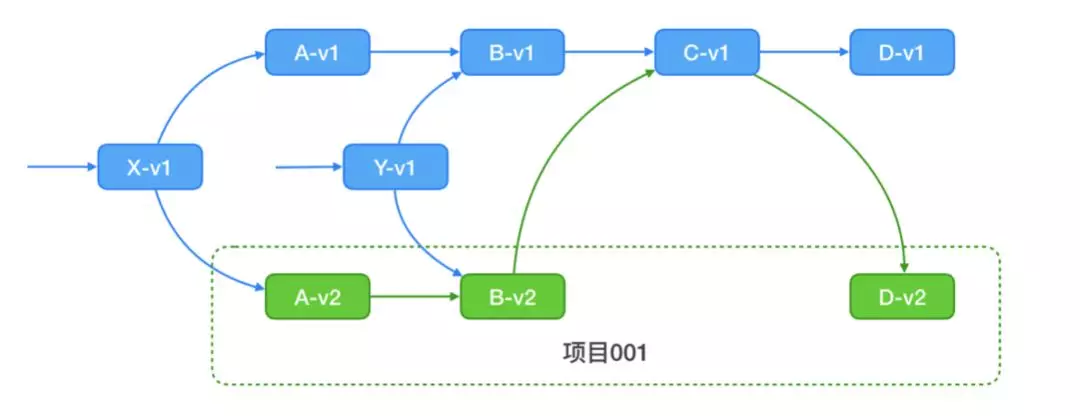
4.3 线上代码多版本
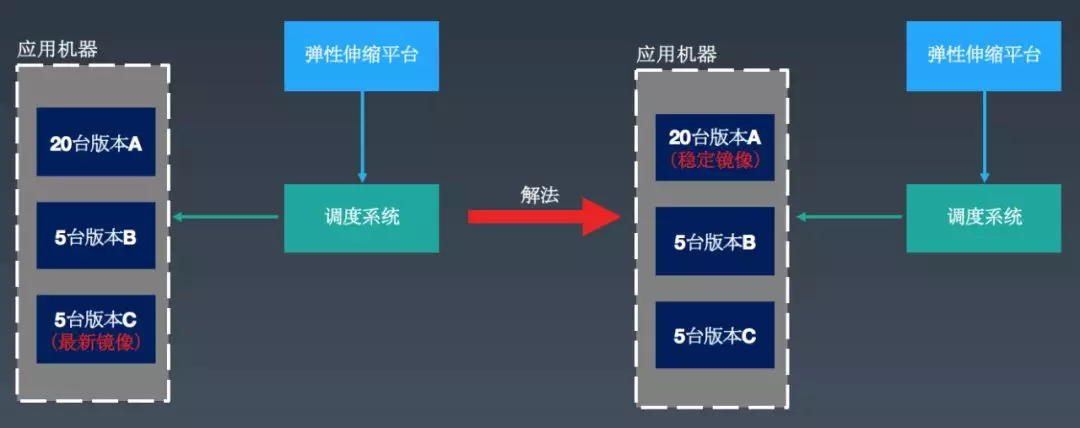
如上图所示,一个业务线上有 30 台机器,存在 3 个版本(A、B、C)。之前我们弹性扩容的做法是采用业务构建的最新镜像进行扩容,但在实际生产环境运行过程中却遇到问题,比如一些业务构建的最新镜像是用来做小流量测试的,本身的稳定性没有保障,高峰期扩容的时候会提升这个版本在线上机器中的比例,低峰期的时候又把之前稳定版本给缩容了,经过一段时间的频繁扩缩之后,最后线上遗留的实例可能都存在问题。
解法 :基于约定优于配置原则,我们采用业务的稳定镜像(采用灰度发布流程将线上所有实例均覆盖过一遍的镜像,会自动标记为稳定镜像)进行扩容,这样就比较好地解决了这个问题。
4.4 资源保障问题
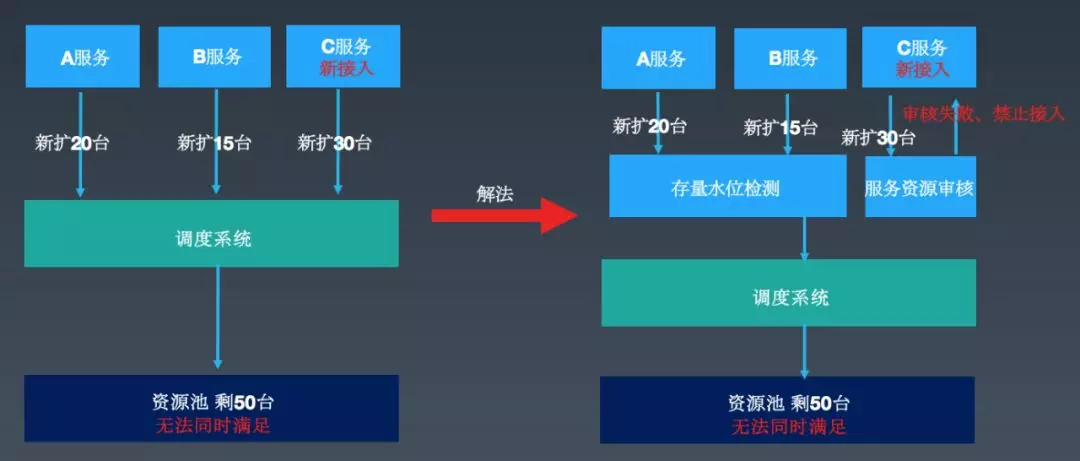
如上图所示,存量中有 2 个服务,一个需要扩容 20 台,一个需要扩容 15 台,这个时候如果新接入一个服务,同一时间需要扩容 30 台,但是资源池只剩余 50 台实例了。这个时候就意味着,谁先扩容谁就可以获得资源保障,后发起的请求就无法获得资源保障。
