背景
随着大模型的飞速发展, AI 技术开始在更多场景中普及。在数据库运维领域,我们的目标是将专家系统和 AI 原生技术相融合,帮助数据库运维工程师高效获取数据库知识,并做出快速准确的运维决策。
传统的运维知识库系统主要采用固化的规则和策略来记录管理操作和维护的知识,这些系统的知识检索方式主要基于关键字搜索和预定义的标签或分类,用户需要具备一定的专业知识才能有效地利用这些系统。
这已不足以满足现在复杂多变的运维环境。因此,借助大模型来提供运维知识并协助决策成为趋势。这将在运维能力、成本控制、效率提升和安全性等方面带来深刻的变革。
在数据库领域,AI 技术应用可以划分为不同场景,例如知识库学习(包括知识问答和知识管理)、诊断与推理(包括日志分析和故障诊断)、工作辅助(包括 SQL 生成和 SQL 优化)等。本文将主要着重介绍「知识库智能问答系统」的设计与实现,旨在为读者提供深入了解该领域应用的思路。
架构设计和实现
技术方案选型
目前,大模型已经可以通过对自然语言的理解揣摩用户意图,并对原始知识进行汇总、整合,进而生成更具逻辑和完整性的答案。然而,仍存在以下几个问题,导致我们不能直接使用这些模型来对特定领域知识进行问答。
为了解决这些问题,业界采用了如下几种技术手段来为大型模型提供额外知识。
为了确保准确性和效率,我们选择了第 2 种和第 3 种方式相结合的方案,通过向量数据库将知识外挂作为大模型记忆体,使用 LangChain 作为基础开发框架来构建知识库问答系统,最终依靠Prompt 工程和大模型进行交互。
分模块设计实现
数据库运维知识库的整体设计流程如下图所示,包括文档加载、文档分割、文本/问题向量化、问答缓存、大模型生成答案等流程。
