一、动机
01 实时即未来
自 2015 年“streaming 101: the world beyond batch”[1] 发表以来,已经过去了将近 5 年。现在,越来越多的人相信, 批处理是流式处理的特殊情况,基于流式处理的实时数据分析才是未来发展的方向。
与传统批处理相比, 流式处理的优势 有以下几点:
流处理的框架,在 开源和商用领域 也取得了很好的发展[2],如今更加成熟和稳定,足够在生产环境广泛使用。其中 Apache Flink [3]的模型定义和机制设计比较符合公司里的业务场景,很多用户都在其上建立自己的应用程序。
02 简单强大的 SQL 语言
SQL 是数据分析人员最熟悉的语言。相对于传统运行在数据库和批处理中的 SQL, 流式 SQL 有以下特点 :
一些开源 SQL 引擎已经增加了对流式 SQL 的支持。比如,[4]添加了 Window 等关键字。流处理框架产品,也几乎都增加了原生对于 SQL 的支持,比如[5]和[6]。使用 SQL 而不是更底层的 API 来描述业务逻辑的好处有:
当然,由于抽象层次更高,SQL 可能只能覆盖的用户场景,所以,流处理框架通过支持 User Defined Function(UDF)和 Complex Event Processing(CEP)来满足更高级别用户的需求。
03 拥抱开源社区的同时弥补缺陷
开源社区在流处理和流式 SQL 处理领域都已经做了大量的工作,没有必要从头开始重新造轮子。 但是,与其他开源社区产品一样,在公司内部做到开箱即用,还是会存在一些差距 ,主要表现为以下几个方面:
二、功能
本章罗列了 Rheos SQL 作为流式 SQL 处理引擎所支持的功能。
01 SQL 语义与语法
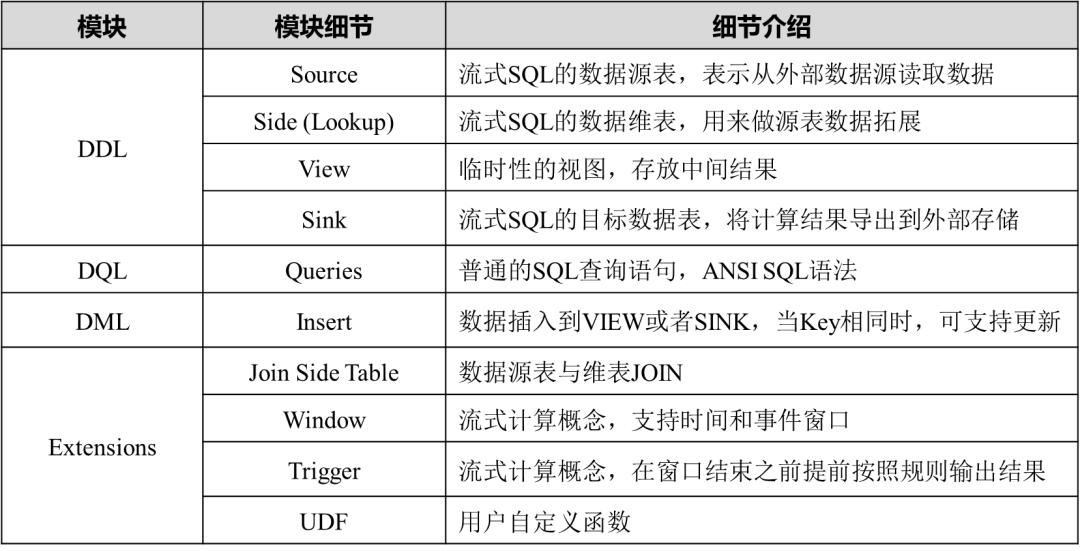
当前支持的语法模块如下表所示:
02 与外部资源对接模块
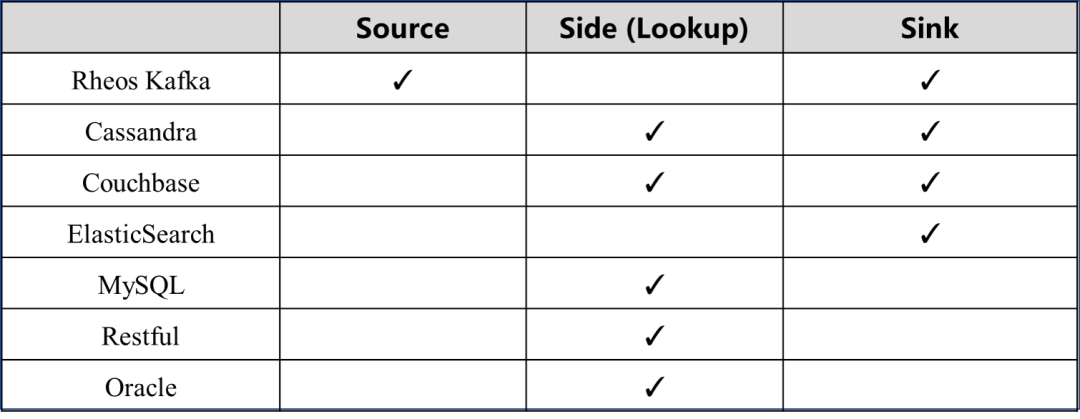
当前支持访问的外部模块如下表所示:
三、架构
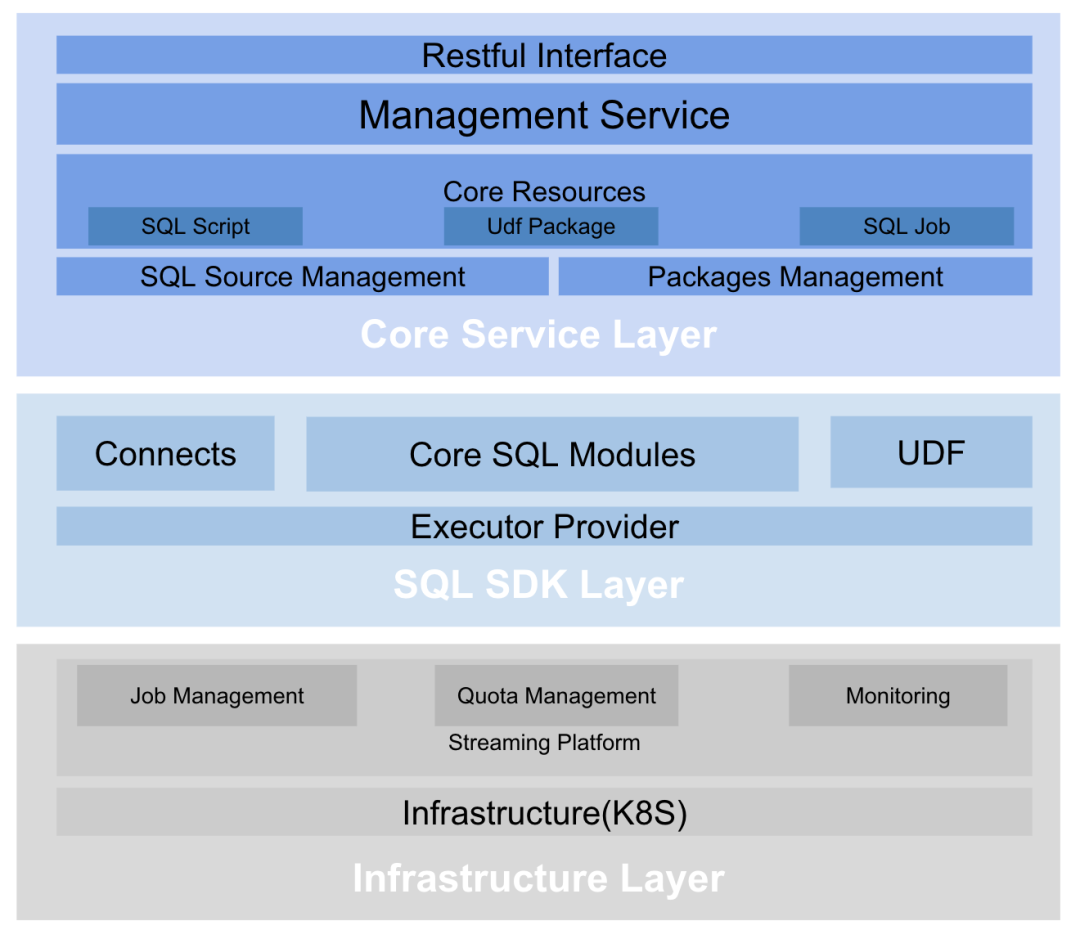
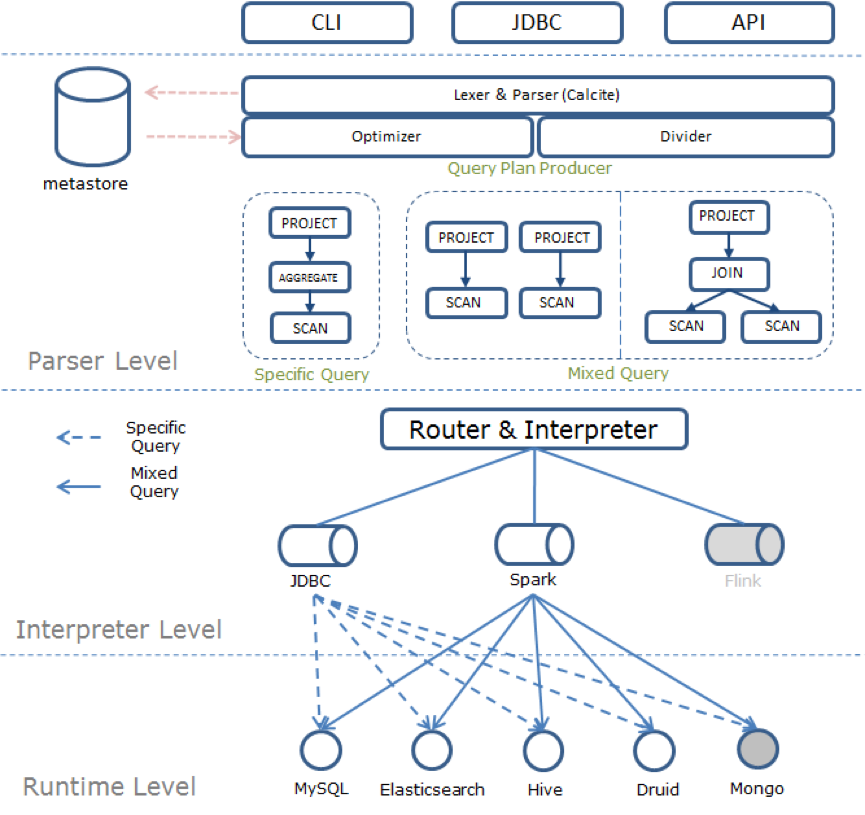
如上图所示,在总体架构上, Rheos SQL 分为三层:核心服务层 (Core Service Layer), SQL 开发工具包层 (SQL SDK Layer)以及 基础服务层 (Infrastructure Layer)。
01 核心服务层(Core Service Layer)
该层主要负责管理面相用户的 SQL 资源 ,是用户接触的主要接口。
02 SQL 开发工具包层(SQL SDK Layer)
该层负责在开源流式 SQL 引擎上增强扩展 ,支持更丰富的语义和语法。
当前,SQL 工具包是在 FLINK SQL 的基础上,提供了功能扩展。
该层的设计可以帮助我们在不影响用户的同时,灵活切换底层基础服务的实现。比如,Rheos SQL 可以内部升级 FLINK 的版本,或者使用其他流处理框架实现流处理的功能,而用户对接的则一直是 Rheos SQL 定义的语法与编程接口。
