01 概述
订单系统作为电商系统的“纽带”贯穿了整个电商系统的关键流程。其他模块都是围绕订单系统进行构建的。订单系统的演变也是随着电商平台的业务变化而逐渐演变进化着,接下来就和大家一起来解析电商平台的“生命纽带”。
上帝视角订单系统
订单系统的作用是:管理订单类型、订单状态,收集关于商品、优惠、用户、收货信息、支付信息等一系列的订单实时数据,进行库存更新、订单下发等一系列动作。订单系统业务的基本模型涉及用户、商品(库存)、订单、付款,订单基本流程是下订单——>减库存,这两步必须同时完成,不能下了订单不减库存(超卖),或者减了库存没有生成订单(少卖)。超卖商家库存不足,消费者下了单买不到东西,体验不好;少卖商家库存积压或者需要反复修改商品信息,反复麻烦,体验也不好。

02 订单基本概念
设计订单系统时包含几个大的方向需要考虑,这些内容决定了订单系统的稳定性和可持续性。
订单的多样性特点
订单字段
订单字段包含了订单中需要记录的信息,他的作用主要用于沟通其他系统,为下游系统提供信息依据。
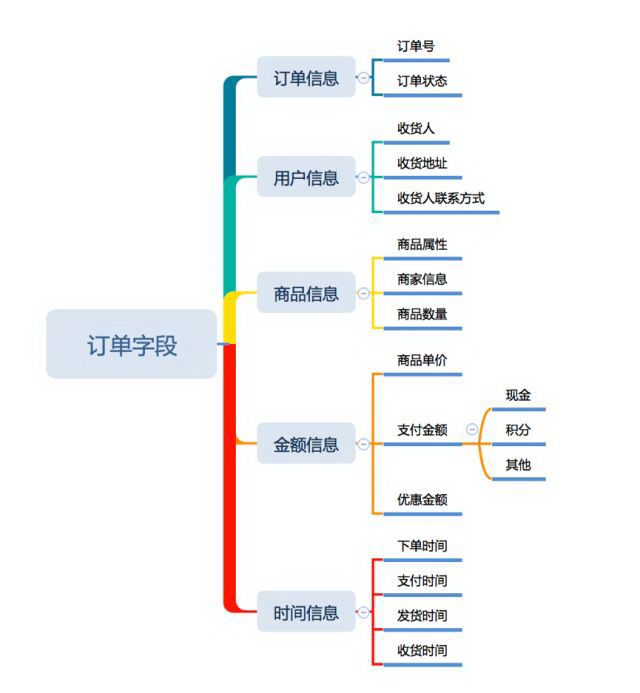
订单信息
订单号作为订单识别的标识,一般按照某种特定规则生成,根据订单的增加进行自增,同时在设计订单号的时候考虑订单无序设置(防止竞争者或者第三方来估算订单量)。订单号后续用作订单唯一标示用于对接 WMS(仓存管理系统)和 TMS(运输管理系统)时的订单识别。
订单状态
订单状态在下面章节会详细描述
用户信息
指买家的相关信息,包括名称、地址、手机号。O2O 还会多一种情况就是自提点,这样地址则会变为自提点的地址。地址信息在后续会作用在 WMS 和 TMS 上用于区分区域和配送安排。
商品信息
商品的基本信息和库存,金额由于比较特殊所以我把金额独立在商品信息以外说,不过逻辑上其实都属于商品信息范畴。商品信息主要影响库存更新和 WMS 产生。
金额信息
订单产生的商品信息,这里面除了要记录最终的金额,过程金额也需要记录。比如商品分摊的优惠金额、支付金额,应付金额等。在后续的订单结算、退换货、财务等环节都需要使用。
