为什么我们关注指标监控
以天气为例。
指标:衡量和描述对象的方式
监控:对指标进行监测和控制
本文由美团点评研发工程师孙梦瑶分享,主要介绍 Flink 的指标监控和报警,从以下四个方面展开:
1. 监控报警的链路
1.1 监控报警链路
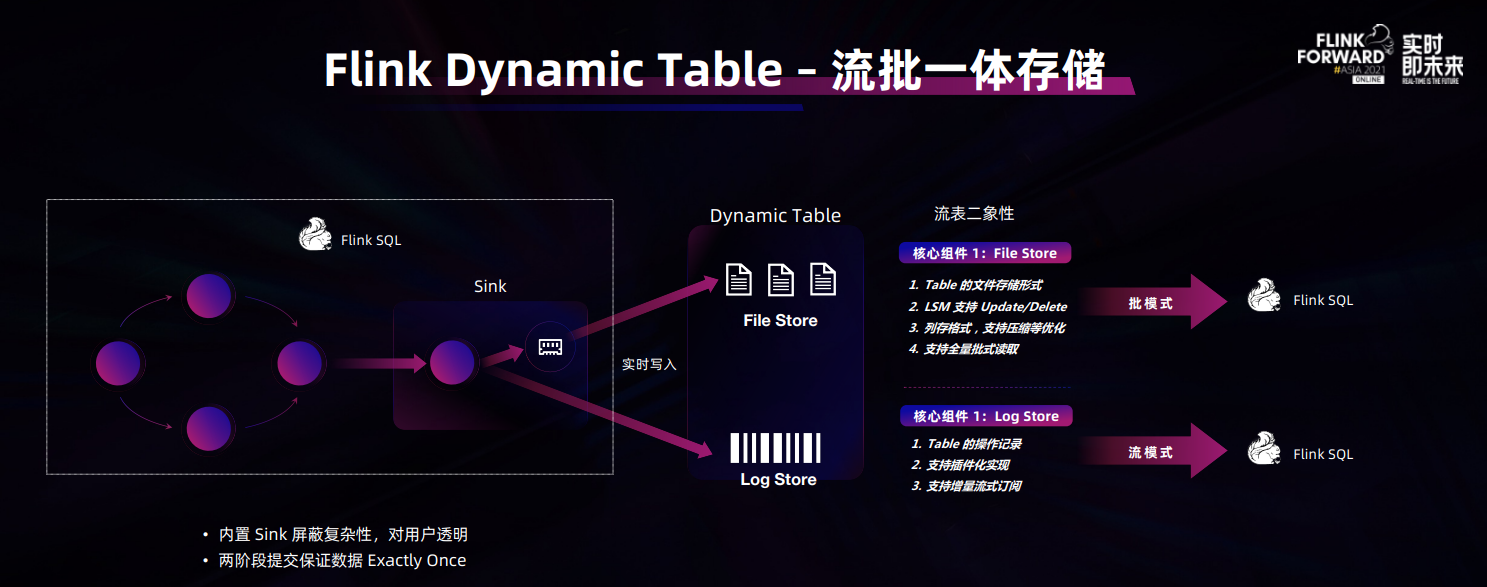
美团点评的指标监控报警的链路如下图所示。

首先是我们对日志和指标都会进行统一的集中化的收集。Reporter (2.8 和 3.1 中有介绍)把 Flink 作业的指标作为一条条日志打出来。然后再通过日志收集收上去,收到 Kafka 里面。接下来会通过实时作业做解析和聚合,再将得到的指标落到 Kafka 里,作为实时数据源。
下游会根据不同的需求,对不同的数据做不同的处理和展示。日志数据会落到 ES 里供查询使用,同时也会根据关键字接实时作业进行处理,做日志相关报警;数值指标会落到 OpenTSDB 里供大家查询,同时也支持各类的指标报警。最终这些内容还是会集中到我们的实时计算平台里,给用户做一个统一的展示。
整个链路下来,主要分为三个关键环节。
1.2 指标展示:Grafana
Grafana 支持比较多的数据源格式,比如 ES、OpenTSDB 等;它有个变量的功能,可以看某个作业的指标,也可以一起对比看。
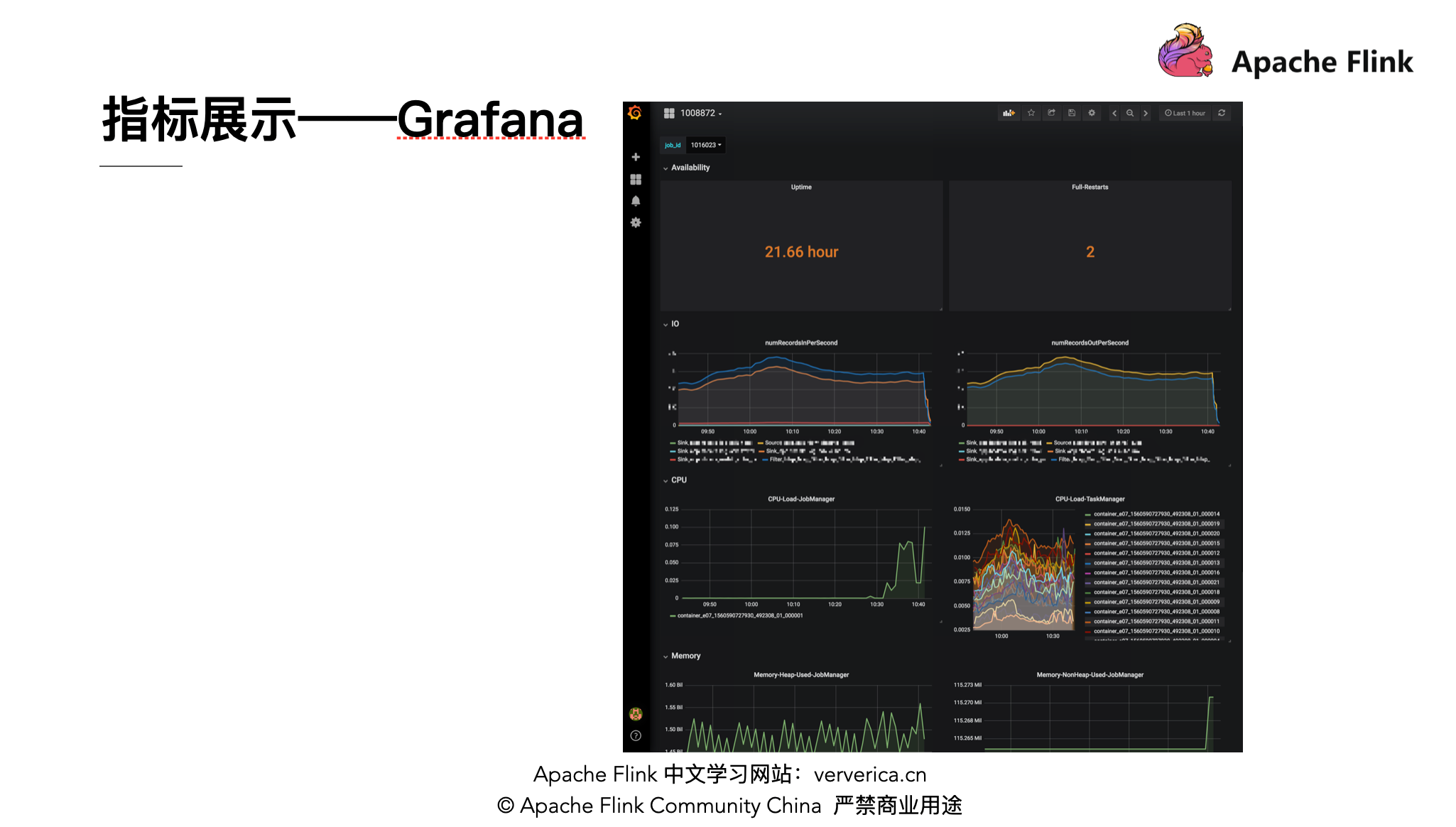
