

创新工场“数据下毒”论文入选 NeurIPS
近年来,机器学习热度不断攀升,并逐渐在不同应用领域解决各式各样的问题。不过,却很少有人意识到,其实机器学习本身也很容易受到攻击,模型并非想象中坚不可摧。
例如,在训练(学习阶段)或是预测(推理阶段)这两个过程中,机器学习模型就都有可能被对手攻击,而攻击的手段也是多种多样。创新工场 AI 工程院为此专门成立了 AI 安全实验室,针对人工智能系统的安全性,进行了深入对评估和研究。
“Learning to Confuse: Generating Training Time Adversarial>
顾名思义,“数据下毒”即让训练数据“中毒”,具体的攻击策略是通过干扰模型的训练过程,对其完整性造成影响,进而让模型的后续预测过程出现偏差。
举例来说,假如一家从事机器人视觉技术开发的公司希望训练机器人识别现实场景中的器物、人员、车辆等,却不慎被入侵者利用论文中提及的方法篡改了训练数据。研发人员在目视检查训练数据时,通常不会感知到异常(因为使数据“中毒”的噪音数据在图像层面很难被肉眼识别),训练过程也一如既往地顺利。但这时训练出来的深度学习模型在泛化能力上会大幅退化,用这样的模型驱动的机器人在真实场景中会彻底“懵圈”,陷入什么也认不出的尴尬境地。更有甚者,攻击者还可以精心调整“下毒”时所用的噪音数据,使得训练出来的机器人视觉模型“故意认错”某些东西,比如将障碍认成是通路,或将危险场景标记成安全场景等。
为了达成这一目的,这篇论文设计了一种可以生成对抗噪声的自编码器神经网络 DeepConfuse,通过观察一个假想分类器的训练过程更新自己的权重,产生“有毒性”的噪声,从而为“受害的”分类器带来最低下的泛化效率,而这个过程可以被归结为一个具有非线性等式约束的非凸优化问题。
从实验数据可以发现,在 MNIST、CIFAR-10 以及缩减版的 IMAGENET 这些不同数据集上,使用“未被下毒”的训练数据集和“中毒”的训练数据集所训练的系统模型在分类精度上存在较大的差异,效果非常可观。

与此同时,从实验结果来看,该方法生成的对抗噪声具有通用性,即便是在随机森林和支持向量机这些非神经网络上也有较好表现。(其中蓝色为使用“未被下毒”的训练数据训练出的模型在泛化能力上的测试表现,橙色为使用“中毒”训练数据训练出的模型的在泛化能力上的测试表现)
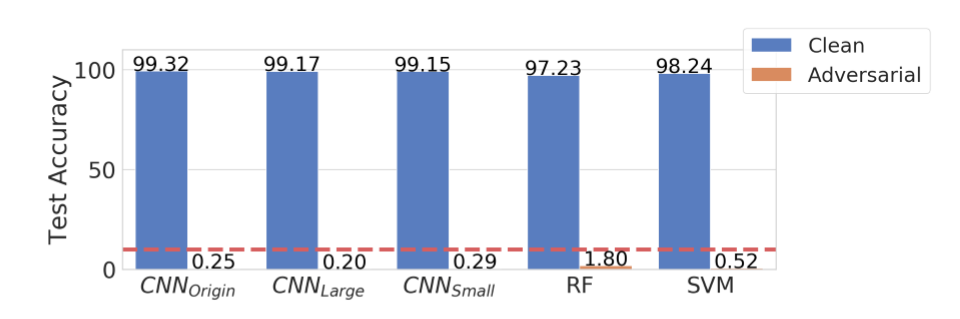
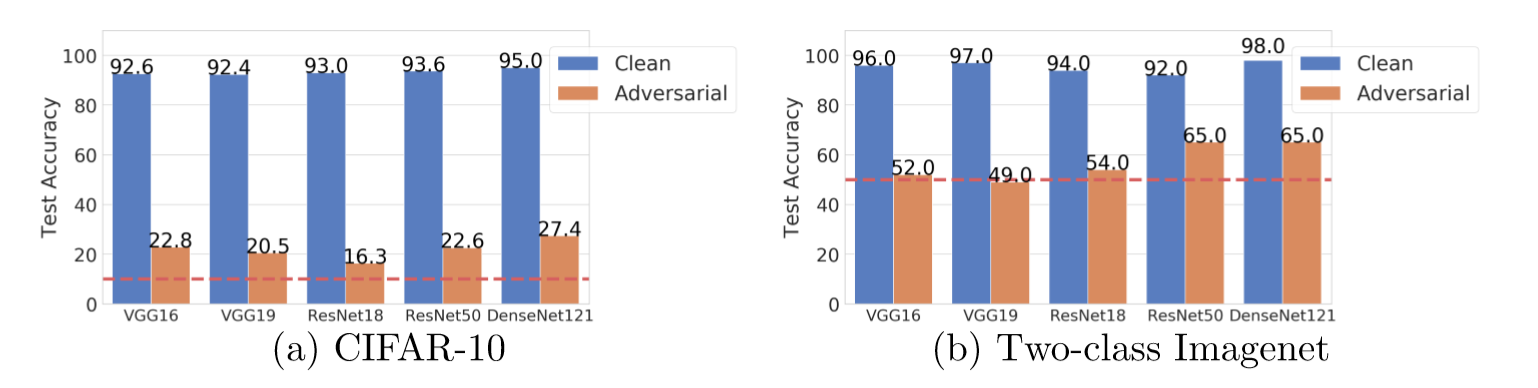
在 CIFAR 和 IMAGENET 数据集上的表现也具有相似效果,证明该方法所产生的对抗训练样本在不同的网络结构上具有很高的迁移能力。
此外,论文中提出的方法还能有效扩展至针对特定标签的情形下,即攻击者希望通过一些预先指定的规则使模型分类错误,例如将“猫”错误分类成“狗”,让模型按照攻击者计划,定向发生错误。
例如,下图为 MINIST 数据集上,不同场景下测试集上混淆矩阵的表现,分别为干净训练数据集、无特定标签的训练数据集、以及有特定标签的训练数据集。
实验结果证明了,为有特定标签的训练数据集做相应设置的有效性,未来有机会通过修改设置以实现更多特定的任务。
对数据“下毒”技术的研究并不单单是为了揭示类似的 AI 入侵或攻击技术对系统安全的威胁,更重要的是,只有深入研究相关的入侵或攻击技术,才能有针对性地制定防范“AI 黑客”的完善方案。
联邦学习对 AI 安全研发提出新的目标
除了安全问题之外,人工智能应用的数据隐私问题,也是创新工场 AI 安全实验室重点关注的议题之一。 近年来,随着人工智能技术的高速发展,社会各界对隐私保护及数据安全的需求加强,联邦学习技术应运而生,并开始越来越多地受到学术界和工业界的关注。
具体而言,联邦学习系统是一个分布式的具有多个参与者的机器学习框架,每一个联邦学习的参与者不需要与其余几方共享自己的训练数据,但仍然能利用其余几方参与者提供的信息更好的训练联合模型。换言之,各方可以在在不共享数据的情况下,共享数据产生的知识,达到共赢。
创新工场 AI 工程院十分看好联邦学习技术的巨大应用潜力,今年 3 月,“Learning to Confuse: Generating Training Time Adversarial top="2856.4375">论文作者
冯霁(创新工场南京国际人工智能研究院执行院长)、 蔡其志(创新工场南京国际人工智能研究院研究员) 、周志华(南京大学人工智能学院院长)




