Redis 是最流行的开源内存数据库之一,可作为数据库、缓存和消息代理使用。针对基于 Google Cloud 运行 Redis 有几种部署场景,Memorystore for Redis 是我们的集成选项。Memorystore for Redis 既能够提供 Redis 的优势,又无需管理成本。
在将系统投入生产之前,对系统进行基准测试并根据您的特定工作负载特性对其进行调整至关重要 —— 即使系统依赖托管服务。在本文中,我们将介绍您能如何衡量 Memorystore for Redis 的性能以及性能调整的最佳实践。一旦我们了解了影响 Memorystore for Redis 性能的因素以及如何对其进行适当调整,您就能保持应用程序的稳定性。
对 Cloud Memorystore 进行基准测试
首先,让我们看一下如何衡量基准。
选择基准工具
有一些工具可用于执行针对 Memorystore for Redis 的基准测试。以下所列工具是一些示例。
●Redis-benchmark
●Memtier-benchmark
●PerfKit Benchmark
在本文中,我们将使用 YCSB,因为它具有灵活控制流量和字段模式的特点,并且在社区得到很好维护。
分析您的应用的流量模式
配置基准工具之前,了解实际的的流量模式是什么样的至关重要。如果您已经一直在运行要基于 Memorystore for Redis 进行测试的应用程序,并且有一些可用指标,应考虑首先对它们进行分析。如果您要向 Memorystore for Redis 部署新的应用程序,可在测试环境中对您的应用程序进行初步负载测试,并使用 Cloud Monitoring 监控性能。
要配置基准工具,需要以下信息:
●每个记录的字段数量
●记录数
●每行的字段长度
●查询模式,例如,SET(设置)和 GET(获取)比率
●正常和高峰时段的吞吐量
基于实际流量模式配置基准工具
针对特定用例进行性能基准测试时,重要的是通过考虑表数据模式、查询模式和实际系统的流量模式来设计基准内容。
在此,我们将假设以下要求。
●表的每行有两个字段
●字段最大长度为 1,000,000
●最大记录数为 1 亿
●查询模式的 GET:SET 比为 7:3
●通常流量为 1k ops/秒,高峰流量为 20k ops/秒
YCSB 可通过配置文件控制基准模式。以下是使用这些要求的示例。
path/to/my_workload
workload=site.ycsb.workloads.CoreWorkload
recordcount=50000
operationcount=3000
insertcount=50000
insertstart=0
fieldcount=2
fieldlength=700
fieldlengthdistribution=zipfian
readproportion=0.7
updateproportion=0.3
insertorder=ordered
requestdistribution=zipfian
实际系统包含不同的字段长度,但您只能通过 YCSB 使用固定字段长度。因此,同时配置字段 = 1,000,000 和记录数 =100,000,000,基准数据规模将与实际系统的数据规模相差甚远。
在这种情况下,运行以下两个测试:
●在字段长度与实际系统相同的情况下进行测试
●在记录数与实际系统相同的情况下进行测试