03 基础服务层(Infrastructure Layer)
该层负责运行时基础设施的提供与维护 。在公司内部,所有集群都运行在平台,并有流平台团队提供了流处理基础设施的管理。
当前,Rheos SQL 选用的流处理框架是 Apache Flink ,流平台团队管理了 Flink 集群的创建与维护,并支持资源额度管理、基础监控暴露收集等。
四、用户体验
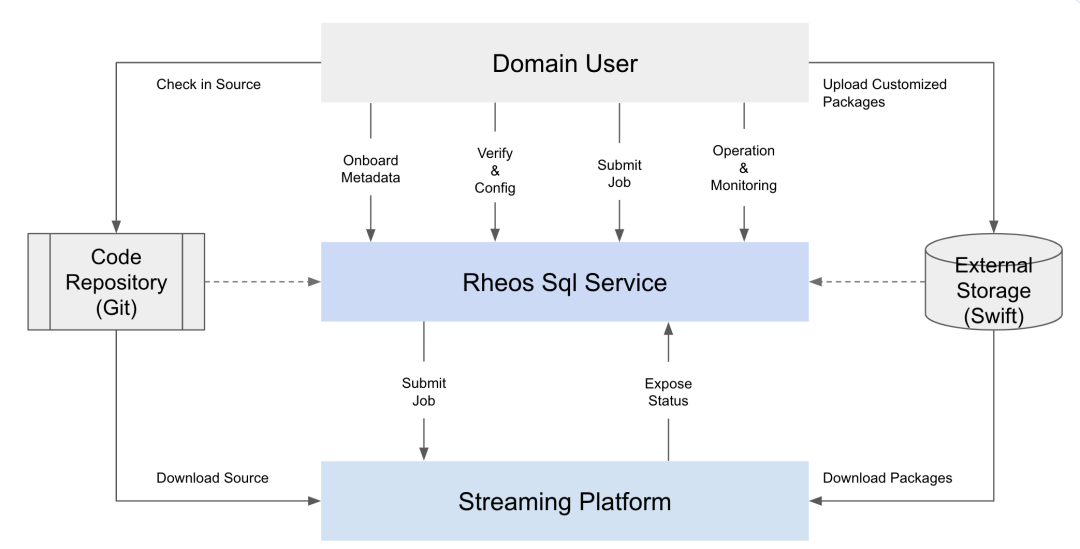
上图展示了 Rheos SQL 平台的使用流程, 其用户体验可归结如下 :
首先,像开发其他应用程序一样,编写 SQL 源代码,并提交到代码库。 在我们的实现中,提供对接两种代码库的实现 :
如果是比较高级的用户,需要编写 UDF 或者在 SQL 工具包的基础上定制功能,可以在本地编码结束后,上传到远程的存储。流平台团队提供了 MAVEN 插件 ,可以在 IDE 中方便地完成上传。在实现时,我们使用的对象存储是[7]。
除此之外,用户需要将 SQL 脚本和自定义的包在 Rheos SQL 的系统中注册,完成源信息的提交(Metadata Onboard)。
为了尽快找到程序中的 bug,验证逻辑和配置细节,Rheos SQL 平台提供了 线上验证和配置 的功能。
一切就绪后,可以在 Rheos SQL 平台提交作业。Rheos SQL 会将这个 SQL 作业,转化成 底层流平台 具体实现的作业。
