前言
在伴鱼,我们在多个在线场景使用机器学习提高用户的使用体验,例如:在伴鱼绘本中,我们根据用户的帖子浏览记录,为用户推荐他们感兴趣的帖子;在转化后台里,我们根据用户的绘本购买记录,为用户推荐他们可能感兴趣的课程等。
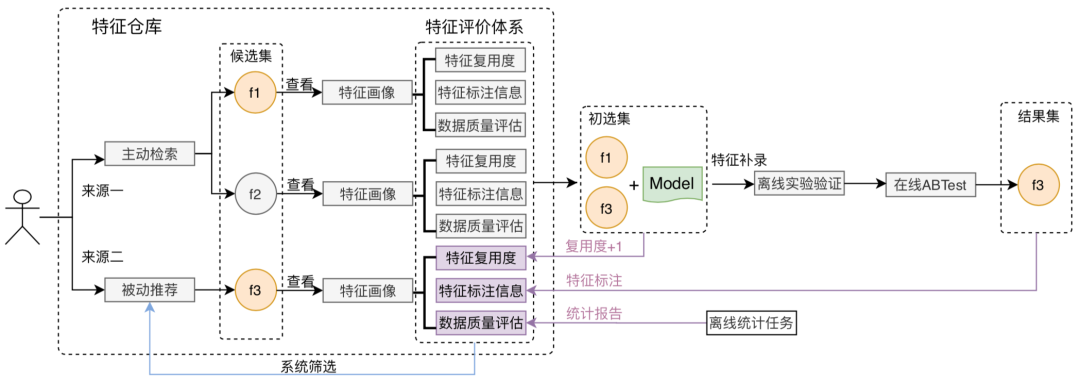
特征是机器学习模型的输入。如何高效地将特征从数据源加工出来,让它能够被在线服务高效地访问,决定了我们能否在生产环境可靠地使用机器学习。为此,我们搭建了特征系统,系统性地解决这一问题。目前,伴鱼的机器学习特征系统运行了接近 100 个特征,支持了多个业务线的模型对在线获取特征的需求。
下面,我们将介绍特征系统在伴鱼的演进过程,以及其中的权衡考量。
特征系统 V1
特征系统 V1 由三个核心组件构成:特征管道,特征仓库,和特征服务。整体架构如下图所示:
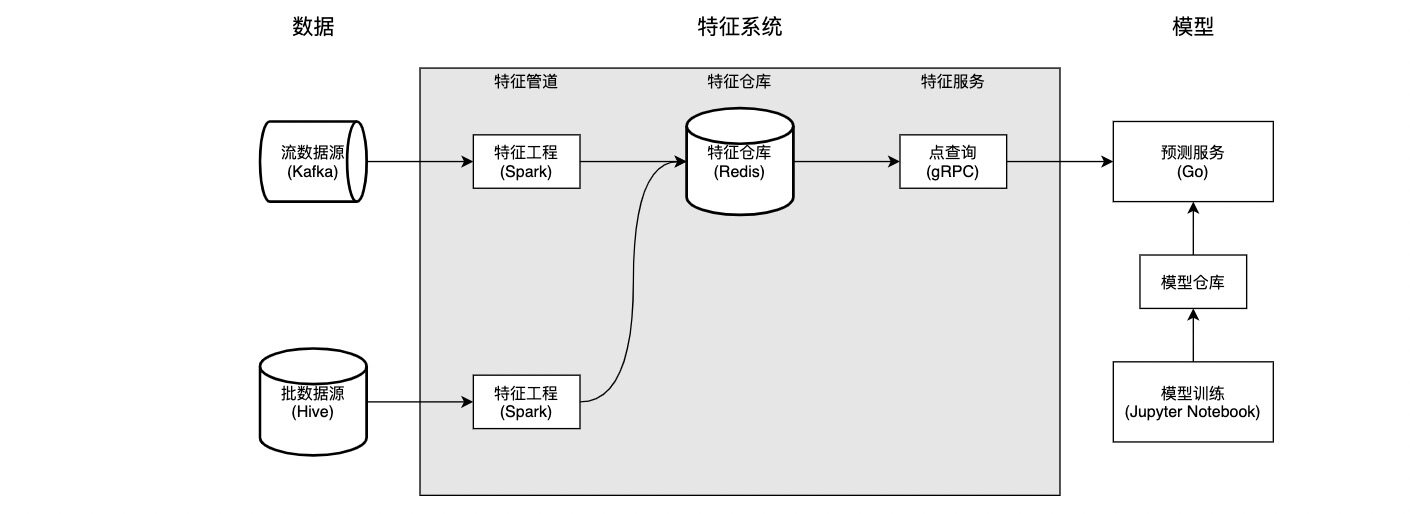