测试模式和架构
准备配置文件后,要考虑测试条件,包括测试模式和架构。
测试模式
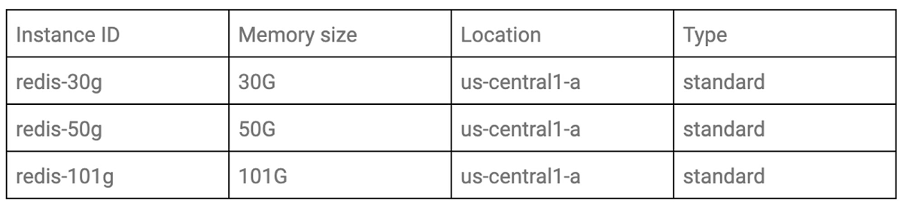
如果您要对比不同条件下实例的性能,应当定义目标条件。在本文中,我们将根据存储层使用以下三种内存大小模式进行测试。
架构
您需要创建 VM 以运行基准脚本。您应当选择足够数量和虚拟机类型,这样,在进行基准测试时,VM 资源不会变成瓶颈。在这种情况下,我们要衡量 Memorystore 本身的性能,因此,VM 应当位于与目标 Memorystore 相同的区域,以最大限度减少网络延迟的影响。架构如下图所示:
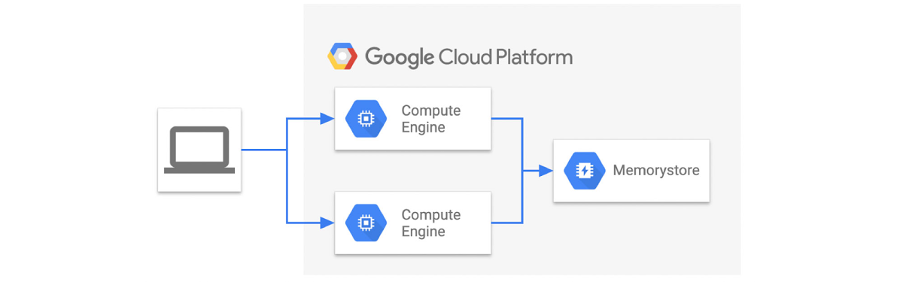
运行基准工具
制定了这些决策后,就可以运行基准工具了。
控制吞吐量模式的运行时选项
您可以通过使用配置文件中的 operationcount 参数和 -target 命令行选项来控制客户端吞吐量。
以下是执行 YCSB 命令的示例:
参数 operationcount=3000 在配置文件中,并运行上述命令。这意味着,YCSB 每秒发送 10 个请求,总请求数为 3,000。因此,YCSB 在 300 秒内抛出 10 个请求。
如下所示,您应当使用增量吞吐量来运行基准测试。注意,为了减少离群值的影响,单一基准测试运行时间应当更长一些:
●客户端吞吐量模式:10、100、1,000、10,000、100,000
加载基准数据
运行基准测试前,您需要为拟测试的 Memorystore 实例加载数据。以下是加载数据的 YCSB 命令的示例:
运行基准测试
现在,您已经加载了数据并选择了命令,可以运行基准测试。调整进程和实例的数量以根据负载量执行 YCSB。为了识别性能瓶颈,您需要查看多项指标。以下是要调查的典型指标:
延迟
针对每项操作(例如,读取 (GET) 和更新 (SET))的 YCSB 输出延迟统计信息,例如,平均、最小、最大以及第 95 个百分位和第 99 个百分位。根据客户服务水平协议 (SLA),我们建议将第 95 个百分位或者第 99 个百分位用于延迟指标。
吞吐量
您可以将吞吐量用于整个操作,这由 YCSB 输出。
资源使用指标
您可以检查资源使用指标,例如,CPU 利用率、内存使用、网络字节输入/输出以及使用 Cloud Monitoring 监控的缓存命中率。
Memorystore 性能调整最佳实践
现在,您已经运行了基准测试,应当使用基准测试结果来调整您的 Memorystore。
基于测试结果,您可能需要消除 Memorystore 实例的瓶颈并提升性能。尽管 Memorystore 是一项完全托管的服务,并且提前对不同参数进行了优化,但仍然会有您可以基于您的特定用例进行调整的项。
有以下几个常见的优化方面:
●数据存储优化
●内存管理
●查询优化
●监控 Memorystore
数据存储优化
优化数据存储方式,不仅节省内存使用,而且还减少 I/O 和网络带宽。
压缩数据
压缩数据通常会导致内存使用和网络带宽的大幅节省。
我们建议将 Snappy 和 LZO 工具用于延迟敏感型用例,并使用 GZIP 以实现最大压缩率。
由 JSON 转向 MessagePack
Msgpack 和 Protocol Buffers 有与 JSON 相同的模式,但比 JSON 更紧凑。Lua 脚本支持 MessagePack。
