一、情感分析概述
文本情感分析,即 Sentiment Analysis(SA),又称意见挖掘或情绪倾向性分析。针对通用场景下带有主观描述的中文文本,自动判断该文本的情感极性类别并给出相应的置信度,情感极性分为积极、消极、中性等。
在文本分析的基础上,也衍生出了一系列细粒度的情感分析任务,如:
核心目标和价值
舆情系统的最核心需求,是能够精准及时的为客户甄别和推送负面,负面识别的准确性直接影响信息推送和客户体验,其中基于文本的情感分析在舆情分析中的重要性不言而喻,下图简要展示了文本分析以及情感分析在舆情体系中的作用。
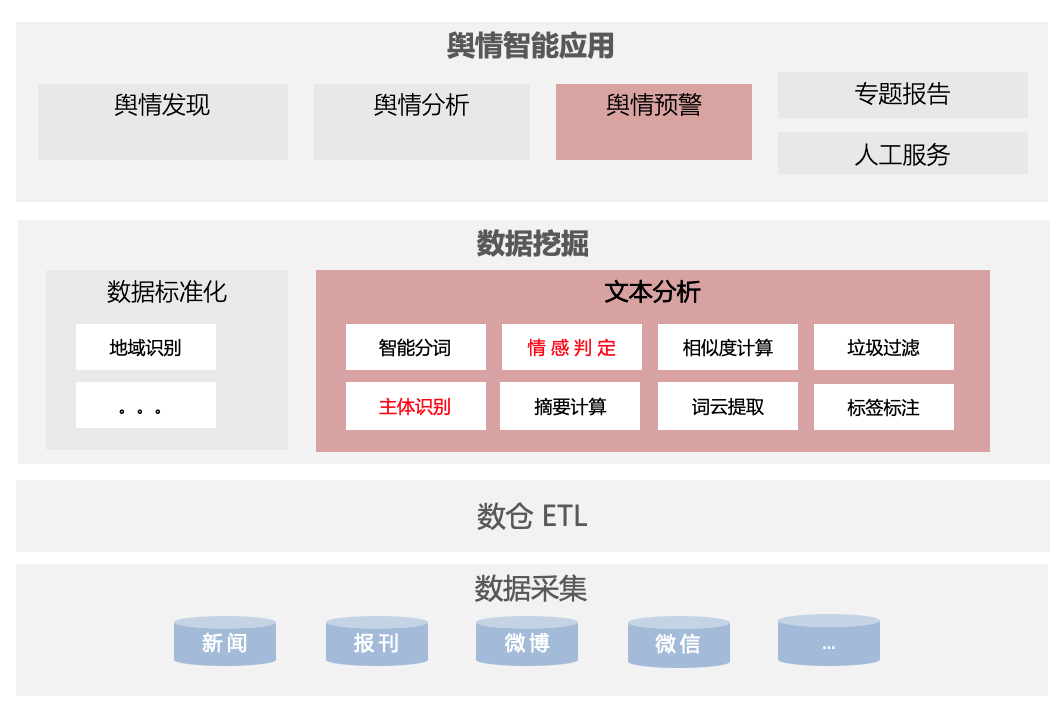
舆情数据通过底层的大数据采集系统,流入中间层的 ETL 数据处理平台,经过初级的数据处理转化之后,向上进入数据挖掘核心处理环节;此阶段进行数据标准化、文本深度分析,如地域识别、智能分词、情感判定、垃圾过滤等,经过文本处理的结果,即脱离了原始数据的状态,具备了客户属性,基于客户定制的监测和预警规则,信息将在下一阶段实时的推送给终端客户,负面判定的准确度、召回率,直接影响客户的服务体验和服务认可度。
难点与挑战
舆情业务中的情感分析难点,主要体现在以下几个方面:
舆情的客户群体是复杂多样的,涉及行业多达 24 个(如下图所示),不同行业数据特点或敏感判定方案不尽相同,靠一个模型难以解决所有问题;

舆情监测的数据类型繁多, 既有常规的新闻、微信公众号等媒体文章数据,又有偏口语化的微博、贴吧、问答数据,情感模型往往需要针对不同渠道类型单独训练优化,而渠道粒度的模型在不同客户上效果表现也差别巨大;
客户对情感的诉求是有差异的,有些客户会有自己专属的判定条件。通用的情感模型难以适应所有客户的情感需求。
