业务背景
思必驰是一家对话式人工智能平台公司,拥有全链路的智能语音语言技术,致力于成为全链路智能语音及语言交互的平台型企业,自主研发了新一代人机交互平台 DUI 和人工智能芯片,为车联网、IoT 及政务、金融等众多行业场景合作伙伴提供自然语言交互解决方案。
思必驰于 2019 年首次引入Apache Doris,基于 Apache Doris 构建了实时与离线一体的数仓架构。相对于过去架构,Apache Doris 凭借其灵活的查询模型、极低的运维成本、短平快的开发链路以及优秀的查询性能等诸多方面优势,如今已经在实时业务运营、自助/对话式分析等多个业务场景得到运用,满足了设备画像/用户标签、业务场景实时运营、数据分析看板、自助 BI、财务对账等多种数据分析需求。在这一过程中我们也积累了诸多使用上的经验,在此分享给大家。
架构演进
早期业务中,离线数据分析是我们的主要需求,近几年,随着业务的不断发展,业务场景对实时数据分析的要求也越来越高,早期数仓架构逐渐力不从心,暴露出很多问题。为了满足业务场景对查询性能、响应时间及并发能力更高的要求,2019 年正式引入 Apache Doris 构建实时离线一体的数仓架构。
以下将为大家介绍思必驰数仓架构的演进之路,早期数仓存在的优缺点,同时分享我们选择 Apache Doris 构建新架构的原因以及面临的新问题与挑战。
早期数仓架构及痛点
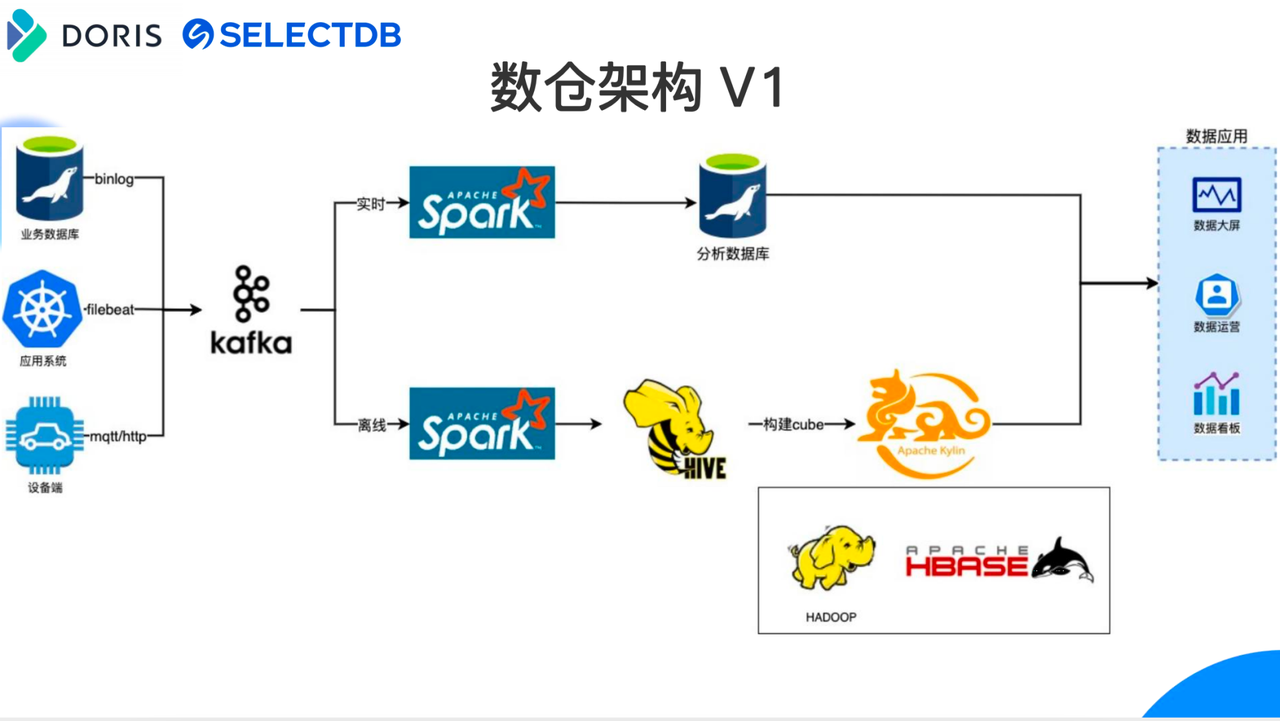
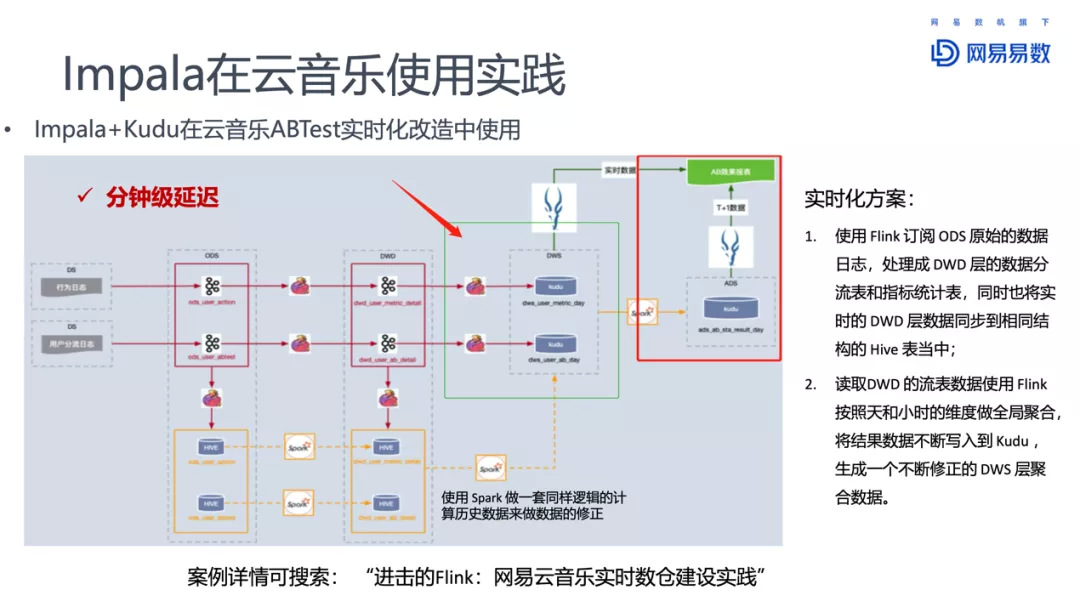
如上图所示,早期架构基于 Hive +Kylin 来构建离线数仓,实时数仓架基于 Spark+MySQL 来构建实时分析数仓。
我们业务场景的数据源主要分为三类,业务数据库如 MySQL,应用系统如 K8s 容器服务日志,还有车机设备终端的日志。数据源通过 MQTT/HTTP 协议、业务数据库 Binlog 、Filebeat 日志采集等多种方式先写入 Kafka。
在早期架构中,数据经 Kafka 后将分为实时和离线两条链路,首先是实时部分,实时部分链路较短,经过 Kafka 缓冲完的数据通过 Spark 计算后放入 MySQL 中进行分析,对于早期的实时分析需求,MySQL 基本可以满足分析需求。