
前 言
近一年以来,自 H2O 起,关于 KV 稀疏的论文便百花齐放,而在实际应用中不得不面临的一个问题便是学术论文与实际应用之间的巨大鸿沟,例如 vLLM 等框架采用的是 PagedAttention 等分页内存,与大部分的稀疏算法都无法与之兼容或者本身性能不如 PagedAttention,类似的种种问题,导致了稀疏算法无法真正的在生产中应用。
我们参考 KV 稀疏这一方向最近一年的学术论文,结合 vLLM 框架本身的优化特性,例如 Continuous Batching、FlashAttention、PagedAttention 等,对 VLLM 框架进行基于 KV 稀疏的修改,最终基于线上最常用的模型、参数与硬件,与 sota 版本的推理框架进行对比,实现了 1.5 倍的推理加速。
说到 KV 稀疏之前,不得不说的便是 LLM 的 Massive Activations 特性,即在 LLM 中有很少数的激活值明显活跃于其他的激活,有时候高于其他激活 100,000 倍以上,换而言之,即少部分的 token 起到了至关重要的作用,因而可以通过 KV 稀疏方法(即保留重要的 token)来提升推理性能。
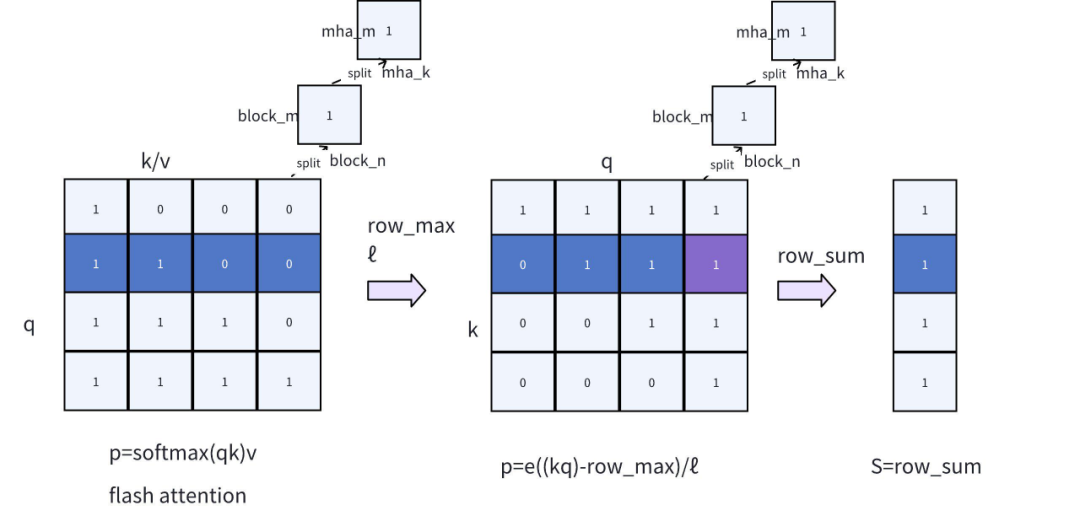
具体可以参考 Llama2 和 Llama3 的分析数据,如下图所示:
Llama3 与 Llama2 不同的是,Llama3 并不是所有的层都呈现出 Massive Activations 特性,在 lower layers 呈现出均匀分布特性,在 middle layers 呈现出 localized attention 特性,只有在 upper layers 才呈现出 Massive Activations 特性,这也是为什么 llama3 等模型要使用分层稀疏的原因。
介绍完 LLM 的 Massive Activations 特性,我们对于 KV 稀疏的原理已经有了基本的概念,接下来我们进入 KV 稀疏如何实现的内容。在整个大模型的推理过程中,显卡的容量、计算能力、IO 往往是推理的三大瓶颈,而为了避免重复计算而往往会缓存 KV,这样就导致推理的过程中 KV Cache 会导致大量的显存,同时计算量与 IO 也分别是 Prefill 和 Decode 两个阶段的重要瓶颈。