随着时间推移,客户积累和修正的情感数据难以发挥价值。无法实现模型增量训练和性能的迭代提高。
对于关注品牌、主体监测客户,需要进行特定目标(实体)情感倾向性(ATSA)判定。那么信息抽取就是一个难题。
对于新闻类数据,通常存在标题和正文两个文本域。如何提取有价值的文本信息作为模型输入也是面临的困难。
二、情感分析在百分点舆情的发展历程
从 2015 年开始,百分点舆情便开始将机器学习模型应用在早期的负面判定中;到 2020 年,我们已经将深度迁移学习场景化和规模化,也取得了不错的成果;
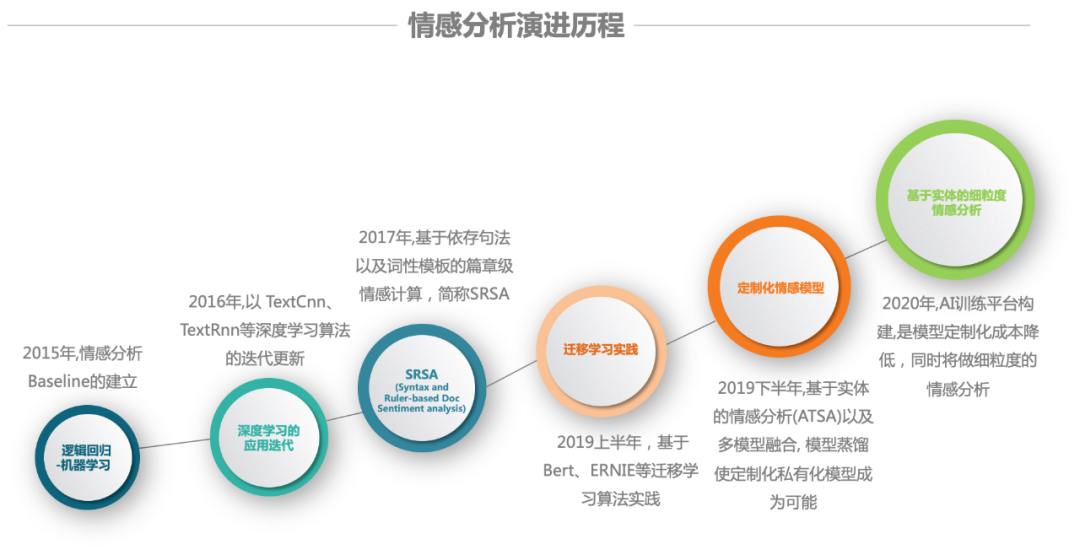
2015 年 :抓取百万级别的口碑电商评论数据,使用逻辑回归进行建模,做为情感分析的 BaseLine;
2016 年 :主要侧重于技术上的递进,进入深度学习领域。引入 word2vec 在大规模语料集上进行训练,获得具有更好语义信息的词向量表示,替代基于 Tfidf 等传统的统计特征。随后在 TextCnn、TextRnn 等深度学习算法进行更新迭代,尽管得到数字指标的提高,但是对于实际业务的帮助还是不足。
2017 年 :结合舆情全业务特点,需要能做到针对品牌、主体的情感监测。提出 Syntax and Ruler-based Doc sentiment analysis 的方式,依据可扩充的句法规则以及敏感词库进行特定的分析。该方式在敏感精准度指标上是有提升的,但是却有较低的召回。同时在进行规则扩充时,也比较繁琐。