相比于自研的指标展示工具,Grafana 配置界面会比较方便,省时省力,性价比高。如果是只是想简单的展示一下所有的作业的指标的话,Grafana 是个很好的选择,它也可以被外嵌在其他的页面上。但是 Grafana 图的类型比较单一,在实际的直接使用过程中可能还会有一些局限性。
2. 常用的监控项
下面我们来关注下一般会使用哪些指标来衡量作业运行的状况。
2.1 常用的指标
■ 系统指标
系统指标在 Flink 官网有相应的说明。
■ 自定义指标
自定义指标是指用户可以在自己的作业逻辑中进行埋点,这样可以对自己的业务逻辑进行监控。
正如其他讲师所提到的,现在的 Flink 作业更像是一种微服务,不仅关心作业是否把所有数据都处理完了,还希望作业可以 7×24 小时不间断的运行来处理数据。因此在业务逻辑中重要的指标在 Flink 中也会很重要。
另外还有几类是关于作业的处理逻辑,如果处理逻辑抛出异常将会导致作业 fullRestarts,此时一般会将这些异常进行 catch 住,如果涉及复杂计算的可以通过重试机制多试几次,如果重试后未成功则丢弃数据 。此时可以将处理数据的占比或者数据的某些特征作为指标上报,这样可以观察此类数据的占比来观测数据处理是否存在异常。又如 filter 过滤的数据占比可以观测 filter 的逻辑是否正常,还有窗口等涉及时间的算子需要监测超时丢弃的数据的占比等。

2.2 如何确定哪些指标需要关注?

