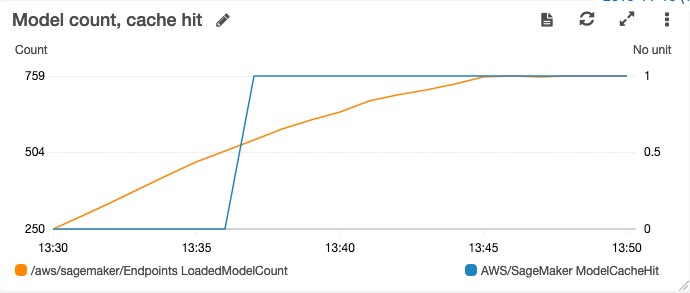
要为推理任务选择正确的实例类型,我们需要在不同数量的 GPU、CPU 以及内存资源之间做出权衡。在独立 GPU 实例上针对其中某一种资源进行优化,往往会导致其他资源得不到充分利用。Elastic Inference 则能够为特定端点提供适量的 GPU 驱动型推理加速资源,解决了这一难题。自 2020 年 3 月起,用户已经可以在 Amazon SageMaker 与 Amazon EC2 上获得 Elastic Inference 对 PyTorch 的支持能力。

要为推理任务选择正确的实例类型,我们需要在不同数量的 GPU、CPU 以及内存资源之间做出权衡。在独立 GPU 实例上针对其中某一种资源进行优化,往往会导致其他资源得不到充分利用。Elastic Inference 则能够为特定端点提供适量的 GPU 驱动型推理加速资源,解决了这一难题。自 2020 年 3 月起,用户已经可以在 Amazon SageMaker 与 Amazon EC2 上获得 Elastic Inference 对 PyTorch 的支持能力。