2019 年上半年 :以 Bert 为代表的迁移学习诞生,并且可以在下游进行 fine-tune,使用较小的训练数据集,便能取得不错的成绩。进行以舆情业务数据为基础,构建一个简易的文本平台标注平台,在其上进行训练数据的标注,构建了一个通用的情感模型分类器。评测指标 F1 值为 0.87,后续对 ERNIE1.0 进行尝试,有两个百分点的提升。
2019 年下半年 :主要从舆情的业务问题入手,通过优化提取更加精准、贴近业务的情感摘要作为模型输入,使用定制化模型以及多模型融合方案,联合对数据进行情感打标。并提出基于情感实体(主体)的负面信息监测,下述统称 ATSA(aspect-term sentiment analysis),使用 Bert-Sentence Pair 的训练方式, 将 摘要文本、实体联合输入,进行实体的情感倾向性判定。在定点客户上取得不错的成绩,最后的 F1 值能达到 0.95。
2020 年 :将细化领域做到客户级别,定制私有化情感模型。同时将加大对特定实体的细粒度情感分析(ATSA)的优化;同时,通过内部 AI 训练平台的规模化应用,做到模型的全生命周期管理,简化操作流程,加强对底层算力平台的资源管控。
三、预训练语言模型与技术解析
下图大致概括了语言模型的发展状况(未完全统计):
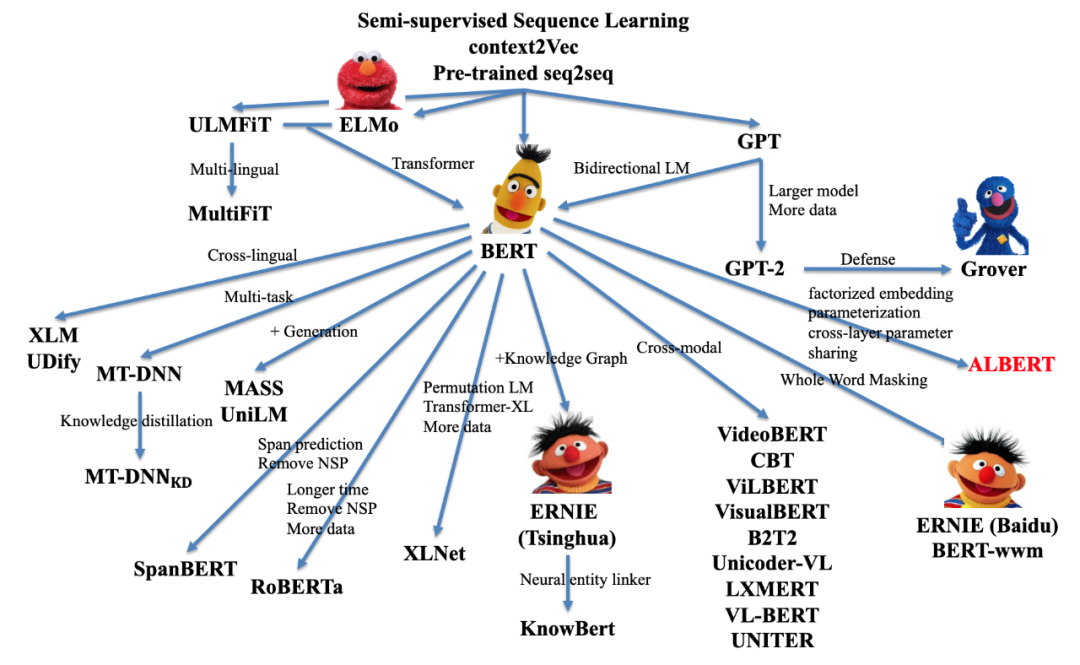
在 2019 年度情感分析实践中,率先使用预训练语言模型 Bert,提高了情感分析的准确率。后来具有更小参数量的 ALBERT 的提出,使生产环境定制化情感模型成为可能。这里就主要介绍 BERT 以及 ALBERT。
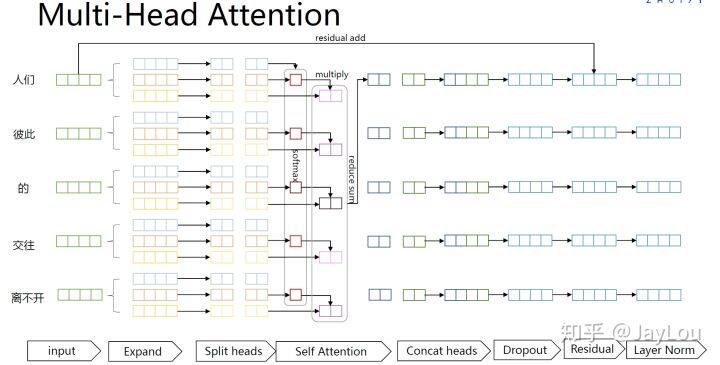
BERT(Bidirectional Encoder Representations from Transformerss)的全称是基于 Transformer 的双向编码器表征,其中「双向」表示模型在处理某一个词时,它能同时利用前面的词和后面的词两部分信息(如下图所示)。