3. 指标的聚合方式
在上面介绍了常用的监控指标,接下来介绍下这些指标应该怎么看。同一个指标可能在机器的角度去看,也可能在作业的角度去看,不同的角度会得出不同的结果。
首先是作业的聚合维度,细粒度的如 Task、Operator 维度,稍微大点的粒度如 Job、机器、集群或者是业务维度(如每个区域)。当查问题时从大的粒度着手,向细粒度进行排查。如果想看全局的现状则需要比较粗的粒度。可以将原始指标进行上报然后根据不同场景进行聚合。如果要做性能测试则需要细粒度的查询,如 task 粒度。

另一方面是聚合的方式,如总和、均值、最大值、最小值、变化率等,需要注意是要消除统计误差,对数据取移动平均或者固定时间的平均来使曲线变得更加平滑。还有是差值,如上游数据量与下游数据量的差值、最新 offset 与消费的 offset 的差值。另外对于衡量 xx 率、xx 耗时可以使用 99 线。最后还有一点需要关注的,也是我们在实际工作中遇到的坑,即指标的缺失,如果没有拿到指标,作业状态则变成了黑盒,需要去关注作业的指标收集是否正常,需要监测是否存在指标丢失,是单个指标丢失还是整个作业的指标丢失。

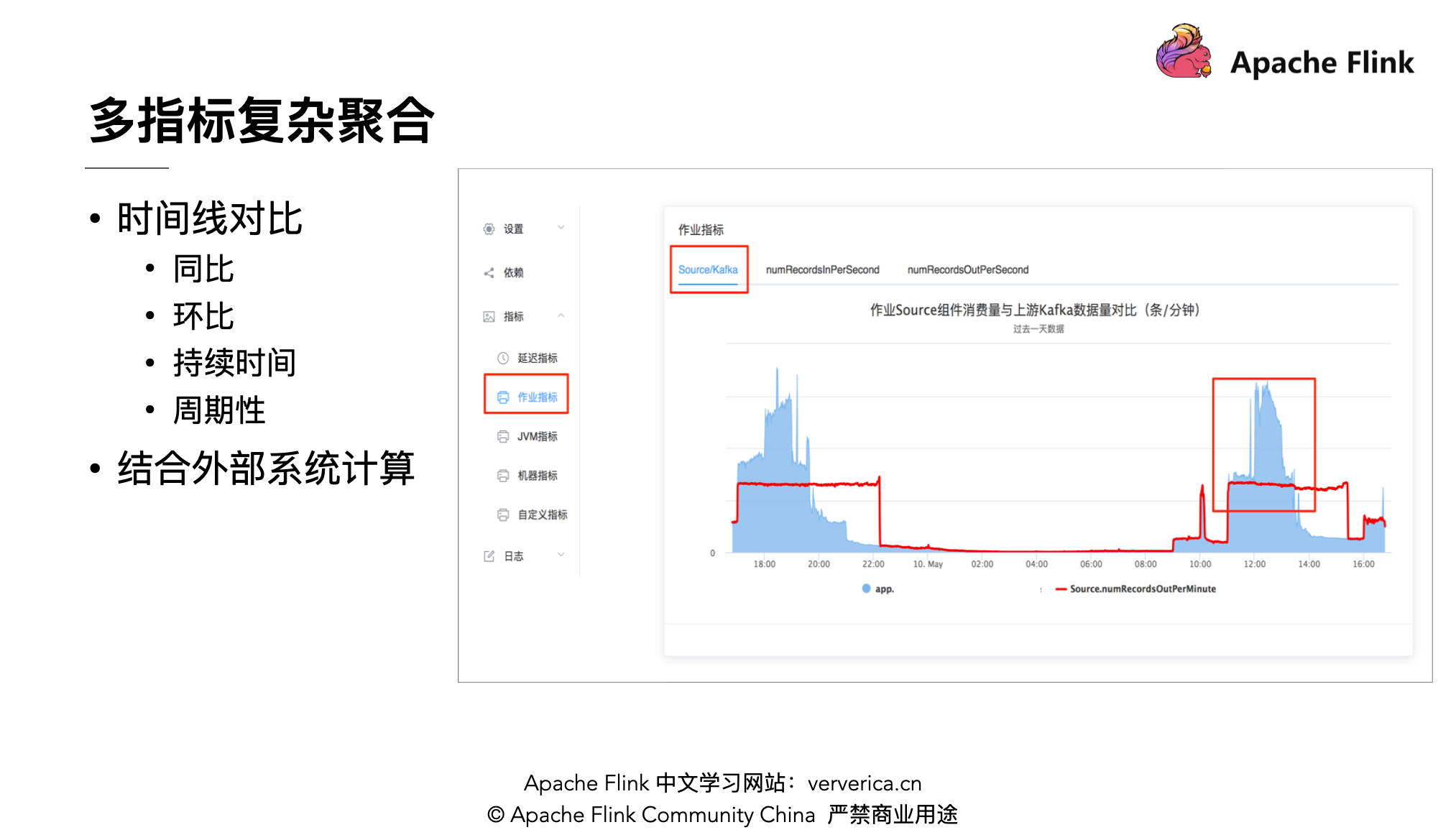