时间信息
记录订单每个状态节点的触发时间。
03 订单流程
订单流程是指整个订单从产生到完成整个流转过程,包括了正向和逆向流程的过程。
正向流程
这里面主要是涉及主流电商系统中的通用订单流程,部分细节可以根据自己平台的特殊性进行调整。
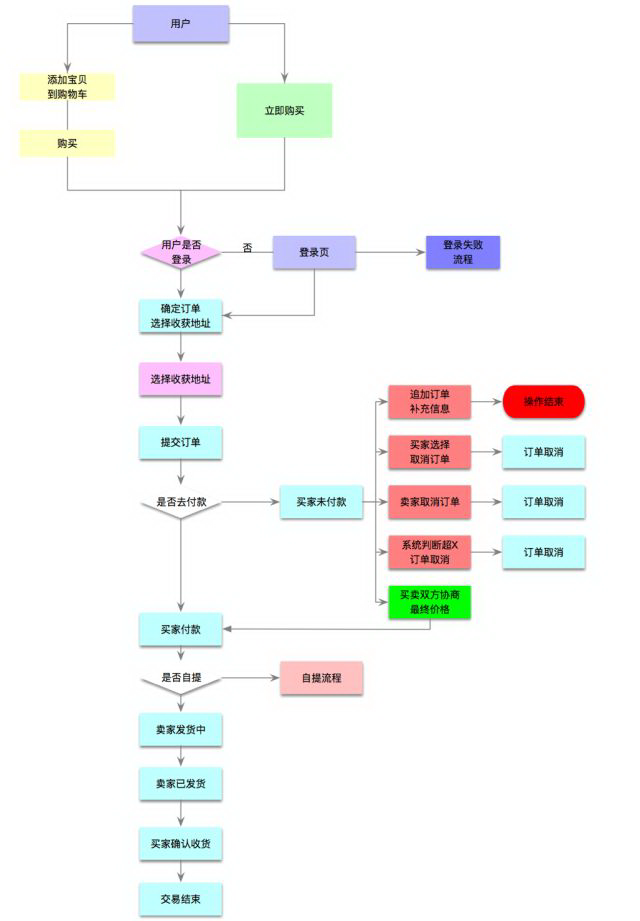
需要注意的地方
逆向流程
逆向流程指订单发生取消、退货等情况时引发的订单流程过程。
触发逆向流程的触发主要有几种情况:
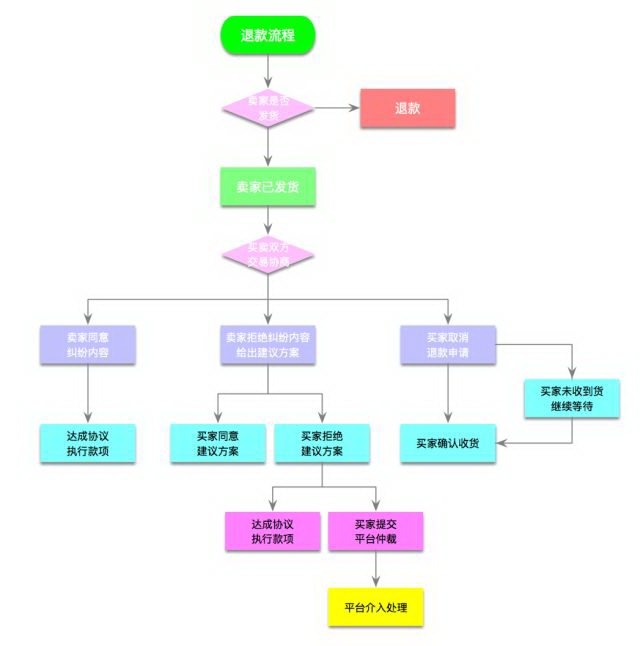
关注点
订单状态
从订单状态设计目的和存在价值去分析和理解它背后设计机制:维度及维度颗粒度大小。
订单推送
当状态发生变化时,需要将对应的变化情况告知给相关人员以便了解当前订单的情况,这就是订单推送的作用。
订单推送的触发依赖于状态机的变化,涉及到的信息包括
04 订单系统设计的挑战和实践
订单系统需求演变
第一步:实现购买流程
第二步:提供服务
第三步:支持不同营销手段下的订单类型
平台发展到足够大的规模,提效、稳定变成一个重要的话题。可以提供不同营销场景下的订单,如:团购、预购等。
订单系统架构的演变
第一代:简单粗暴
第一代的问题
第一代系统由于,订单状态是在特定的服务器进行处理,如果服务一旦出现问题就会造成订单的丢失,导致订单流程无法进行下去。
总结:
1、服务单点
2、数据库单点
第二代:无状态异步驱动
第二代系统对于第一代有了很好的提升,应用服务器不再保留订单状态,但是这样的系统设计同时也给数据库服务器造成了高频查询带来的压力,导致数据库相对比较脆弱。
总结:
状态扫描带来的负载
第三代:队列模式
第三代是对于第二代的升级,订单的状态流转不再依靠高频查询数据库来获得,通过队列模式,很好减轻了数据库的压力,但是第三代依然有问题,就是该系统中 server2 成了核心,该模块的维护就会变得很复杂,这也是架构设计的关键,没有完全的完美架构,只能得到一个平衡架构。
三代系统演变中的最佳实践