而离线部分则由 Spark 进行数据清洗及计算后在 Hive 中构建离线数仓,并使用 Apache Kylin 构建 Cube,在构建 Cube 之前需要提前做好数据模型的的设计,包括关联表、维度表、指标字段、指标需要的聚合函数等,通过调度系统进行定时触发构建,最终使用 HBase 存储构建好的 Cube。
早期架构的优势:
早期架构解决了当时业务中较为紧迫的查询性能问题,但随着业务的发展,对数据分析要求不断升高,早期架构缺点也开始逐渐凸显出来。
早期架构的痛点:
架构选型
为解决以上问题,我们开始探索新的数仓架构优化方案,先后对市面上应用最为广泛的 Apache Doris、Clickhouse 等 OLAP 引擎进行选型调研。相较于 ClickHouse 的繁重运维、各种各样的表类型、不支持关联查询等,结合我们的 OLAP 分析场景中的需求,综合考虑,Apache Doris 表现较为优秀,最终决定引入 Apache Doris 。
新数仓架构
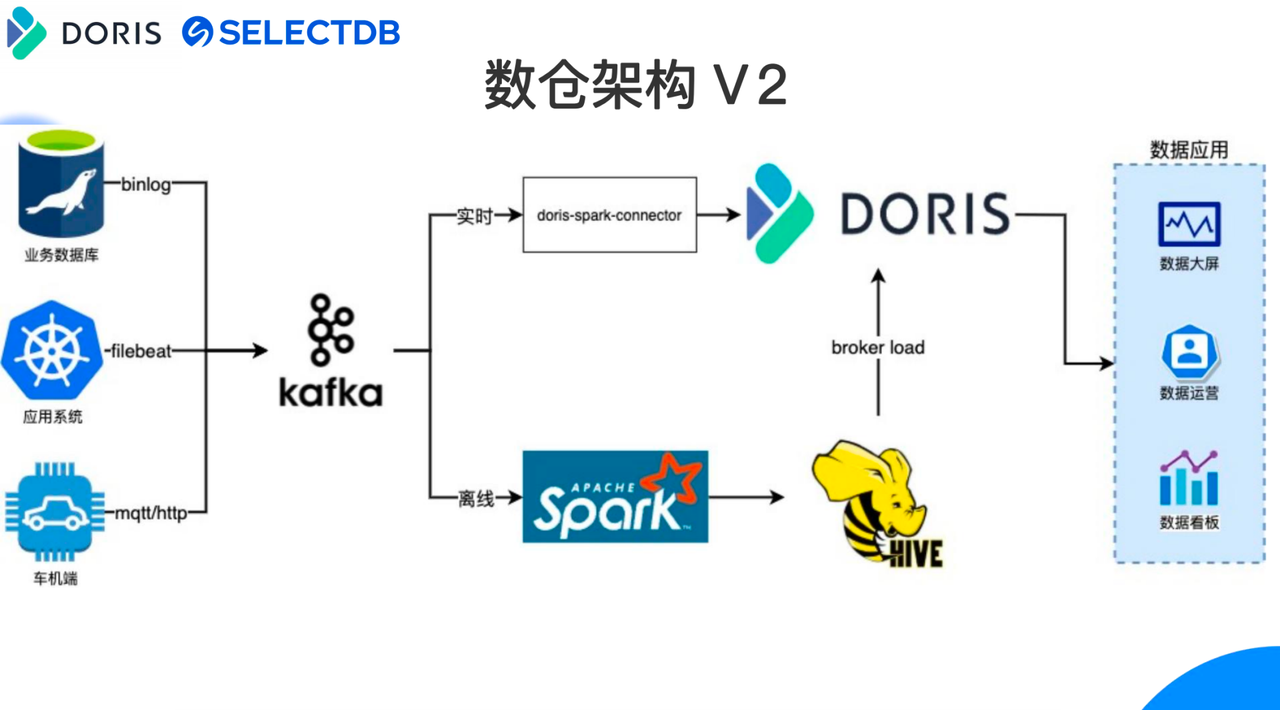
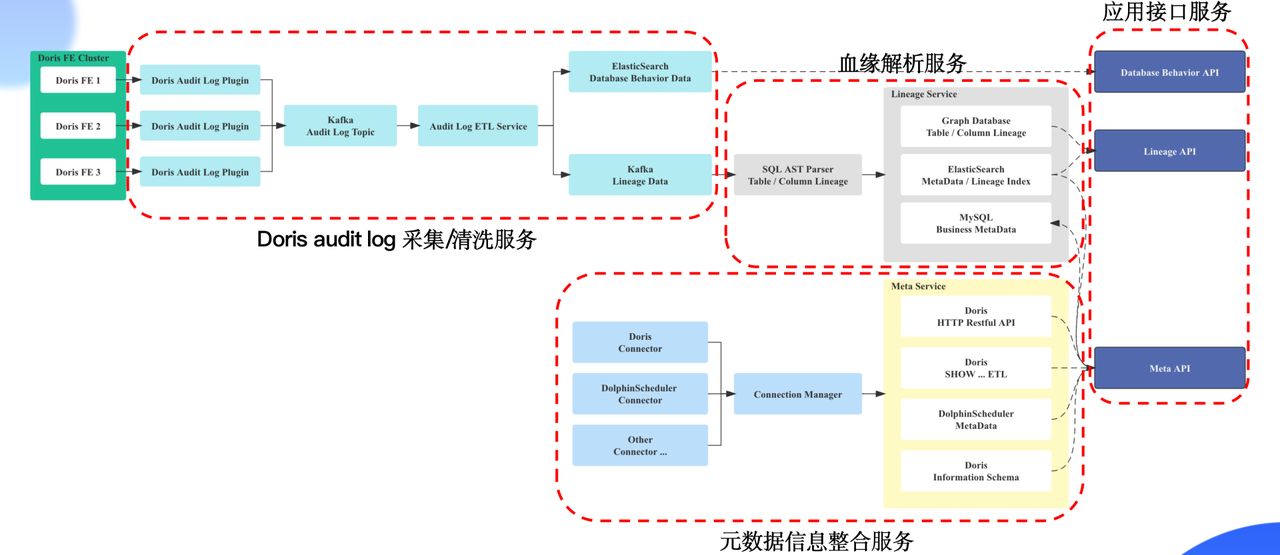
如上图所示,我们基于 Apache Doris 构建了实时+离线一体的新数仓架构,与早期架构不同的是,实时和离线的数据分别进行处理后均写入 Apache Doris 中进行分析。
