随着伴鱼业务的快速发展,离线数据日渐无法满足运营同学的需求,数据的实时性要求越来越高。之前的实时任务是通过实时同步至 TiDB 的数据,利用 TiDB 进行微批计算。随着越来越多的实时场景涌现出来,TiDB 已经无法满足实时数据计算场景,计算和查询都在一套集群中,导致集群压力过大,可能影响正常的业务使用。根据业务形态搭建实时数仓已经是必要的建设了。伴鱼实时数仓主要以 Flink 为计算引擎,搭配 Redis ,Kafka 等分布式数据存储介质,以及 ClickHouse 等多维分析引擎。
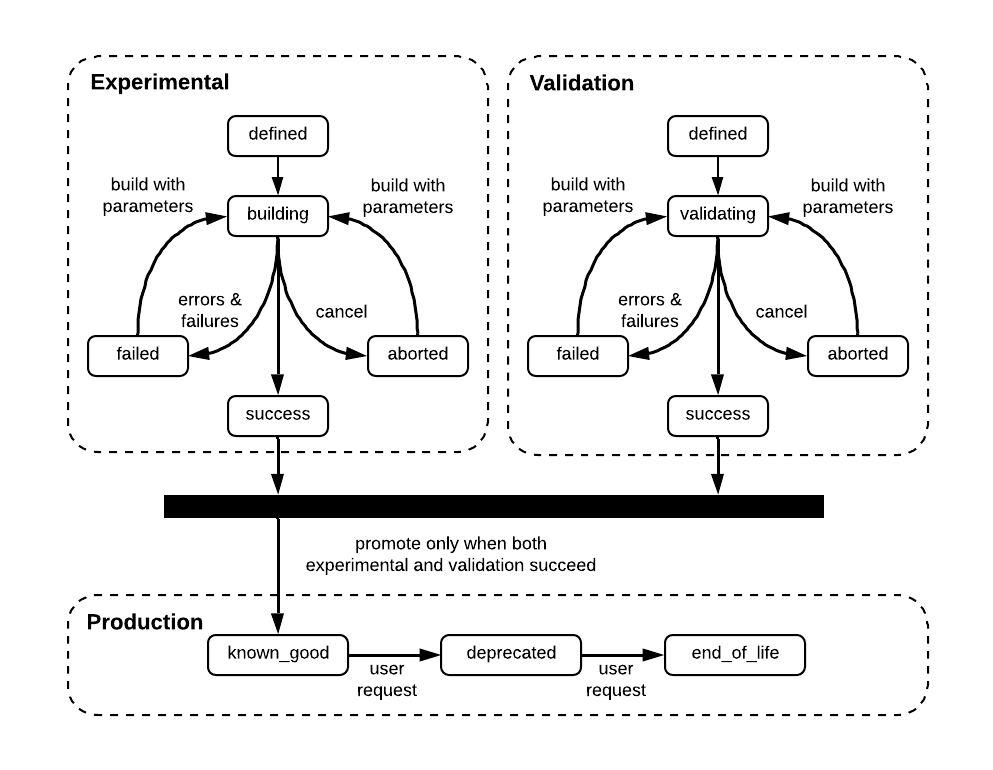
伴鱼实时作业应用场景
基于平台提供了稳定的环境(统一调度方式,统一管理,统一监控等)。我们构建了一些实时服务,通过服务化的方式去支持各个业务方。
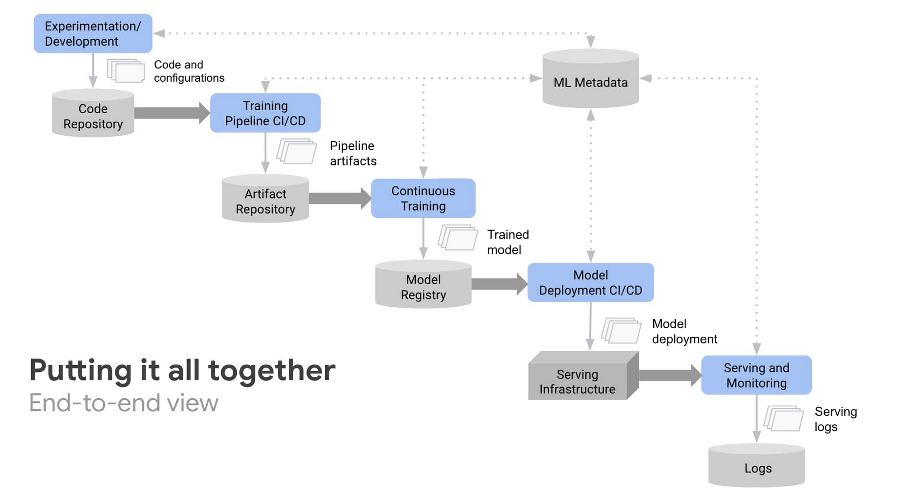
简单介绍下:目前数据在伴鱼内的流动架构图:
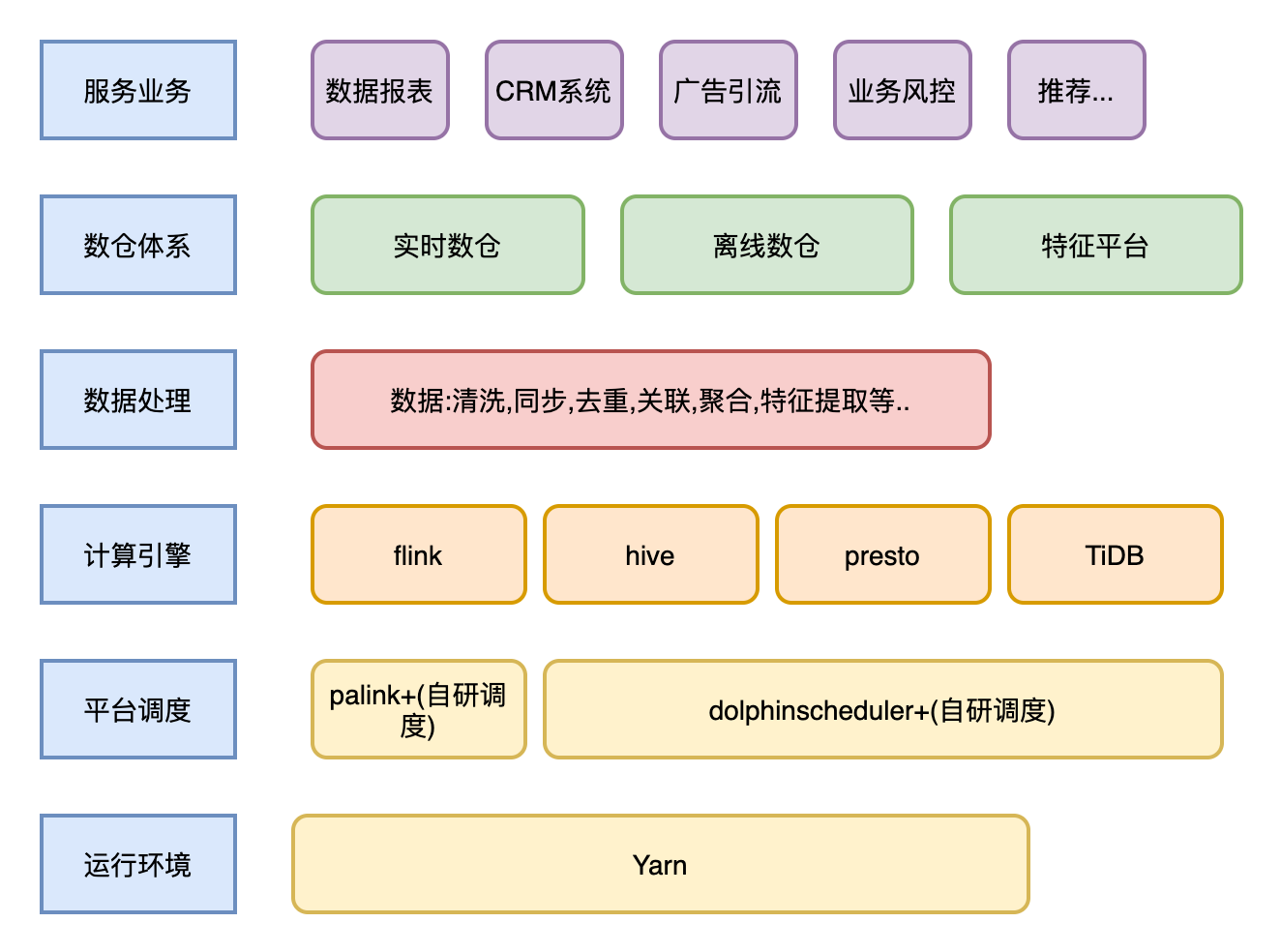
下面主要介伴鱼实时数仓的建设体系
如图:
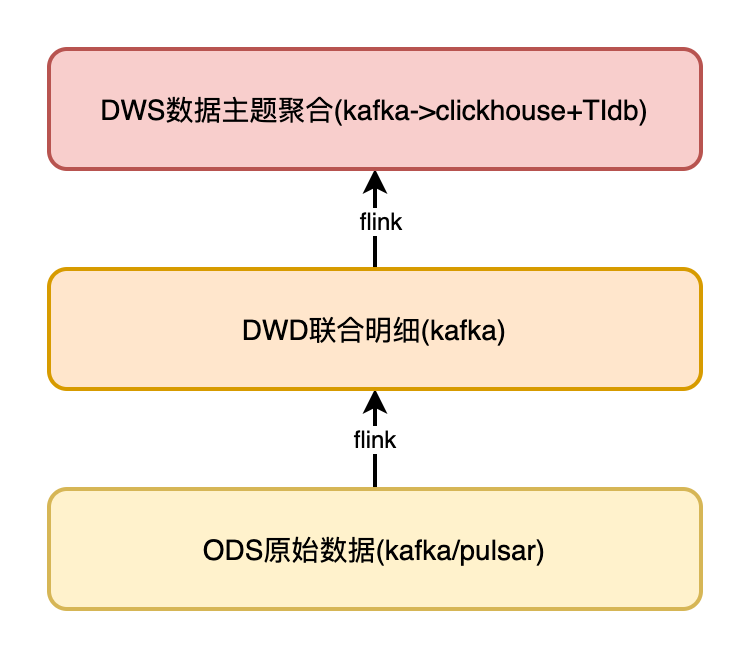
DWD 层复杂场景数据处理方案
数据从 ODS 层采集后,数据的处理和加工主要集中在 DWD 层,我们的场景中面临了很多复杂的加工逻辑,本章重点对 DWD 层数据处理方案进行详细的阐述。
1. 数据的去重