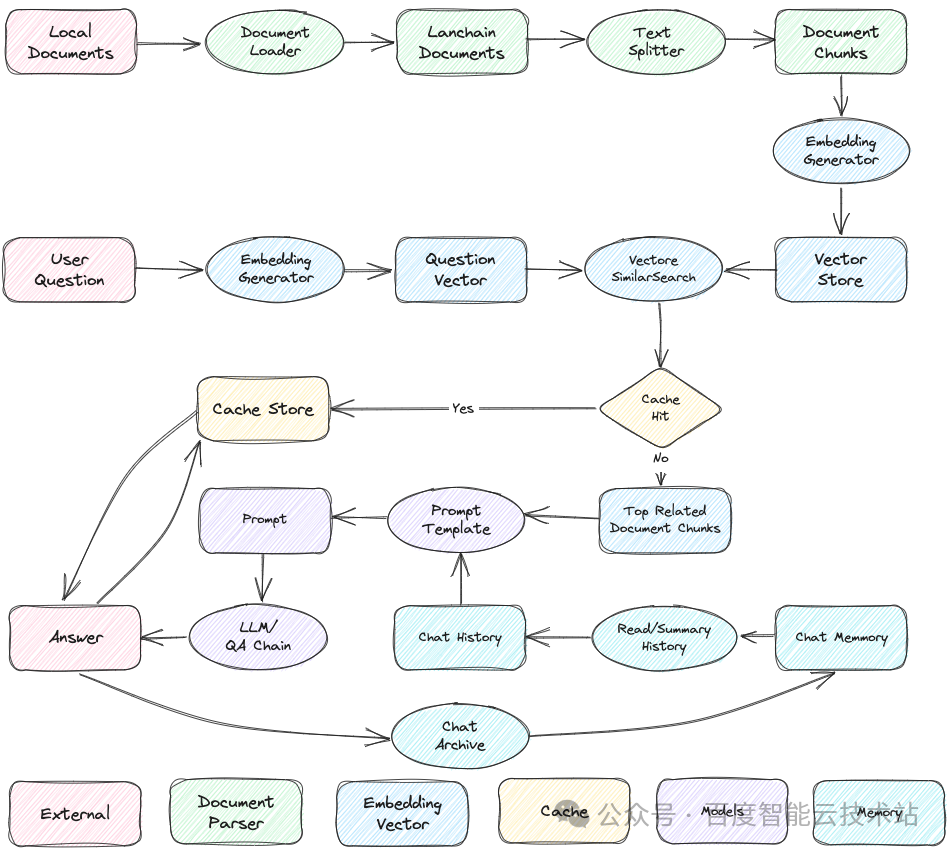
知识入库
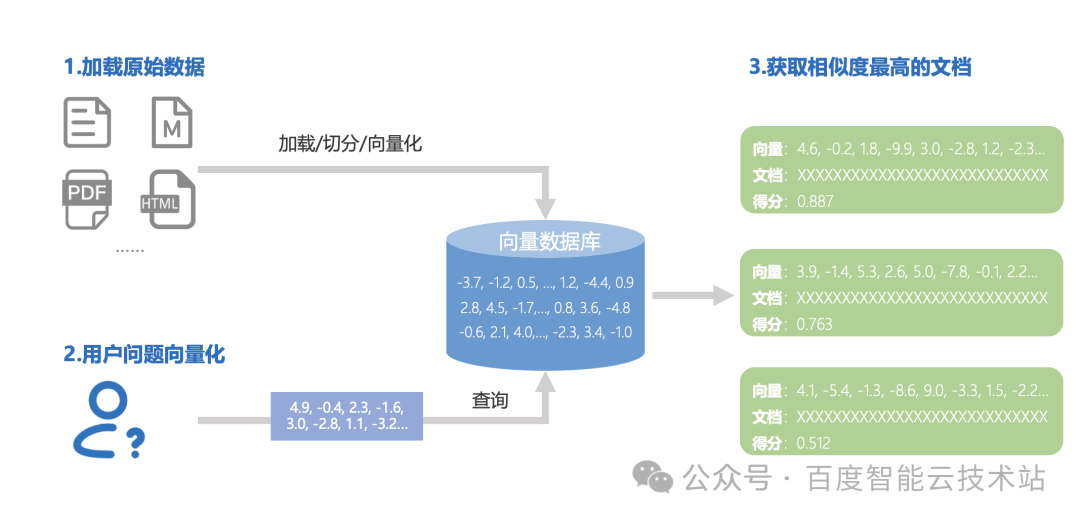
数据检索
结果整合
将向量数据库检索召回的文本进行二次加工后,利用 LLM 总结概括和分析推理能力,完成最终答案的生成。
技术难点和解决方案
难点一:向量数据库召回率低
尽管通过将知识嵌入(Embedding)与大型语言模型相结合已经成为一种高效的实现路径,但向量数据库在向量化、存储和检索等多个阶段都可能存在问题,进而导致检索结果的召回率不尽如人意。在实际测试中,我们在未经优化的情况下,召回率仅达到了 70% 左右。而一个相对可靠的系统,召回率至少需要达到 85% 或甚至 90% 以上。以下是我们在应用中采取的优化措施。
精确切分文本

优化文本向量化
Embeddings 和向量检索调优
对于 Embeddings 的选择和调优,上文已经介绍过,我们最终选择了效果更好的文心 Embedding。对于向量数据库检索性能,这里优化空间并不大,调整 HNSW 算法的参数,对最后召回结果影响不大。
难点二:Token 数量限制
在应用大型语言模型时,我们面临的主要限制之一就是输入文本的上下文长度。开源模型和商业模型的上下文长度限制范围从 2K 到 100K 不等。上下文长度对于应用大型语言模型具有关键影响,包括知识增强、记忆等方面的工作,都是为了解决上下文长度限制而设计的。以下是我们采取的策略:

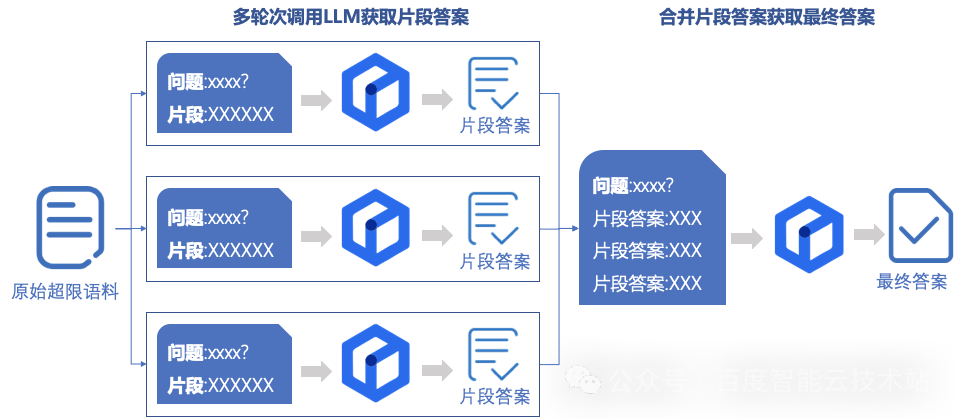
难点三:知识陈旧和虚构答案