最后是在观察指标的时候可能需要多个指标复杂聚合查询,如常见的时间线对比,例如之前正常的作业在今天出现反压,可以通过查询今天数据量的同比昨天数据量的增长。另外不同的业务有不同的趋势,例如外卖存在高峰时间段,可以对比数据量在高峰时间段的环比增长来进行衡量。还有关注的指标的持续时间,如作业的数据延迟,如果延迟时间较长则作业可能存在异常;还有指标的周期性,如果指标的变化存在周期性,则考虑是否因为时间窗口的影响。
还有需要考虑的是结合外部系统进行计算,例如上游为消费 Kafka ,除了想知道当前消费的状况,还想查看上游的数据量。例如该图中,蓝线为上游 Kafka 的数据量,红线为作业的 source 算子的 output 数据量,可以看到在午高峰和晚高峰基本上是持平的状态, 上游数据在午高峰及晚高峰有较高的增长,虽然在高峰时刻有反压,但主要原因是由于上游数据量的增长而不是由于作业的处理能力不足。如果上游有多个算子可以将多个算子的数据量进行相加,这也是我们除了使用 Grafana 外还自研的前端进行展示的原因,自研前端可以将指标更加灵活的进行展示。
4. 指标监控的应用
4.1 作业异常报警
4.2 指标大盘
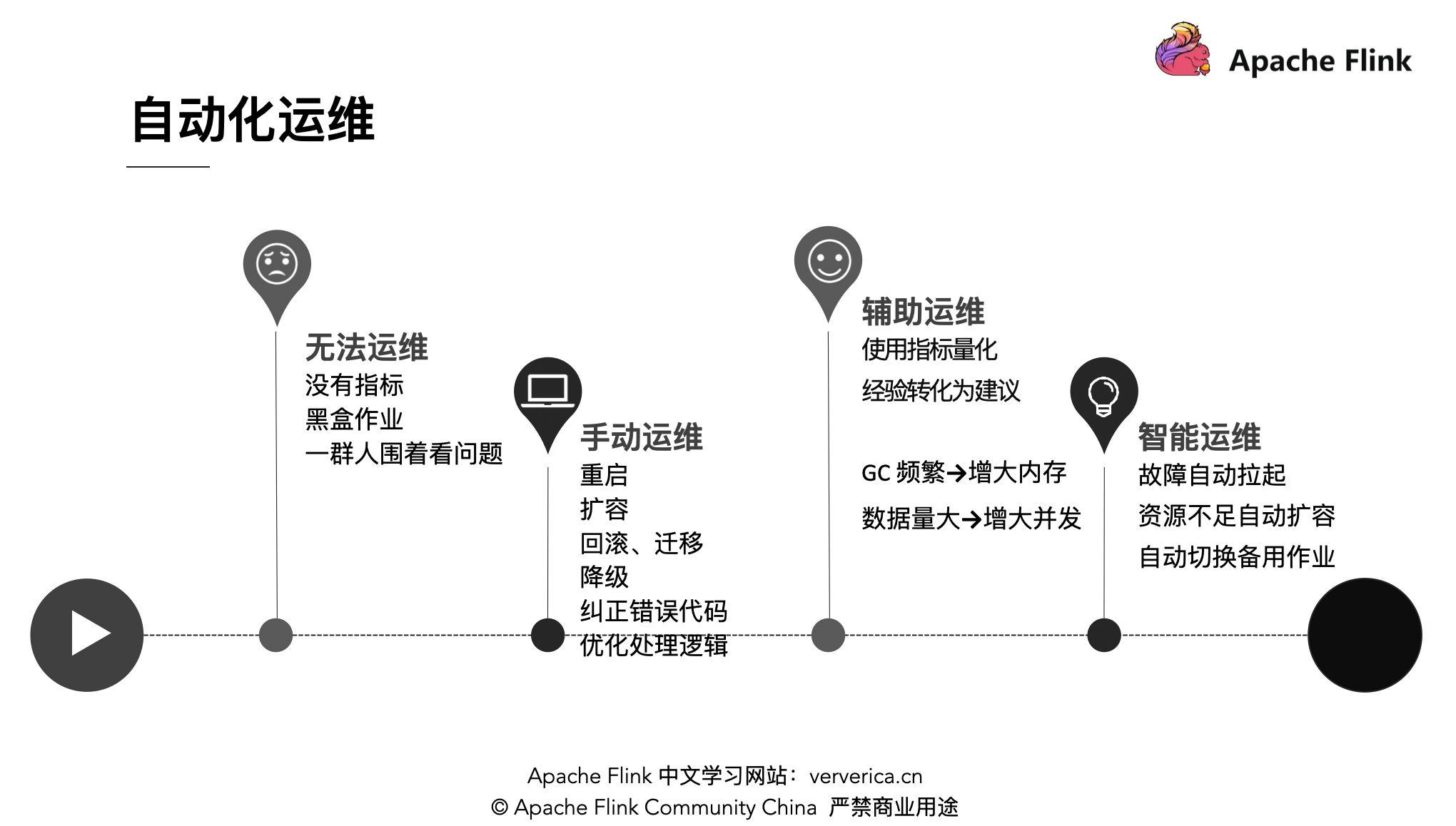