解法 :
(1) 存量资源水位检测 :当存量资源的使用水位超过阈值的时候,比如达到 80%的时候会有报警,告诉我们需要做资源补充操作。
(2) 增量服务弹性资源预估 :如果这个服务通过预判算法评估,接入之后可能会导致存量服务的扩容得不到保障,则拒绝或者补充资源后,再让这个业务接入。
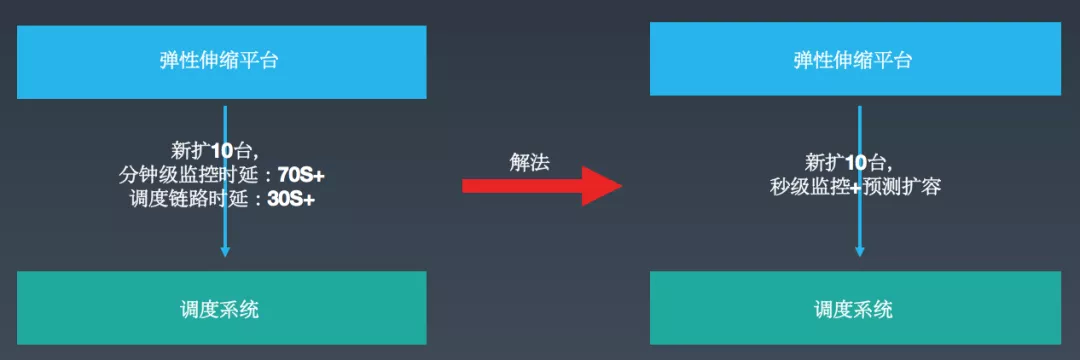
4.5 端到端时效问题
如图所示,我们的分钟级监控时延(比如 1:00:00~1:01:00 的监控数据,大概需要到 1:01:10 后可将采集到的所有数据聚合完成)是 70s+,调度链路时延是 30s+,整体需要上 100s+,在生产环境的业务往往会比较关注扩容时延。
解法 :监控系统这块已经建设秒级监控功能。基于这些做法都属于后验性扩容,存在一定的延迟性,目前我们也在探索基于历史行为数据进行服务预测,在监控指标达到扩容阈值前的 1~2 分钟进行提前扩容。
五、经验总结
技术侧 :
业务侧 :
作者介绍 :
涂扬,美团点评技术专家,现任基础架构部弹性策略团队负责人。
原文链接 :