因历史原因数据迁移难度较大,离线部分基本和早期数仓架构保持一致,在 Hive 上构建离线数仓,当然完全可以在 Apache Doris 上直接构建离线数仓。
相对早期架构不同的是,离线数据通过 Spark 进行清洗计算后在 Hive 中构建数仓,然后通过 Broker Load 将存储在 Hive 中的数据写入到 Apache Doris 中。这里要说明的, Broker Load 数据导入速度很快,天级别 100-200G 数据导入到 Apache Doris 中仅需要 10-20 分钟。
实时数据流部分,新架构使用了 Doris-Spark-Connector 来消费 Kafka 中的数据并经过简单计算后写入 Apache Doris 。从架构图所示,实时和离线数据统一在 Apache Doris 进行分析处理,满足了数据应用的业务需求,实现了实时+离线一体的数仓架构。
新架构的收益
问题和挑战
在建设新数仓架构过程中,我们遇到了一些问题:
业务场景的应用
Apache Doris 在思必驰最先应用在实时运营业务场景以及自助/对话式分析场景,本章节将介绍两个场景的需求及应用情况。
实时运营业务场景
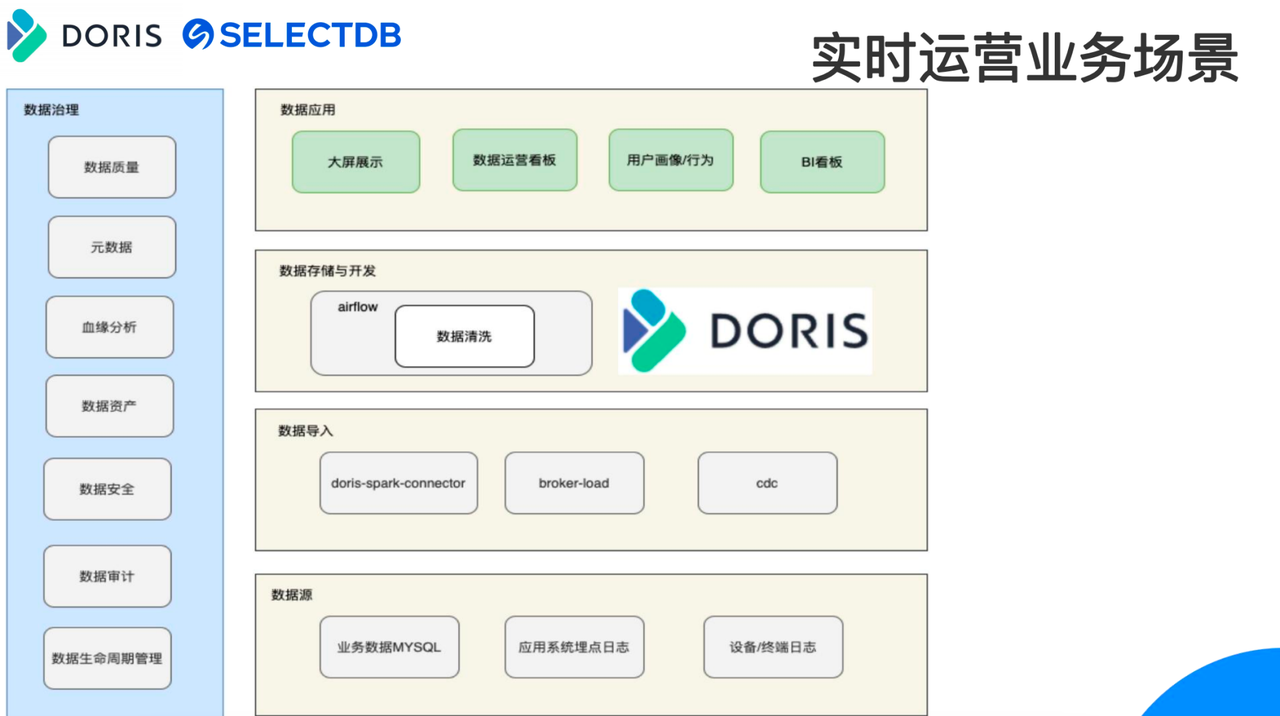
首先是实时运营业务场景,如上图所示,实时运营业务场景的技术架构和前文所述的新版数仓架构基本一致:
在实时运营业务场景中,数据分析的需求主要有两方面:
自助/对话式分析场景
除以上之外,Apache Doris 在思必驰第二个应用是自助/对话式分析场景。
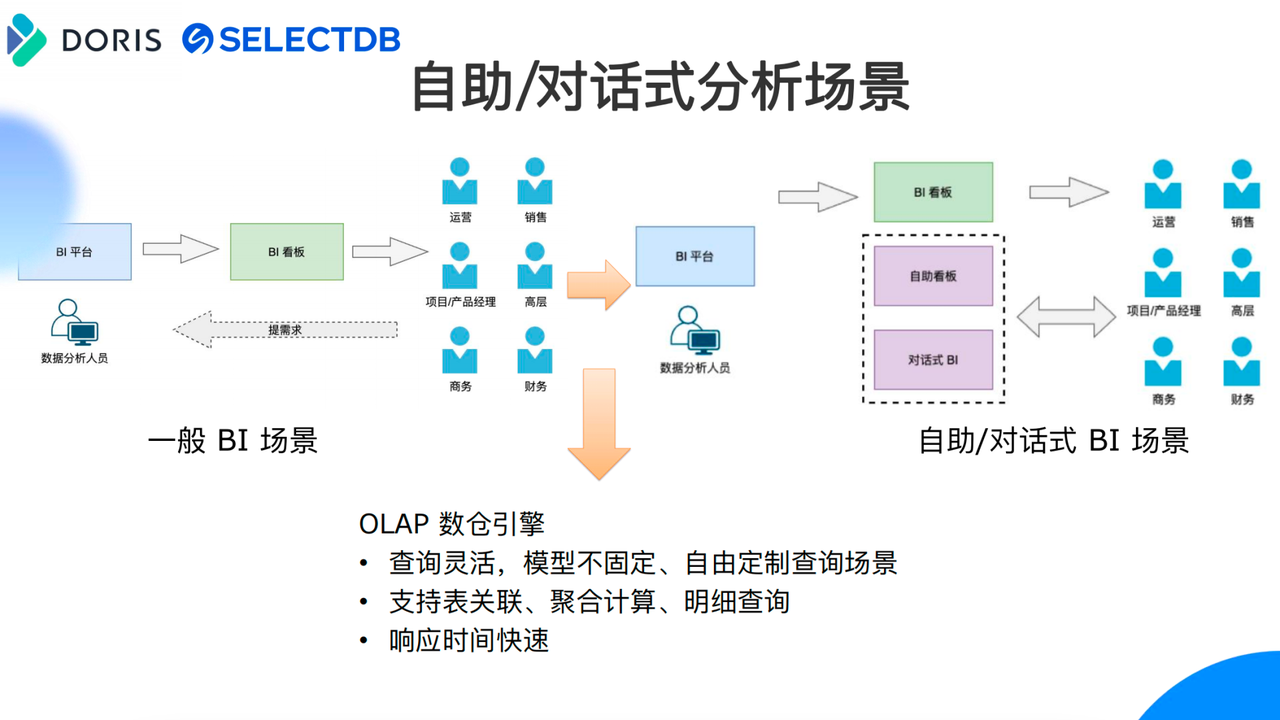
如上图所示,在一般的 BI 场景中,用户方比如商务、财务、销售、运营、项目经理等会提出需求给数据分析人员,数据分析人员在 BI 平台上做数据看板,最终把看板提供给用户,用户从 BI 看板上获取所需信息,但是有时候用户想要查看明细数据、定制化的看板需求,或者在某些场景需做任意维度的上卷或者下钻的分析,一般场景下 BI 看板是不支持的的,基于以上所述用户需求,我们打造了自助对话式 BI 场景来解决用户定制化的需求。
与一般 BI 场景不同的是,我们将自助/对话式 BI 场景从数据分析人员方下沉到用户方,用户方只需要通过打字,描述数据分析的需求。基于我们公司自然语言处理的能力,自助/对话式 BI 场景会将自然语言转换成 SQL,类似 NL2SQL 技术,需要说明的是这里使用的是定制的自然语言解析,相对开源的 NL2SQL 命中率高、解析结果更精确。