由于伴鱼内部业务大面积使用 MongoDB ,MongoDB 本身存储的是半结构化的数据,它不具有固定的 schema 。在同步 Mongo 的 oplog 时,实时数仓的 dwd 层并不需要所有字段参与,我们只会抽取日常使用率相对较高的字段进行表建设。这就可能由于不相干的数据发生变化,我们也会收到一条相同的数据记录。例如在对用户订单金额进行分类分析时,如果用户订单地址发生了变化,我们同样也会收到一条业务日志,因为我们并不关注地址维度,所以这条日志是无用的重复数据。这种未经处理的数据是不方便 BI 工程师直接使用的,甚至直接影响计算结果的准确性。所以我们针对这种非 Append-only 数据,我们进行了定制化的日志格式。在经由平台方解析后的 binlog 或者 oplog ,我们仍然定制化加入了一些元数据信息,用来让 BI 工程师更好的理解这条数据进入实时计算引擎时,对应的时间点到底发生了什么事情,这件实事到底是否参与计算。所以,我们加入了 metadata_table (原始表名), metadata_changes(修改字段名) , metadata_op_type (DML 类型) ,metadata_commit_ts (修改时间戳)等字段,辅助我们对业务上认为的重复数据,做更好的过滤。
如图:

2. join 场景
实时计算相较于离线不同,因为数据具有一过性,流过的数据,如果不做特殊记录,很难在找回,从而降低了实时作业准确性,这是实时计算的一个痛点问题,这个问题主要表现在多流关联时,数据难以关联准确,下面叙述一下在伴鱼内部,多流 join 的场景是如何解决的。数据关联常用的 inner join ,left join 。inner join 近似可以看做 left join + where 的操作。