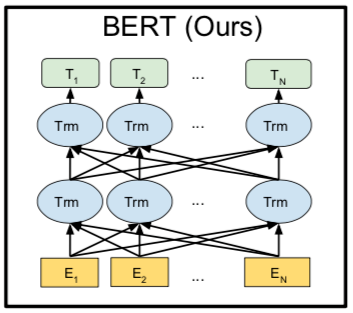
在 BERT 中, 主要是以两种预训练的方式来建立语言模型。
1.MLM(Masked LM)
MLM 可以理解为完形填空,作者会随机 mask 每一个句子中 15%的词,用其上下文来做预测,例如:my dog is hairy → my dog is [MASK]。此处将 hairy 进行了 mask 处理,然后采用非监督学习的方法预测 mask 位置的词是什么,具体处理如下:
之后让模型预测和还原被遮盖掉或替换掉的部分。
2.NSP(Next Sentence Prediction)
首先我们拿到属于上下文的一对句子,也就是两个句子,之后我们要在这两段连续的句子里面加一些特殊 token: [cls] 上一句话,[sep] 下一句话. [sep]也就是在句子开头加一个 [cls],在两句话之中和句末加 [sep],具体地就像下图一样:
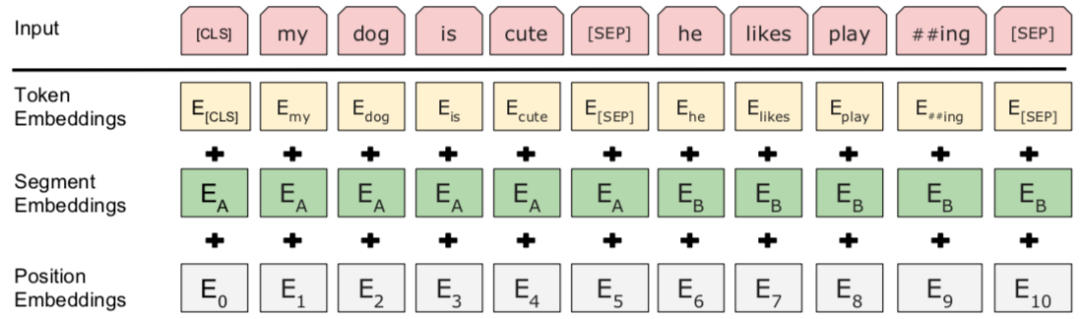
BERT 在文本摘要、信息检索、数据增强、阅读理解等任务中,也有实际的应用和发展。更多关于 Bert 相关介绍,请参照百分点认知智能实验室往期文章。
ALBERT 的全称是 A Lite BERT for Self-supervised Learning of Language Representations(用于语言表征自监督学习的轻量级 BERT),相对于 Bert 而言,在保证参数量小的情况下,也能保持较高的性能。当然同样的模型还有 DistilBERT、TinyBERT。