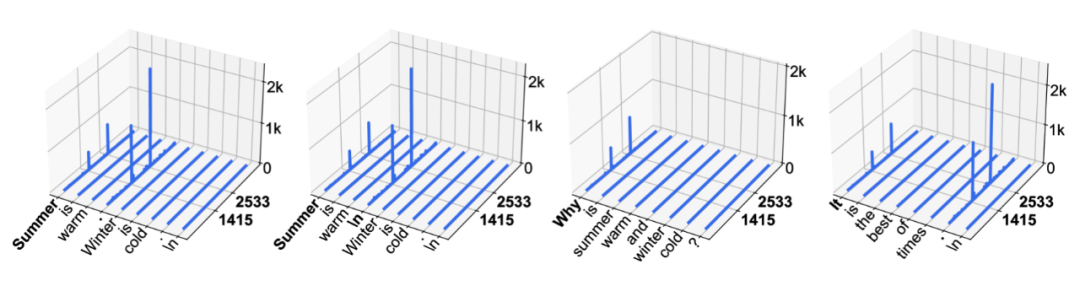
我们对 vLLM 的改造就是基于 LLM 的 Massive Activations 特性,来实现的分层稀疏(即不同层的稀疏程度不一样),从而大大降低 KV 开销,对 LLM 模型实现推理加速。
如上图所示,如果我们在推理的过程中,我们对模型的不同层分别进行 KV 稀疏,即通过淘汰策略将打分较低的 KV 进行删除,同时保留打分较高与距离较近的 KV,从而节约内存并同时降低计算量与 IO 开销,最终实现推理加速。
推理加速效果
大家最关注的莫过于 KV 稀疏在 vLLM 中的实际效果如何?我们先介绍一下性能评测的效果。
推理性能
在 LLM 的实际应用中,输入 / 输出长度为 4000/500 为最常见的长度,同时 RTX4090 显卡也是业界应用最广泛的显卡之一,我们在此基础上进行分批次的性能对比测试。对照组是 vLLM0.6.1.p2,实验组是 PPIO Sparse0.5.1(vLLM 0.5.1 的 kv 稀疏改造版本),两者进行多轮的性能对比测试,参考的主要指标为 TTFT(首 token 指标,影响用户体验)和 Throughput(吞吐量,实际的推理速度)。
最终的测试结果显示,通过 KV 稀疏,在保证 TTFT 可用的基础上(P50 在 1 秒之内),能将 vLLM 的吞吐量提升约 1.58 倍。
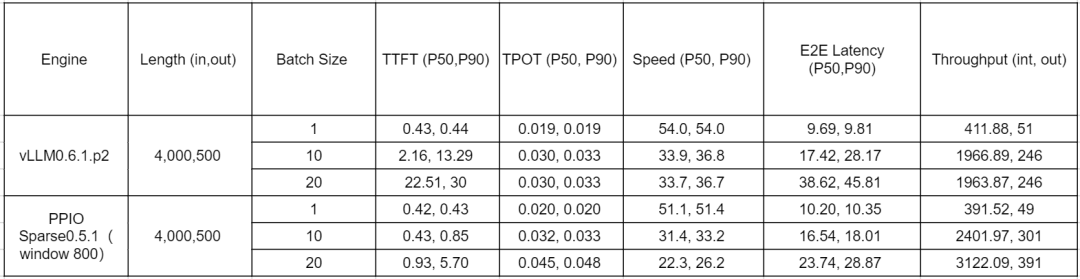
如上表所示,在较大 Batch Size 的场景下,vLLM0.6.1.p2 在并发度为 10 的情况下已经到达极限,而 PPIO Sparse0.5.1 在并发度为 20 的情况下依旧能保持 TTFT 性能稳定,从一定程度上保证了 KV 稀疏在实际生产中的性能稳定性。
模型性能
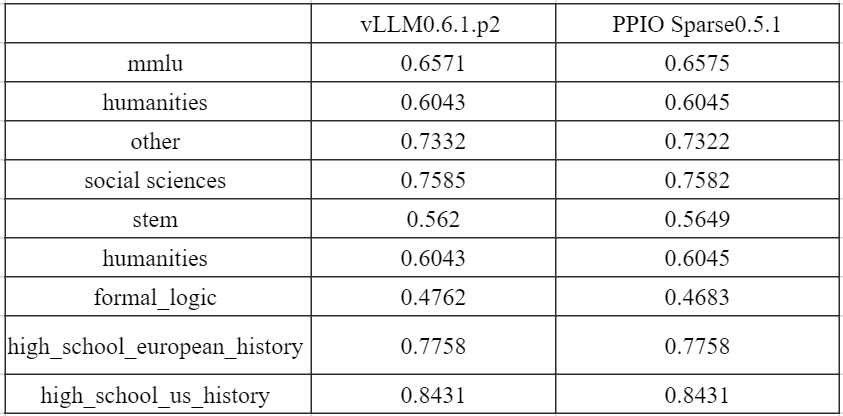