从时间角度来讲分为:
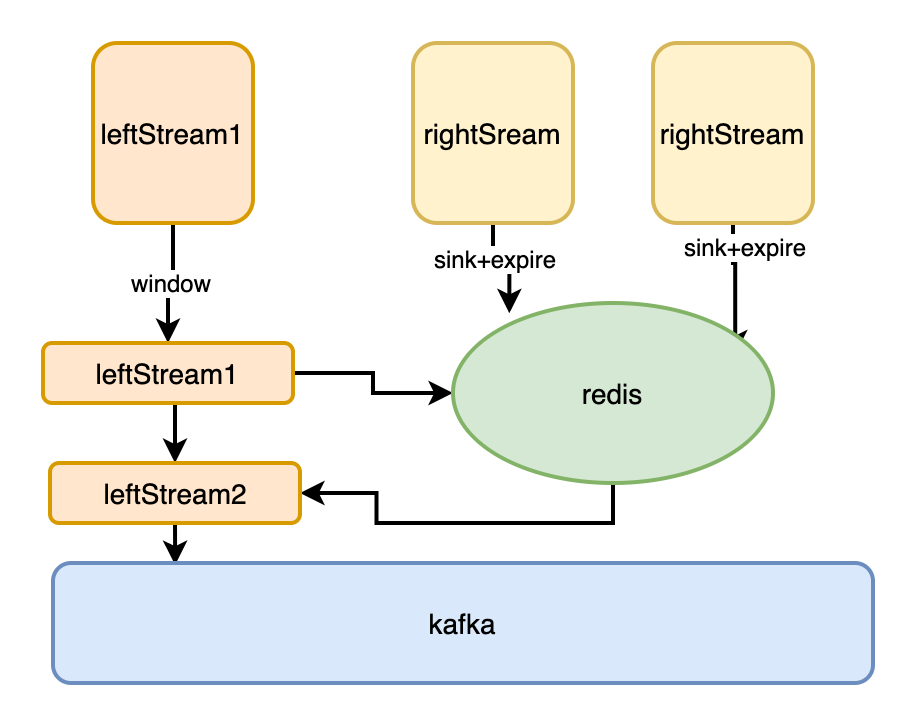
两条实时数据流相关联
利用 Redis 基于内存,支持单位时间大量 QPS ,快速访问的特性:
如图:
Flink 作业内部,提供了完整的 user-state 状态管理,包括状态初始化,状态更新,状态快照,以及状态恢复等:
Flink 社区已经认识到多流 join 的痛点问题,提供了区别于离线 sql 的特殊 join 方式:
如图:

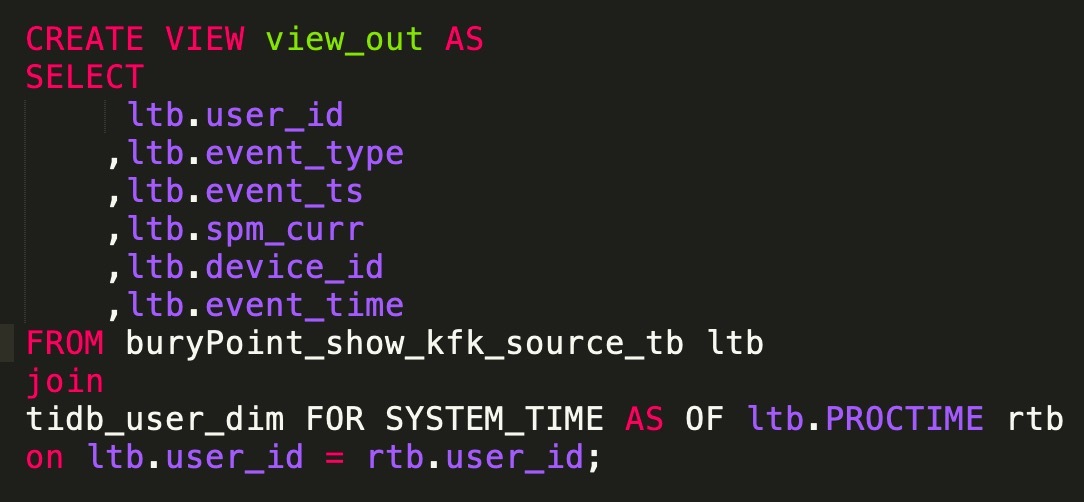
Flink Table & SQL 时态表 Temporal Table:
Temporal Table 可提供历史某个时间点上的数据。Temporal Table 根据时间来跟踪版本。Temporal Table 需要提供时间属性和主键。Temporal Table 一般和关键词 LATERAL TABLE 结合使用。Temporal Table 在基于 ProcessingTime 时间属性处理时,每个主键只保存最新版本的数据。Temporal Table 在基于 EventTime 时间属性处理时,每个主键保存从上个 Watermark 到当前系统时间的所有版本。