在当前实现中,Rheos SQL 作业会被注册成 Flink 的作业,存放到流平台上。在运行时,Rheos SQL 的工具包会根据用户注册的信息,动态拉取 SQL 脚本的源代码,并加载用户自定义的扩展包,进行解析、优化并在流框架上执行用户逻辑。
作业运行起来后,可以通过 Rheos SQL 的门户网站操作和监控。
五、与维表的 JOIN
01 用例
在现有的业务场景中,有很多使用源表数据与外部存储 JOIN 的用例。
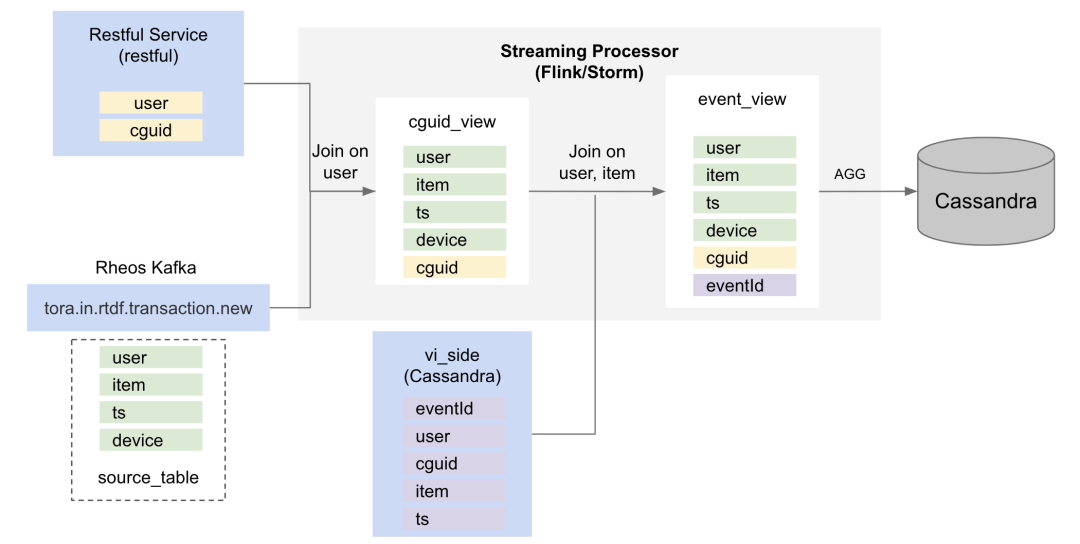
上图是实际应用的一个例子,输出与用户购买行为相关的统计信息。SQL 作业的数据源是存放在中的用户交易数据。
处理的第一步 ,是将源表与一张 RESTful 形式的维表根据 user 域做 JOIN,构造出 cguid_view 临时表。
处理的第二步 ,是将 cguid_view 临时表,与存放在 Cassandra 中的一张维表,根据 user 和 itemId 域做 JOIN,输出 event_view 临时表。
处理的第三步 ,是在 event_view 临时表上做聚合,将最终的结果输出到 Cassandra。
02 实现细节
为了提升性能,在实现维表 JOIN 时,Rheos SQL 重点做了以下两方面的工作:
六、Debug 和监控
为了加快迭代速度,及时发现问题,Rheos SQL 在不同的阶段提供了丰富的工具帮助用户调试和监控 SQL 作业。