因为 KV 稀疏是一种有损的压缩算法,而进行模型性能评测,同样的至关重要,我们基于 Llama3-8B 进行了 mmlu 等性能评测,发现精度损失基本上在 3% 以内。如下表所示,我们通过 mmlu、humanities 进行模型性能测试:
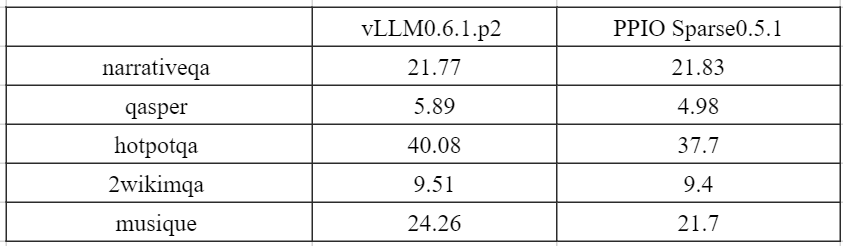
其次,针对实际业务当中的长文本场景,我们进行了输入长度为 7k-30k 的 QA 任务评测,压缩比控制在 10 倍以上,其结果显示整体精度损失在 10% 左右。
关键技术
分层稀疏与 Tensor Parallelism
vLLM 本身采用的是 Iteration-Level Schedule 调度策略,即我们常说的 Continuous Batching, 这种调度策略的特点便是不是等到批次中的每个序列都完成生成,而是实现迭代级调度,从而比静态批处理产生更高的 GPU 利用率。如文章开头所说的,因为 Llama3-8B 等模型本身就具有分层稀疏等特性,而我们基于 Continuous Batching 的改造,自然也遇到一系列的挑战。
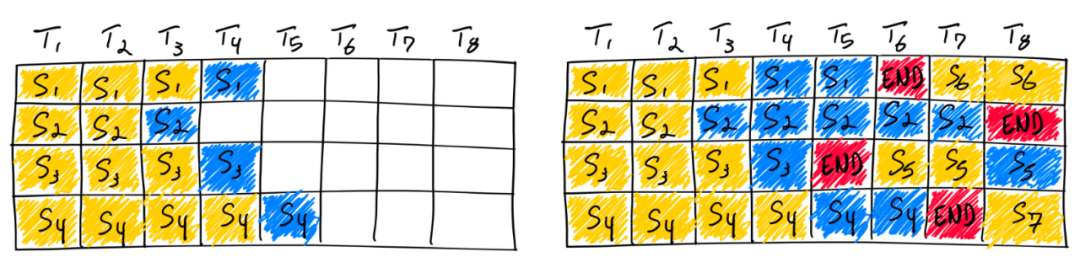
Completing seven sequences using continuous batching. Left shows the batch after a single iteration, right shows the batch after several iterations. Once a sequence emits an end-of-sequence token, we insert a new sequence in its place (i.e. sequences S5, S6, and S7). This achieves higher GPU utilization since the GPU does not wait for all sequences to complete before starting a new one.