Append-Only 表 Join 右侧 Temporal Table ,本质上还是左表驱动 Join ,即从左表拿到 Key ,根据 Key 和时间(可能是历史时间)去右侧 Temporal Table 表中查询。Temporal Table Join 目前只支持 Inner Join。Temporal Table Join 时,右侧 Temporal Table 表返回最新一个版本的数据。例如:
对于关联历史数据
3. 从数据形态观查 join
从数据 join 的方式来看,共分为三种,一对一,多对一,多对多三种情形。
DWS 数据层数据处理方案
我们在离线数仓中通常存放的是跨业务域的粗粒度数。在伴鱼的实时数仓内部,我们也同样是这样存储的。只不过跨业务域的数据之间的关联,我们不在 Flink 实时处理引擎中做计算。而是把它们放到 TiDB 或者 ClickHouse 中做计算了。在 Flink 内存,我们只计算当前业务域的聚合指标,以及会对数据进行 tag 标记,标记出数据是按哪些维度聚合而来,聚合粒度是如何的。(例如时间粒度上,我们通常会以 5min 或者 10min 为小单位对数据进行聚合),如果要查询当天跨业务的联合数据时,会基于 TiDB 或者 ClickHouse 预先定义好视图,在视图内先对当天单个业务域主题内数据先做聚合 sum ,再将不同业务域的数,按提前在数据中标记的维度 tag 进行关联,得到跨业务的聚合指标。
未来与展望
参考文献:
作者:李震
原文:原文:Flink 在伴鱼的实践:如何保障数据的准确性