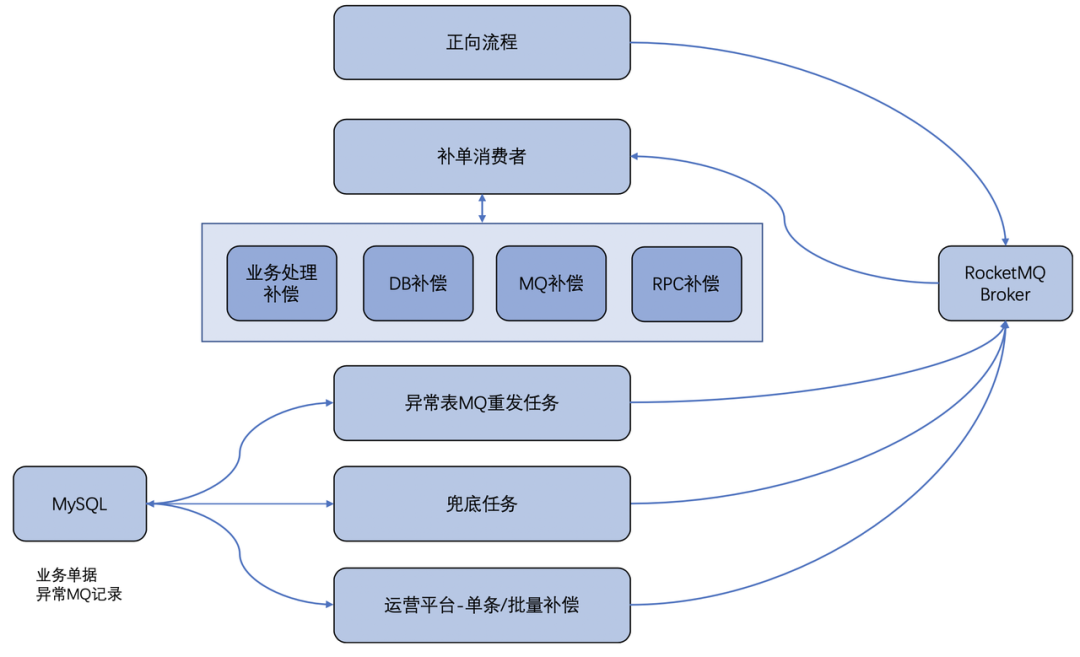
实践 1: 重试和补偿
实践 2: 幂等性
实践 3: 一致性实践
实践 4: 工作流 (Workflow)
系统优化
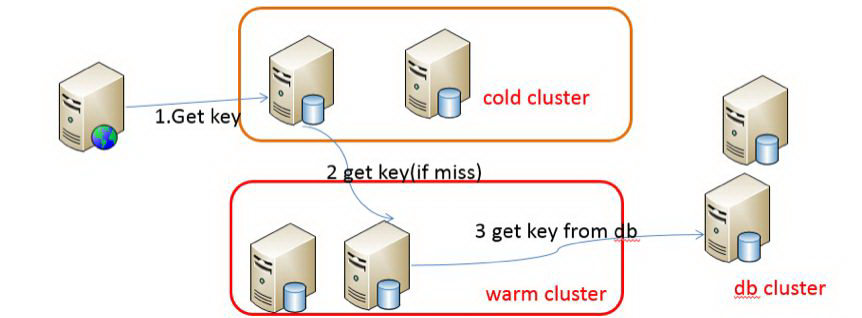
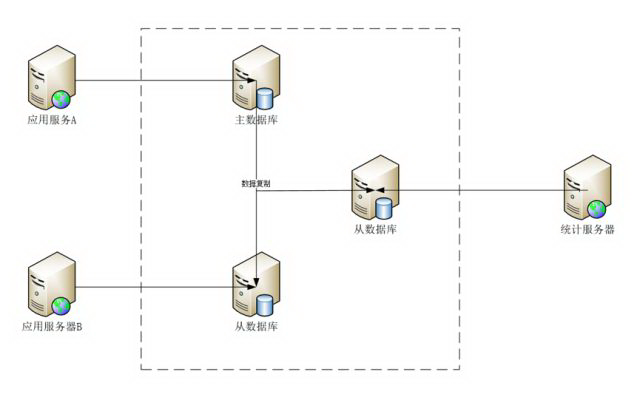
数据库读写分离
基本的原理是让主数据库处理事务性查询,而从数据库处理 SELECT 查询。数据库复制被用来把事务性查询导致的变更同步到集群中的从数据库。 当然,主服务器也可以提供查询服务。使用读写分离最大的作用无非是环境服务器压力。
好处
读写分离提高性能之原因
实现方案
数据库分库分表
不管是采用何种分库分表框架或者平台,其核心的思路都是将原本保存在单表中太大的数据进行拆分,将这些数据分散保存到多个数据库的多个表中,避免因为单表数据量太大给数据的访问带来读写性能的问题。所以在分库分表场景下,最重要的一个原则就是被拆分的数据尽可能的平均拆分到后端的数据库中,如果拆分的不均匀,还会产生数据访问热点,同样存在热点数据因为增长过快而又面临数据单表数据量过大的问题。
而对于数据以什么样的纬度进行拆分,大家看到很多场景中都是对业务数据的 ID(大部分场景此 ID 是以自增长的方式)进行 HASH 取模的方式将数据进行平均拆分,这个简单的方式确实在很多场景下都是非常合适的拆分方法,但并不是在所有的场景中这样拆分的方式都是最优的选择。也就是说数据如何拆分并没有所谓的金科玉律,更多的是需要结合业务数据的结构和业务场景来决定。
下面以大家最熟悉的电商订单数据拆分为例,订单是任何一个电商平台都有的业务数据,每个平台用户提交订单都会在平台后端生成订单相关的数据,一般记录一条订单数据的数据库表结构如下:
订单数据主要由三张数据库表组成,主订单表对应的就是用户的一个订单,每提交一次都会生成一条主订单表的数据。在有些情况下,用户可能在一个订单中选择不同卖家的商品,而每个卖家又会按照该订单中自己提供的商品计算相关的商品优惠(如满 100 元减 10 元)以及按照不同的收货地址设置不同的物流配送,所以会出现子订单的相关概念,即一个主订单会由多个子订单组成,而真正对应到具体每个商品订单信息,则保存在订单详情表中。