在商业大型模型的大多数应用场景下,模型能够为 MySQL、Oracle 等数据库的相关问题提供令人满意的答案。然而,不可避免地,这些大型模型有时会出现知识陈旧和答案虚构的问题。为了提供更加丰富和准确的答案,我们采用了一种搜索和推荐系统的方法,并结合了大型模型的推理和总结能力。以下是我们的主要方案和流程:

可以看到文档解析和大模型调用其实就是在重复我们前边介绍的领域知识入库和结果的二次整合过程,唯一不同的地方就是我们使用搜索引擎去代替了向量检索。以 MySQL 为例子,具体流程如下:
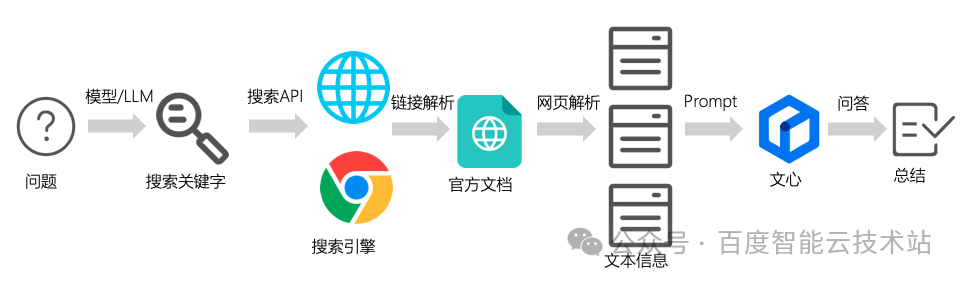
应用场景接入
该系统自从内部上线以来,整体的回答准确率达到 80% 以上,数据库运维工作量直接减少 50%,包括 80% 咨询量,以及 20% 工单处理工作。
目前「知识库智能问答系统」主要通过两种方式接入和应用:Database Chat 和 IM 机器人。
总结
从技术工程角度来看,利用向量数据库结合大型 AI 模型来构建领域知识库系统的实现并不复杂,然而,这一领域仍然面临着不少挑战和潜在的改进空间。在本文中,我们已经讨论了一些解决方案和技术,但仍然有许多可能的改进和未来发展方向值得深入研究。
首先我们认为关键点还是解决向量检索的召回准确性和超长文本处理能力是两个难点,这些方面可能还有更好的方式。此外,大模型本身的能力和文档质量是系统性能的关键因素,因此需要不断升级和维护模型,同时确保文档的及时性和准确性。
我们希望更多的研究者和工程师积极贡献更多的创新思路和技术,推动大模型在数据库运维领域落地,期待未来能有更多的可能性。