Caused by: org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /user/hadoop/output/20201023040000/tablename/normal/_temporary/0/_temporary/attempt_20201103002533_0146_m_001328_760289/event_date=2020-10-22 03%3A00%3A00/part-01328-7c2e85a0-dfc8-4d4d-8d49-ed9b6aca06f6.c000.zlib.orc could only be written to 0 of the 1 minReplication nodes. There are 1>Data Node Log:365050 java.io.IOException: Xceiver count 4097 exceeds the limit of concurrent xcievers: 4096365051 at org.apache.hadoop.hdfs.server.datanode.DataXceiverServer.run(DataXceiverServer.java:150)365052 at java.lang.Thread.run(Thread.java:748)dfs.datanode.max.transfer.threads = 16384Scala 升级到 2.12
由于 Spark 3.0 不再支持 Scala 2.11 版本,需要将所有的代码升级到 2.12 的版本。更多 Scala 2.12 的新的发布内容可以参考文档。
其他相关调整
整体使用的集群内存在升级 3.0 后有明显的降低,Data Pipelines 根据新的资源需用量重新调整了根据文件大小计算集群资源大小的算法。
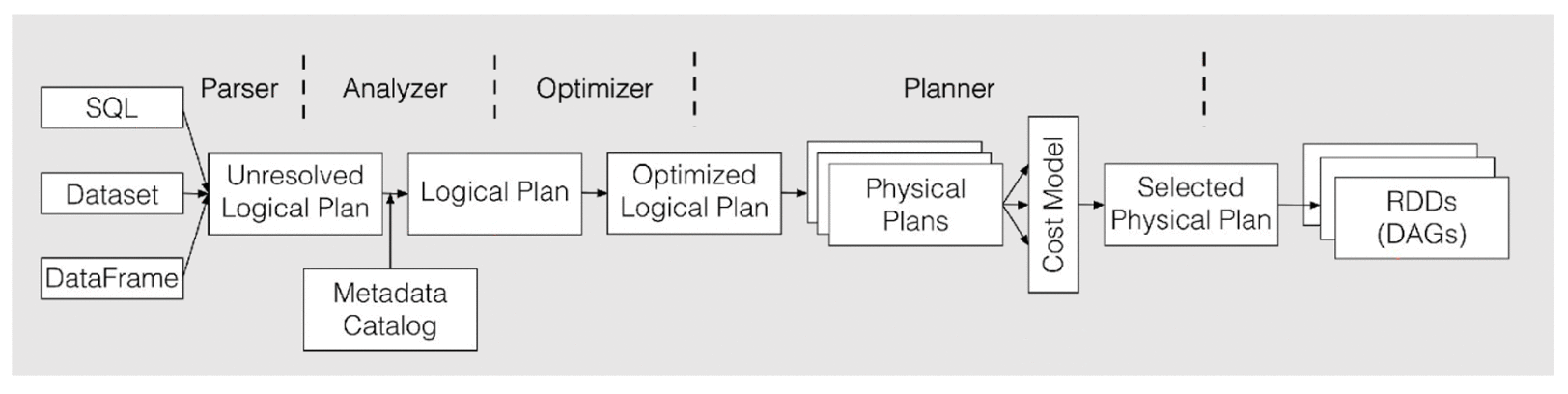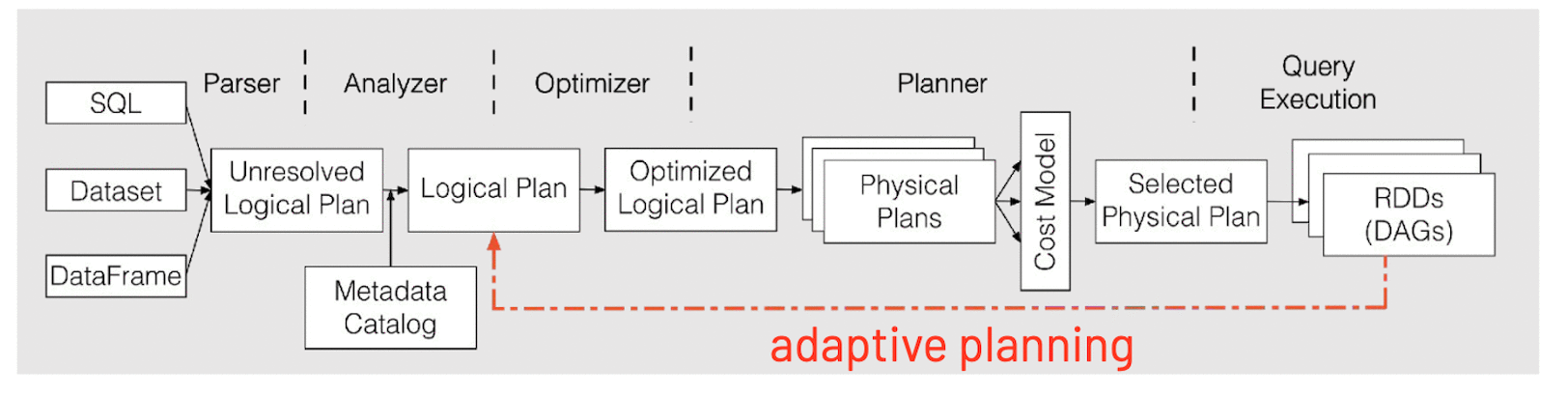
为什么既能提升性能又能省钱?