如果一个电商平台的业务发展健康的话,订单数据是比较容易出现因为单个数据库表中的数据量过大而造成性能的瓶颈,所以需要对他进行数据库的拆分。此时从理论上对订单拆分是可以由两个纬度进行的,一个纬度是通过订单 ID(一般为自增长 ID)取模的方式,即以订单 ID 为分库分表键;一个是通过买家用户 ID 的纬度进行哈希取模,即以买家用户 ID 为分库分表键。
两种方案做一下对比:
1、如果是按照订单 ID 取模的方式,比如按 1024 取模,则可以保证主订单以及相关子订单,订单详情数据平均落入到后端 1024 个数据库表中,原则上很好地满足了数据尽可能平均拆分的原则。
2、通过采用买家 ID 取模的方式,比如也是按照 1024 取模,技术上则也能保证订单数据拆分到后端的 1024 个数据库表中,但这里就会出现一个业务场景中带来的问题,就是如果有些卖家是交易量非常大的,那这些卖家的订单数据量(特别是订单详情表的数据量)会比其他卖家要多处不少,也就是会出现数据不平均的现象,最终导致这些卖家的订单数据所在的数据库会相对其他数据库提前进入数据归档(为避免在线交易数据库的数据的增大带来数据库性能的问题,一般将 3 个月内的订单数据保存在线交易数据库中,超过 3 个月的订单会归档后端专门的归档数据库)。
所以从对『数据尽可能平均拆分』这条原则来看,按照订单 ID 取模的方式看起来更能保证订单数据的平均拆分,但我们暂时不要这么快下结论,也要根据不同的业务场景和最佳实践角度多思考不同纬度带来的优缺点。
总结
电商平台的需求一直在变化,随之订单系统的架构也会随之变化,架构设计就是一个持续改进的过程,这篇文章还有好多细节未提及,如果你想把订单系统做的更好,需要更加深入系统的每一个环节,比如:容灾、灾备、分流、流控都需要慢慢雕琢,在架构中没有完美的架构只有平衡的架构,不要追求单点的完美,而是要追求多点的平衡。