特征管道包括流特征管道和批特征管道,它们分别消费流数据源和批数据源,对数据经过预处理加工成特征(这一步称为特征工程),并将特征写入特征仓库。批特征管道使用实现,由 DolphinScheduler 进行调度,跑在 YARN 集群上。出于技术栈的一致考虑,流特征管道使用 Spark Structured Streaming 实现,和批特征管道一样跑在 YARN 集群上。
特征仓库选用合适的存储组件(Redis)和数据结构(Hashes),为模型服务提供低延迟的特征访问能力。之所以选用 Redis 作为存储,是因为:
特征服务屏蔽特征仓库的存储和数据结构,对外暴露 RPC 接口
GetFeatures(EntityName, FeatureNames)
,提供对特征的低延迟点查询。在实现上,这一接口基本对应于 Redis 的
HMGET EntityName FeatureName_1 ... FeatureName_N
操作。
这一版本的特征系统存在几个问题:
为了解决这几个问题,特征系统 V2 提出几个设计目的:
特征系统 V2
特征系统 V2 相比特征系统 V1 在架构上的唯一不同点在于,它将特征管道切分为三部分:特征生成管道,特征源,和特征注入管道。值得一提的是,管道在实现上均从 Spark 转为 Flink,和公司数据基础架构的发展保持一致。特征系统 V2 的整体架构如下图所示:
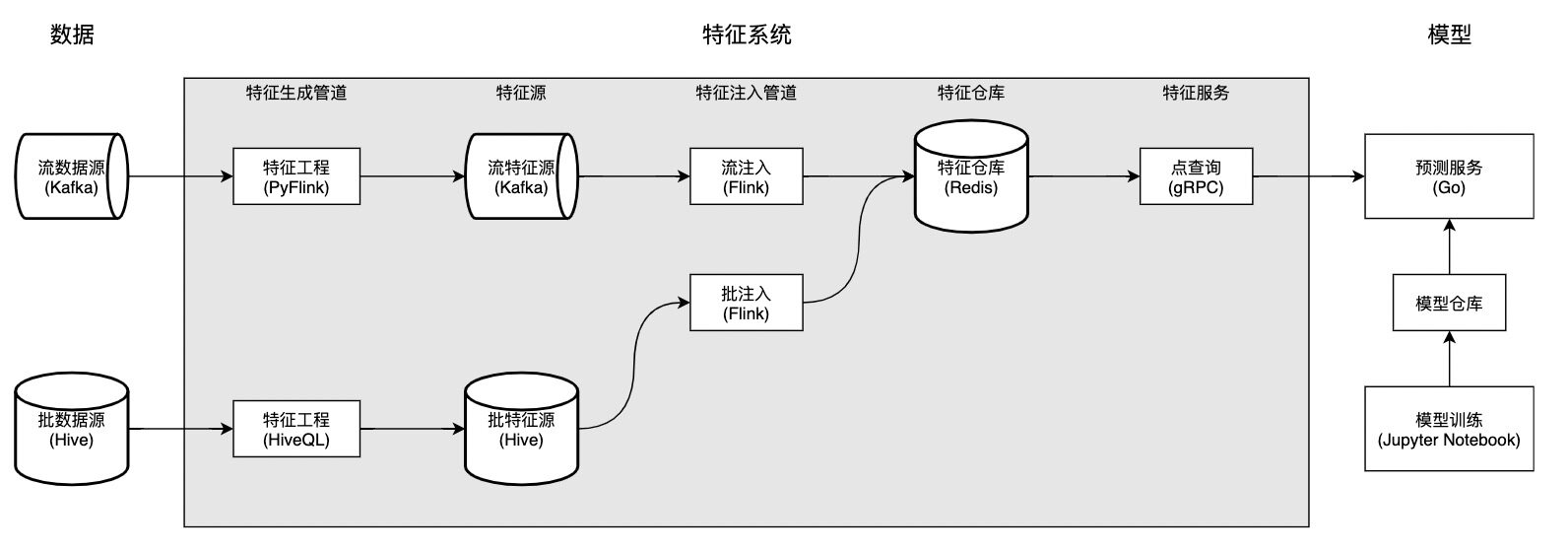
特征生成管道读取原始数据源,加工为特征,并将特征写入指定特征源(而非特征仓库)。如果管道以流数据源作为原始数据源,则它是流特征生成管道;如果管道以批数据源作为原始数据源,则它是批特征生成管道。
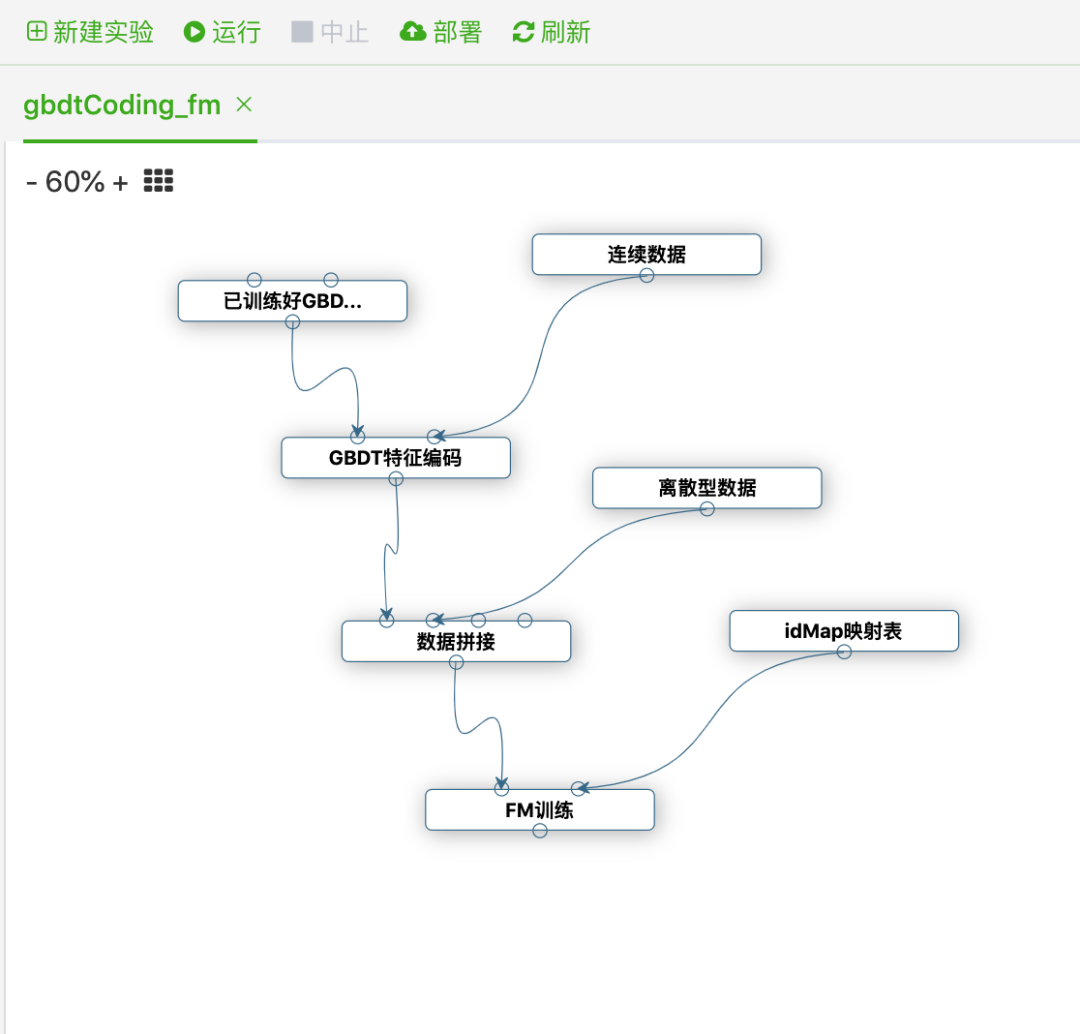
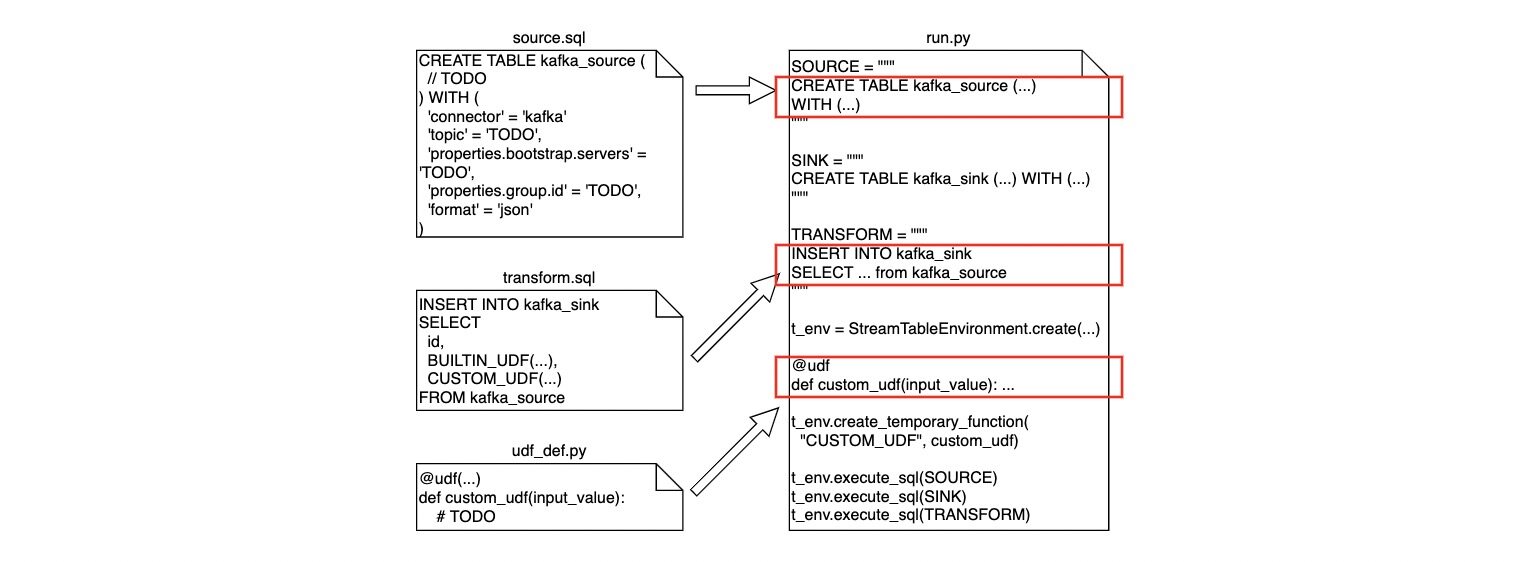
特征生成管道的逻辑由算法工程师全权负责编写。其中,批特征生成管道使用 HiveQL 编写,由 DolphinScheduler 调度。流特征生成管道使用 PyFlink 实现,详情见下图。
算法工程师需要遵守下面步骤:
这一套流程确保了:
特征源存储从原始数据源加工形成的特征。值得强调的是,它同时还是连接算法工程师和 AI 平台工程师的桥梁。算法工程师只负责实现特征工程的逻辑,将原始数据加工为特征,写入特征源,剩下的事情就交给 AI 平台。平台工程师实现特征注入管道,将特征写入特征仓库,以特征服务的形式对外提供数据访问服务。
特征注入管道将特征从特征源读出,写入特征仓库。由于 Flink 社区缺少对 Redis sink 的原生支持,我们通过拓展RichSinkFunction简单地实现了
StreamRedisSink
和
BatchRedisSink
,很好地满足我们的需求。其中,
BatchRedisSink
实现了批量写入,大幅减少对 Redis server 的请求量,增大吞吐,将写入效率提升了 7 倍,见博客。
特征系统 V2 很好地满足了我们提出的设计目的。
总结
特征系统 V1 解决了特征上线的问题,而特征系统 V2 在此基础上,解决了特征上线难的问题。在特征系统的演进过程中,我们总结出作为平台研发的几点经验:
作者:陈易生
原文:原文:机器学习特征系统在伴鱼的演进