当自然语言转换成 SQL 后,将SQL 给到 Apache Doris 查询得到分析结果。由此,用户通过打字就可以随时查看任意场景下的明细数据,或者任意字段的上卷、下钻。
相比 Apache Kylin、Apache Druid 等预计算的 OLAP 引擎,Apache Doris 符合以下几个特点:
因此我们很顺利的运用 ApacheDoris 实现了自助/对话式分析场景。同时,自助/对话式分析在我们公司多个数据分析场景应用反馈非常好。
实践经验
基于上面的两个场景,我们使用过程当中积累了一些经验和心得,分享给大家。
数仓表设计
写入
查询
存储
使用 SSD 和 HDD 做热温数据存储周期的分离,近一年以内的数据存在 SSD,超过一年的数据存在 HDD。Apache Doris 支持对分区设置冷却时间,但只支持创建表分区时设置冷却的时间,目前的解决方案是设置自动同步逻辑,把历史的一些数据从 SSD 迁移到 HDD,确保 1 年内的数据都放在 SSD 上。
升级
升级前一定要备份元数据,也可以使用新开集群的方式,通过 Broker 将数据文件备份到 S3 或 HDFS 等远端存储系统中,再通过备份恢复的方式将旧集群数据导入到新集群中。
升级前后性能对比
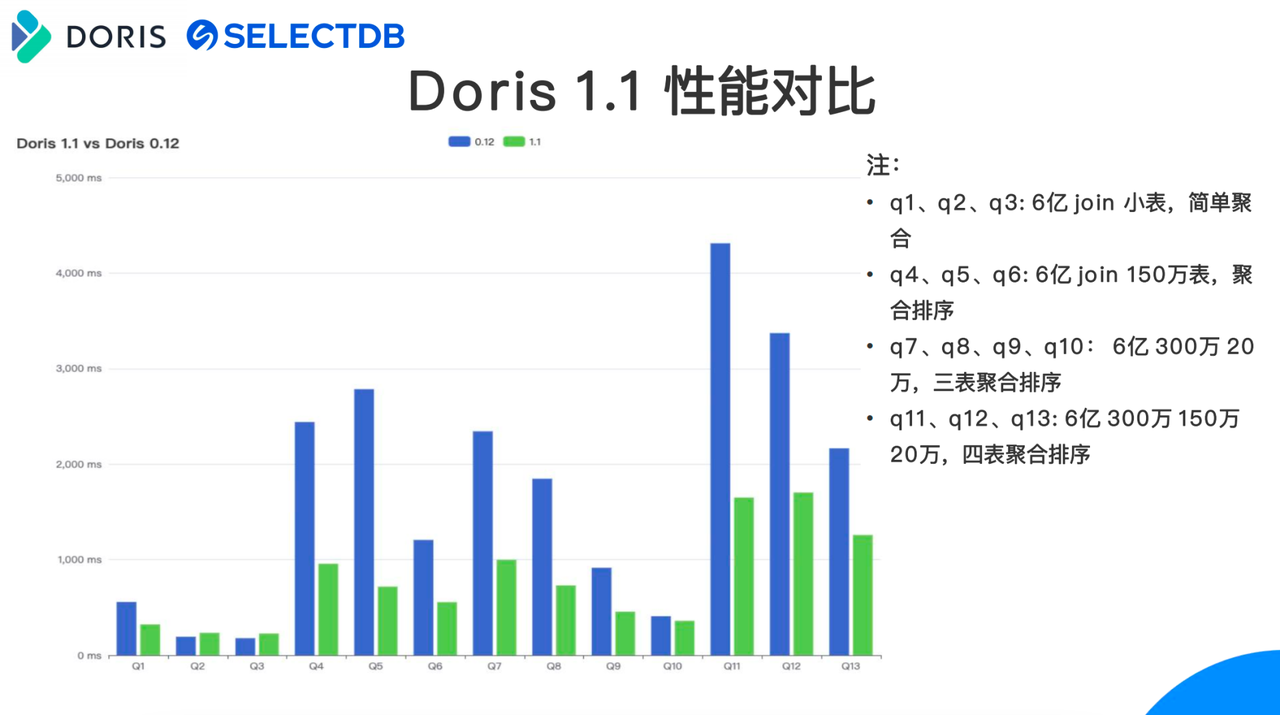
思必驰最早是从 0.12 版本开始使用 Apache Doris 的,在今年我们也完成了从 0.15 版本到最新1.1 版本的升级操作,并进行了基于真实业务场景和数据的性能测试。
从以上测试报告中可以看到,总共 13 个测试 SQL 中,前 3 个 SQL 升级前后性能差异不明显,因为这 3 个场景主要是简单的聚合函数,对 Apache Doris 性能要求不高,0.15 版本即可满足需求。而在 Q4 之后的场景中 ,SQL 较为复杂,Group By 有多个字段、多个字段聚合函数以及复杂函数,因此升级新版本后带来的性能提升非常明显,平均查询性能较 0.15 版本提升 2-3 倍。由此,非常推荐大家去升级到 Apache Doris 最新版本。
总结和收益
未来计划
作者介绍
赵伟,思必驰大数据高级研发,10 年大数据开发和设计经验,负责大数据平台基础技术和 OLAP 分析技术开发。社区贡献:Doris-spark-connector 的实时读写和优化。