我们来仔细看一下为什么升级到 3.0 以后可以减少运行时间,又能节省集群的成本。 以 Optimus 数据建模里的一张表的运行情况为例:
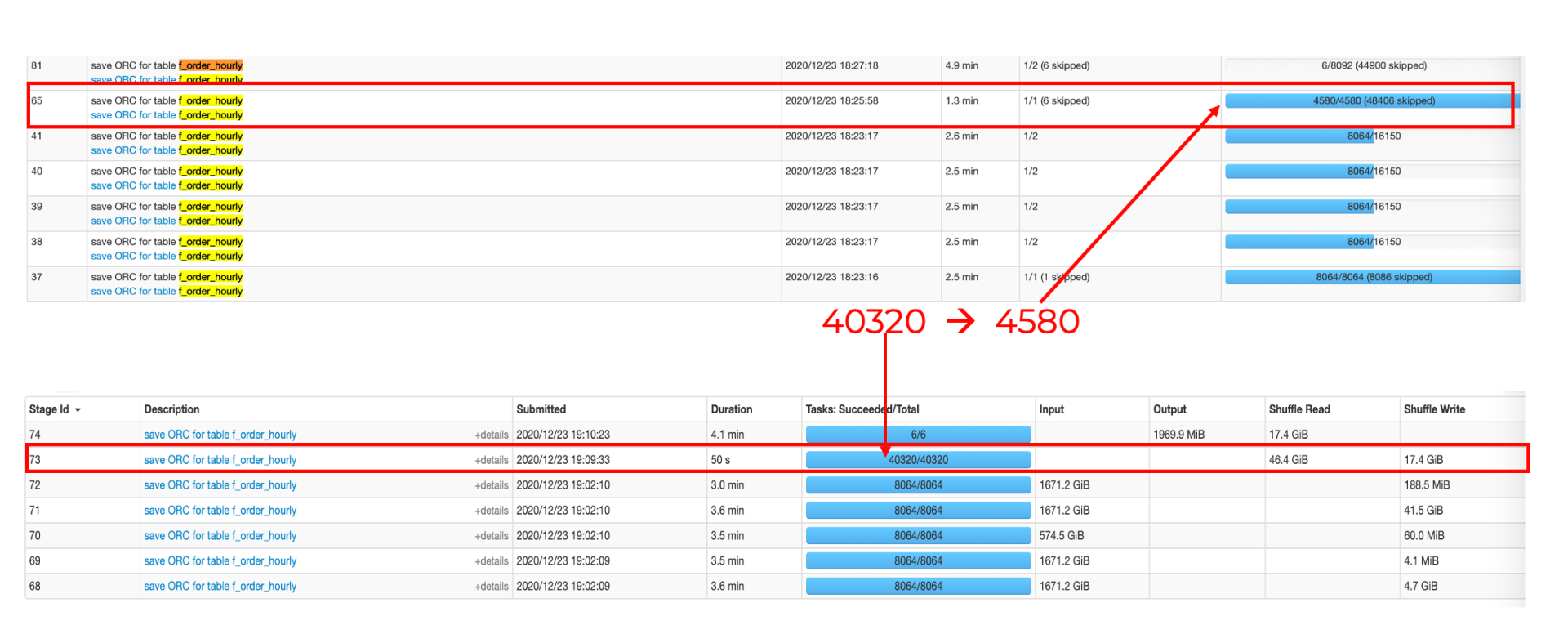
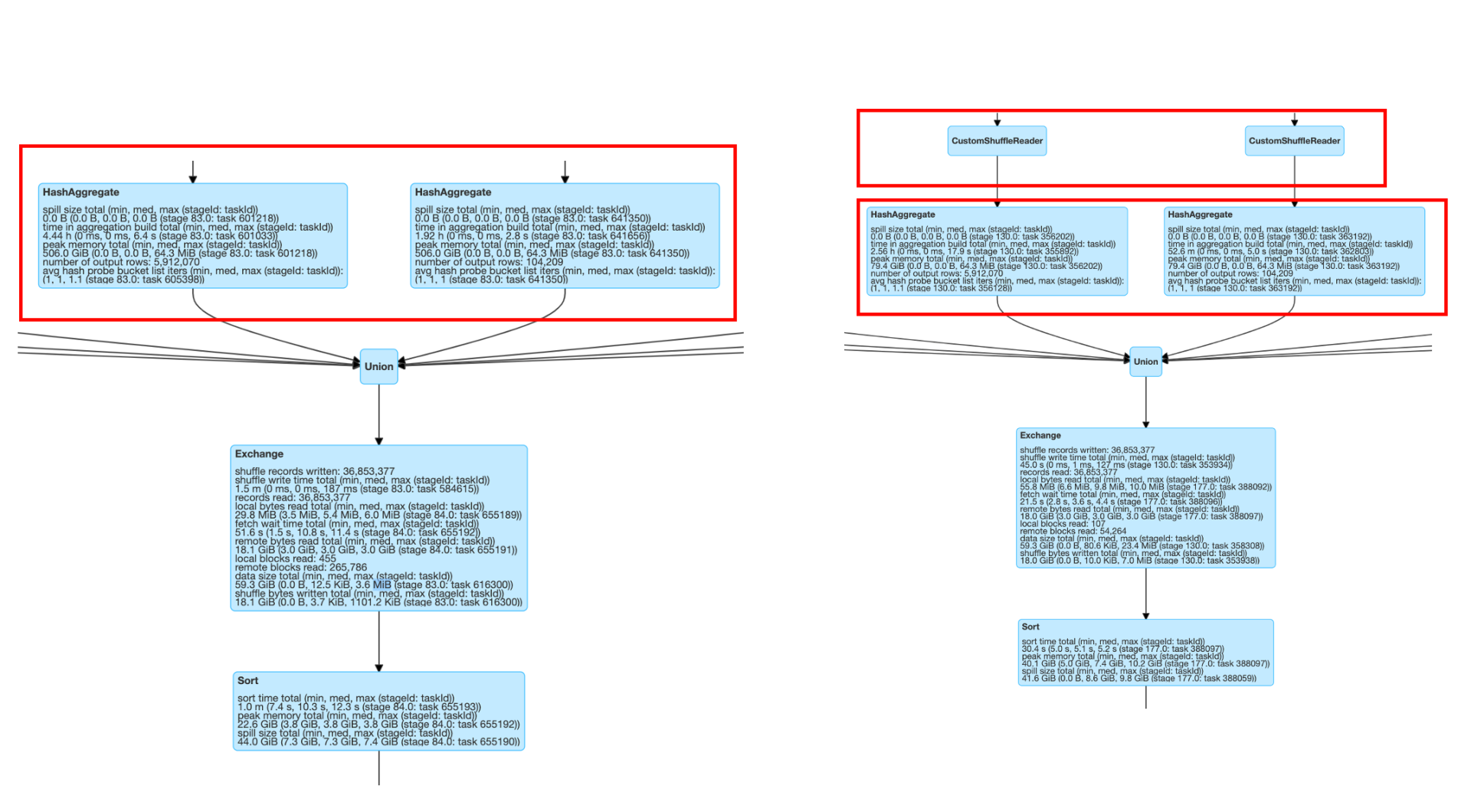
原因分析 :
而且由于 Spark Context 整个任务的并行度,需要一开始设定好且没法动态修改,这就很容易出现任务刚开始的时候数据量大需要大的并行度,而运行的过程中通过转化过滤可能最终的数据集已经变得很小,最初设定的分区数就显得过大了。AQE 能够很好的解决这个问题,在 reducer 去读取数据时,会根据用户设定的分区数据的大小(
spark.sql.adaptive.advisoryPartitionSizeInBytes
)来自动调整和合并()小的 partition,自适应地减小 partition 的数量,以减少资源浪费和 overhead,提升任务的性能。
综上所述,
Spark任务得到端到端的加速 + 集群资源使用降低 = 提升性能且省钱
。
未来展望
接下来,团队会继续紧跟技术栈的更新,并持续对>
最后特别感谢 AWS EMR 和 Support 团队在升级的过程中给予的快速响应和支持。
作者介绍
肖红梅,毕业于北京大学,曾任职于微策略,美团,Pegasus 大数据公司,具备丰富大数据开发与调优、大数据产品分析、数据仓库/建模、项目管理及敏捷开发的经验。现担任 Comcast FreeWheel 核心业务数据 Transformer 团队负责人,主要负责基于大数据>