使用哈希数据结构
保持实例大小足够小
Memorystore 实例的内存大小最高可达 300GB。不过,对于要处理的单一实例,大于 100GB 的数据可能太大,可能由于 CPU 瓶颈导致性能下降。在这种情况下,我们建议创建使用少量内存的多个实例,对其进行分布,并在应用程序端使用键变更它们的接入点。
内存管理
内存的有效使用至关重要,不仅体现在性能调整方面,而且也是为了保持您的 Memorystore 实例稳定运行,不会发生类似内存溢出 (OOM) 的错误。有一些您可以用来管理内存的技巧:
制定驱逐策略
驱逐策略是在 Memorystore 实例内存已满时驱逐数据的规则。您可以通过适当指定这些参数来提高缓存命中率。有以下三组驱逐策略:
●Noeviction:尝试插入更多数据时,如果达到内存限制,将返回错误。
●Allkeys-XXX:驱逐所选择的数据。XXX 是选择拟驱逐的数据的算法名。
●Volatile-XXX:通过设置“expire”(过期)字段驱逐选择的数据。XXX 是选择拟驱逐的数据的算法名。
volatile-lru 默认适用于 Memorystore。为数据驱逐和 TTL 变更数据选择算法。
内存碎片整理
当操作系统分配内存页时会发生内存碎片整理,Redis 在重复执行写入/删除操作后无法充分利用内存页。此类内存页的累积可能导致系统内存不足并最终引发 Redis 服务器崩溃。
如果您的实例运行 4.0 或更高版本的 Redis,可为您的实例启用 activedefrag 参数。Active Defrag 2 有更智能的策略,并且是 5.0 版 Redis 的组成部分。注意,此功能是对 CPU 使用的一种折衷。
升级 Redis 版本
如前所述,activedefrag 参数仅适用于 4.0 或更高版本的 Redis,5.0 版有更好的策略。一般而言,采用更新版本的 Redis 能够以多种方式获得性能优化优势,而不仅仅是内存管理。如果您的 Redis 版本是 3.2,请考虑升级至 4.0 或更高版本。
查询优化
由于可在客户端执行查询优化并且不涉及对实例进行任何变更,它是优化使用 Memorystore 的现有应用程序的最简便的方法。
注意,不能通过 YCSB 检查查询优化的效果,因此,在您的环境中运行查询并检查延迟和吞吐量。
使用流水线和 mget/mset
当连续执行多个查询时,往返引起的网络流量可能成为延迟瓶颈。在这种情况下,建议使用流水线或者聚合命令(例如,MSET/MGET)。
避免对许多元素执行繁重的命令
您可以使用 slowlog 命令监控慢命令。使用许多元素的 SORT、LREM 和 SUNION 可能计算成本很高。检查这些慢命令是否存在问题,如果存在,考虑减少这些操作。
使用 Cloud Monitoring 监控 Memorystore
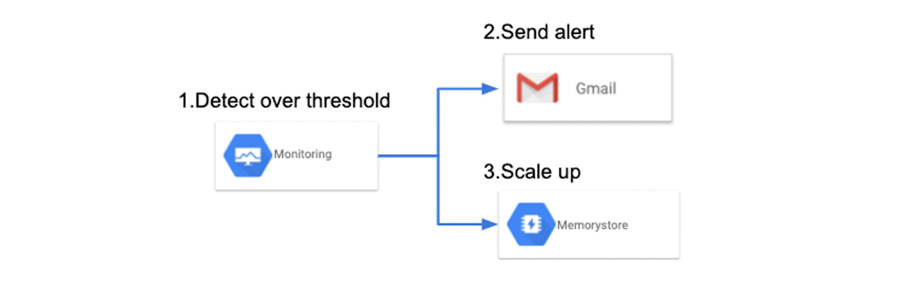
最后,让我们讨论一下通过资源监控以预测现有系统的性能下降。您可以使用 Cloud Monitoring 监控 Memorystore 的资源状态。
即使在部署之前对 Memorystore 进行了基准测试,生产中的 Memorystore 的性能也可能由于各种影响(例如,系统增长以及使用趋势的变化)而下降。要在早期预测此类性能下降,您可以创建一个当资源状态超过某个阈值时可提醒您或者自动扩展的系统。