01 本地测试框架
SQL 开放工具集中,提供了一个 本地测试框架 ,具体功能为:
在这个测试框架的帮助下,用户可以本地完成 SQL 脚本的开发和测试工作,并初步验证逻辑的正确性,及时对 bug 做好修正。
02 SQL 逻辑图
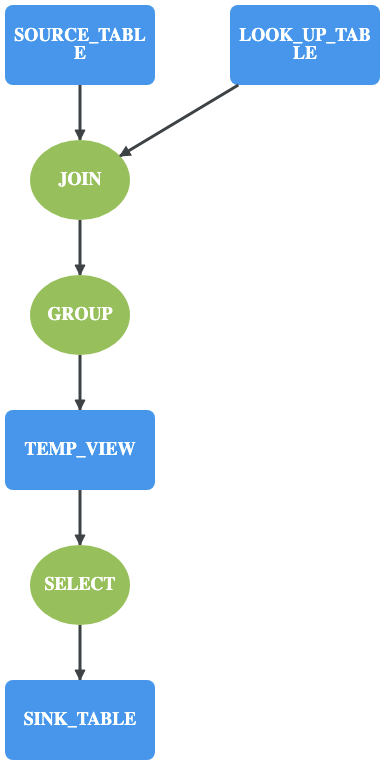
用户在 Rheos SQL 系统中注册好 SQL 之后,可以查看 SQL 的逻辑执行图 。
上图是一个实际应用中的例子。源表和维表在第一次 JOIN 之后,将聚合的结果写入到了 TEMP_VIEW,然后从临时表中选取了部分数据输出到目标表。
用户通过逻辑执行图,可以验证逻辑是否符合预期,在将 SQL 作业真正运行前,发现问题并修正。
03 线上 SQL 作业的监控
除去 Flink 本身提供的监控指标之外,Rheos SQL 还提供了很多从 SQL 表级别暴露的信息 。根据表类型的不同,部分指标详情如下:
用户通过对业务指标的监控,可以在作业运行时感知到异常情况的发生,及时采取应对措施。
总结与展望
Rheos SQL 平台 在开源流式 SQL 处理框架的基础上,提供了丰富的语义与扩展。用户可以在 Rheos SQL 平台上,方便地开发、调试、监控 SQL 作业,节省流式作业的开发,维护成本。接下来,Rheos SQL 在进一步满足用户需求的同时,将会在 资源管理、动态扩容以及 CEP 语义支持 等方面,投入更多的努力。
参考文献
[1]原文链接 :