首先需要解决的问题便是不同层的内存管理问题,因为 vLLM 采用的是全层统一的分页内存管理模式,同时在队列策略上是 Full Cache 和 Sliding Window 只能二选一的策略,因而我们需要对 vLLM 的底层结构进行了调整,即同时支持 Full Cache 和 Sliding Window 以不同的层可以选择自由选择 Full Cache 或 Sliding Window 的诉求,最终实现不同层的不同稀疏程度,对应的结构如下图所示:
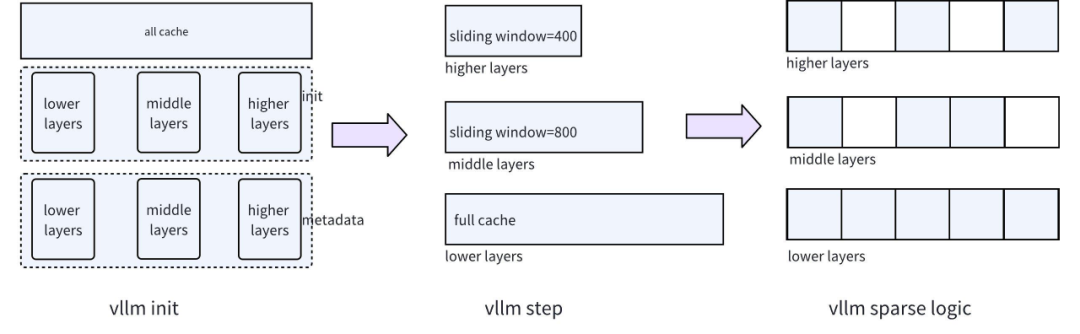
整体上可以分成对三个阶段的调整:
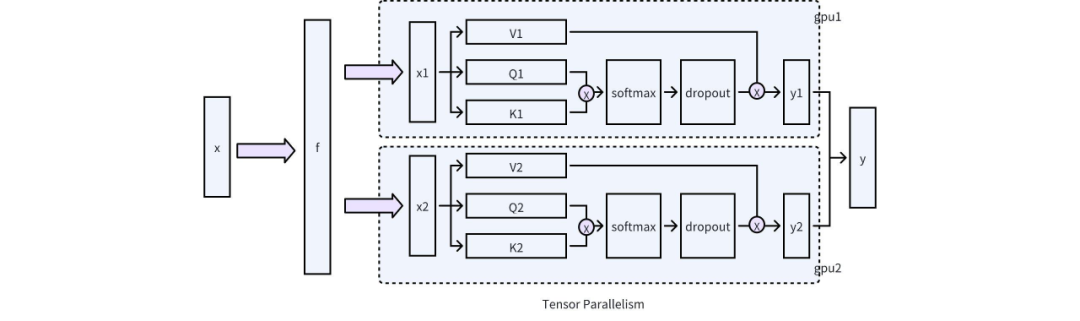
以上,主要是针对 vllm 支持分层稀疏在框架层上的修改,接下来重点介绍一下底层 CUDA 的优化。
Attention 改造
底层 CUDA 方面的改造,主要集中在 Attention 这一计算单元的改造,即 FlashAttention、PagedAttention 的改造,PagedAttention 相对简单,我们重点介绍一下 FlashAttention 的改造。
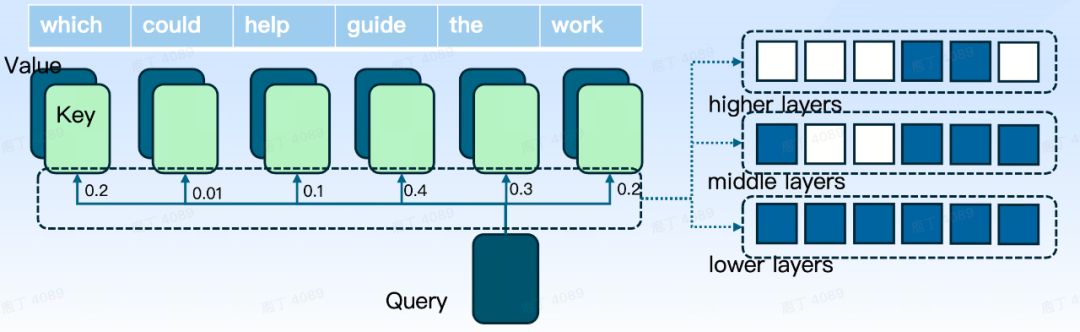
首先我们回顾一下 Attention 的计算公式:
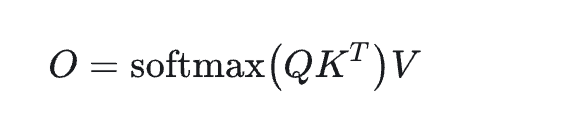
如上图所示,softmax 自身的计算过程是对 QK 的计算,同时是一种 2-pass 算法(循环 2 次),然而最终的计算目标 O 却可以通过 FlashAttention 算法,通过 1-pass(循环 1 次)进行实现。FlashAttention 的实现逻辑可以参考下面关于 FlashAttention2 论文的截图,简而言之,即通过 Q 以分块遍历的方式对 KV 进行分块计算,同时逐步更新 O/P/rowmax 等数据,直到循环结束,再让 O 除以ℓ,即可实现 1-pass 的 FlashAttention 计算。
对我们实现 KV 稀疏来说,需要重点注意的是,FlashAttention 的计算过程中,已经计算出 softmax 所需要的 rowmax/ℓ(全局的最大化和累加值),但 FlashAttention 并没有返回这两者的结果。

有了 FlashAttention 的基础理解,我们再讨论一下 PYRAMIDKV 等论文中关于稀疏化的打分公式,如下图所示:
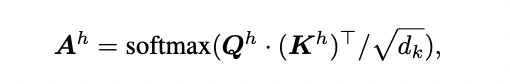
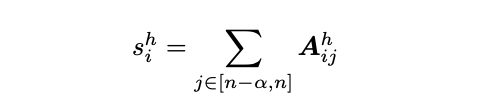
上述公式的 A 为 softmax 打分,S 为邻近 a 个 softmax 打分的求和,通过上面的内容可知,softmax 本身是一种 2-pass 算法,无法直接融合到 FlashAttention 当中,也说明稀疏化打分同样无法 1-pass 实现。