4.3 自动化运维
运维的几种阶段:
Q1:构建一整套指标系统,指标库如何维护?需要去对程序进行代码级别的修改,还是修改配置即可?
A:既然想做一整套的监控系统自然希望这个指标尽可能是一个可适配的方式,那么我们需要做什么?
Q2:Grafana 平台的展示效果很好,但是报警不友好;报警这块有比较成熟的工具吗?
A:可以看看 Prometheus,报警还是挺成熟的。报警比指标聚合更需要个性化的东西,如果需要功能非常完善的话,可能都需要考虑自研。
Q3:算子内部可以获取到 taskManager 的指标吗?
A:通过 restful API 去拿,不推荐在算子内部做,指标这个东西本身不应该影响你作业本身的处理逻辑,监控应该是一个比较外围的东西。
Q4:如何根据指标发现作业问题的根源?
A:按照指标从粗到细,可以参考 2.8 节和 3.1 节老师的教程。
Q5:指标数据量比较大,如何选择存储?
A:可以选择 openTSDB,其他 TSDB 也是可以的,像其他 Hive 或者 OLAP 引擎 也是可以考虑的,指标数据作为一种时序数据,目前已有很多成熟的方案可以选择。
点「此链接」可回顾作者分享视频~
推荐阅读:
Apache Flink 零基础入门到进阶系列文章