正如上文所说的注意事项,FlashAttention 虽然没有输出 softmax 打分,但却计算了 rowmax/ℓ这些中间值,因而,我们参考 Online Softmax: 2-pass 算法,利用 rowmax/ℓ的输出,就可以实现 KV 稀疏的具体打分 S。在工程上,只需要对对 FlashAttention 进行如下的改进,即可满足诉求:
在 Online Softmax 的代码实现中,有两个细节需要格外注意:
PagedAttention 所做的工作与 FlashAttention 类似,其目标都是为了求最终的 S,不在这里进行详细说明。
总结
我们基于 vLLM 0.5.1 改造的 PPIO Sparse0.5.1,当前主要支持 Llama3-8B、Llama3-70B 等模型,推理模式上支持 CUDA graphs 模式,运行环境也主要在 RTX 4090 等消费级显卡上进行部署,当前无论在工程上,还是在算法上,尚有巨大的优化空间。
对比最新的 vLLM-0.6.2 版本,以下特性我们还不支持:
参考论文
[1]H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
[2]Keyformer: KV Cache Reduction through Key Tokens Selection for Efficient Generative Inference
[3]SnapKV: LLM Knows What You are Looking for Before Generation
[4]PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
[5]PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference
[6]MiniCache: KV Cache Compression in Depth Dimension for Large Language Models
[7]Layer-Condensed KV Cache for Efficient Inference of Large Language Models
[8]TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
[9]CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion
[10]KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation