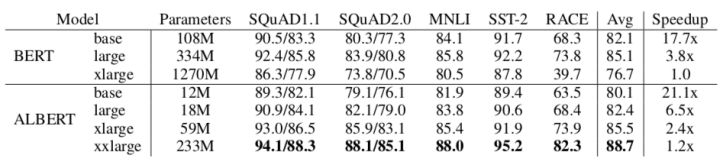
1.ALBERT 和 BERT 的比较
下图是 BERT 和 ALBERT 在训练速度和性能上的整体比较:
2.ALBERT 的目标
在基于预训练语言模型表征时,增加模型大小一般可以提升模型在下游任务中的性能。但是通过增加模型大小会带来以下问题:
在将 Bert-large 的隐层单元数增加一倍, Bert-xlarge 在基准测试上准确率显著降低。

ALBERT 核心目标就是解决上述问题, 下面就来介绍 ALBERT 在精简参上的优化。
3.ALBERT 模型优化
明确参数的分布,对于有效可靠的减少模型参数十分有帮助。ALBERT 同样也只使用到 Transformer 的 Encoder 阶段,如下图所示:
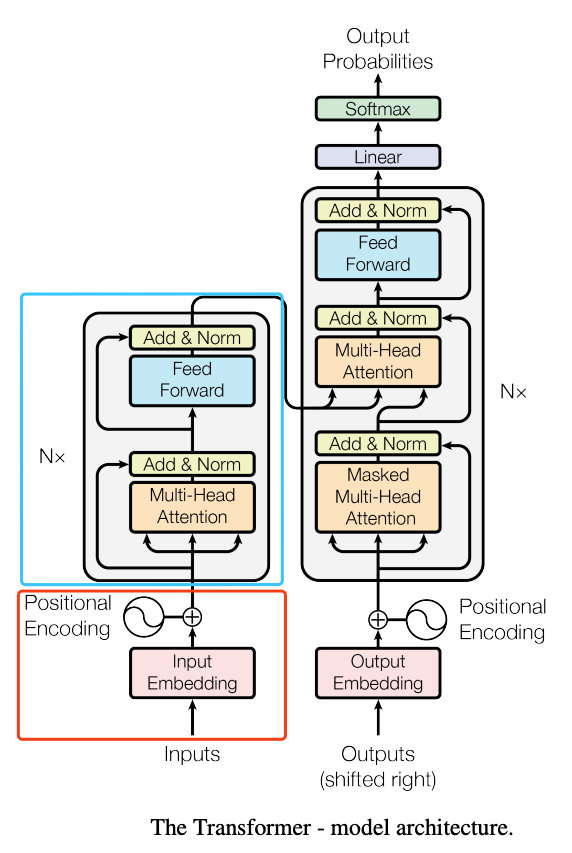
图中标明的蓝色方框和红色方框为主要的参数分布区域:
具体参数优化如下:
Factorized embedding parameterization(对 Embedding 因式分解)
ALBERT 认为,token embedding 是没有上下文依赖的表述,而隐藏层的输出值不仅包括了词本身的意思还包括一些上下文信息,因此应该让 H>>E,所以 ALBERT 的词向量的维度是小于 encoder 输出值维度的。在 NLP 任务中,通常词典都会很大,embedding matrix 的大小是 E×V。
ALBERT 采用了一种因式分解(Factorized embedding parameterization)的方法来降低参数量。首先把 one-hot 向量映射到一个低维度的空间,大小为 E,然后再映射到一个高维度的空间,当 E<<H 时参数量减少的很明显。如下图所示:
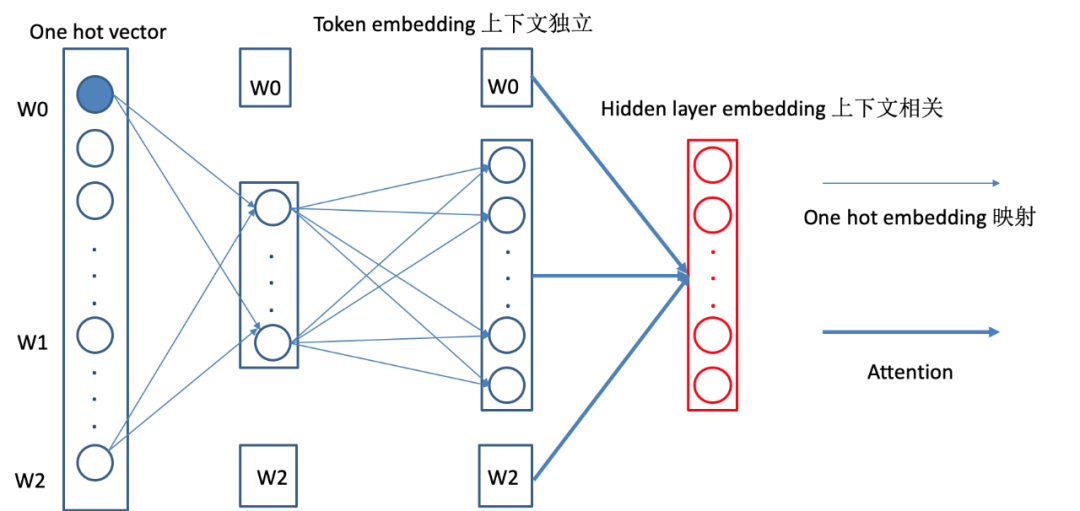
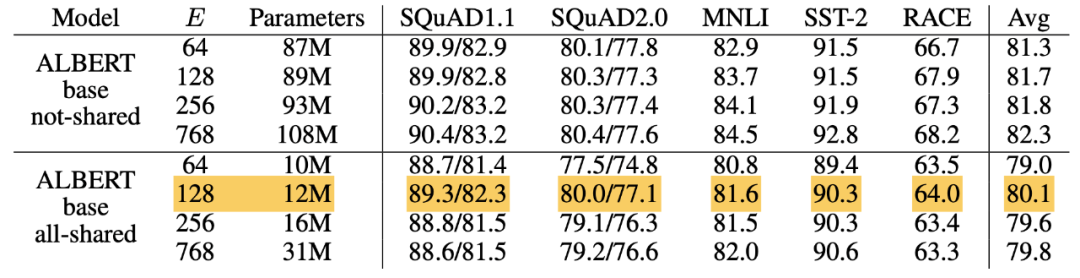
可以看到,经过因式分解。参数量从 O(V * H) 变为 O(VH),参数量将极大减小。如下图所示:在 H=768 条件下,对比 E=128 和 E=768,参数量减少 17%,而整体性能下降 0.6%。

在后续的实验环境(所有的优化汇总后),对 embedding size 的大小进行评估,得出在 E=128 时,性能达到最佳。
Cross-layer parameter sharing(跨层参数共享)
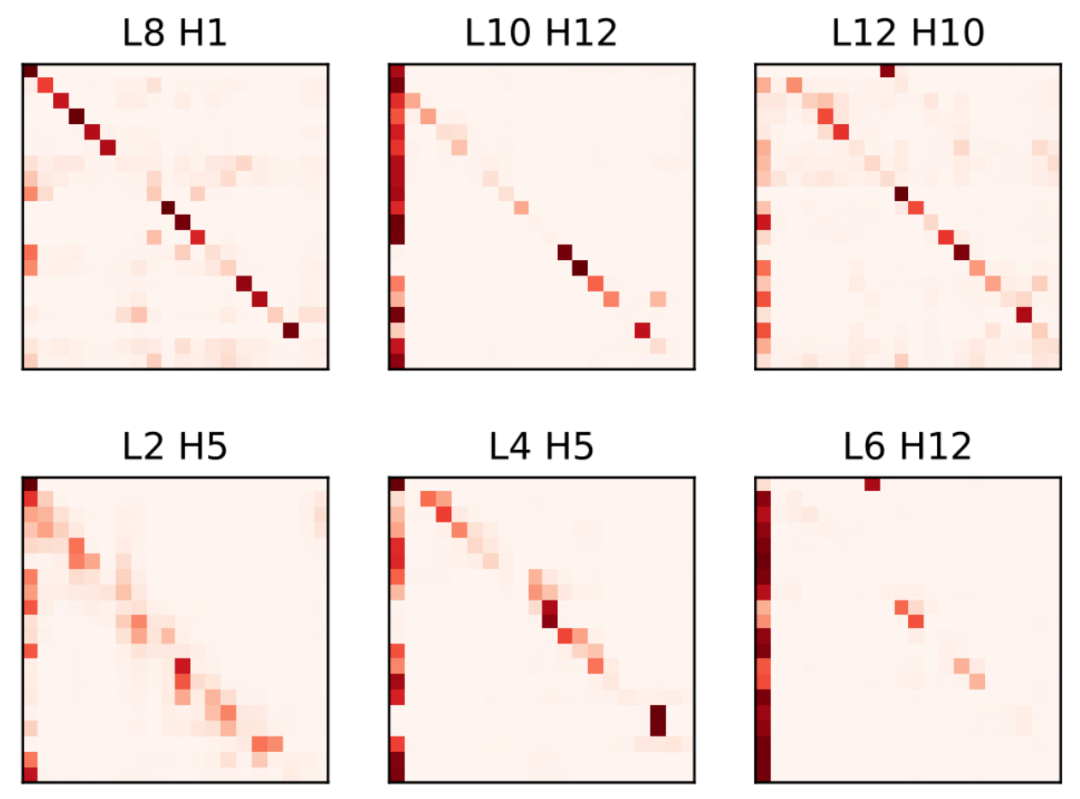
下图是对 BERT-Base Attention 分布的可视化。对于一个随机选择的句子,我们可视化来自不同 Layer 的 Head 的 Attention 分布。可以看到,底层的 Attention 分布类似于顶层的 Attention 分布。这一事实表明在某种程度上,它们的功能是相似的。
Transformer 中共享参数有多种方案,只共享 feed-forward 层,只共享 attention 层,ALBERT 结合了上述两种方案,feed-forward 层与 attention 层都实现参数共享,也就是说共享 encoder 内的所有参数。但是需要主要的是,这只是减少了参数量,推理时间并没有减少。如下图所示:在采用 all-shared 模式下,参数量减少 70%,性能下降小于 3%。
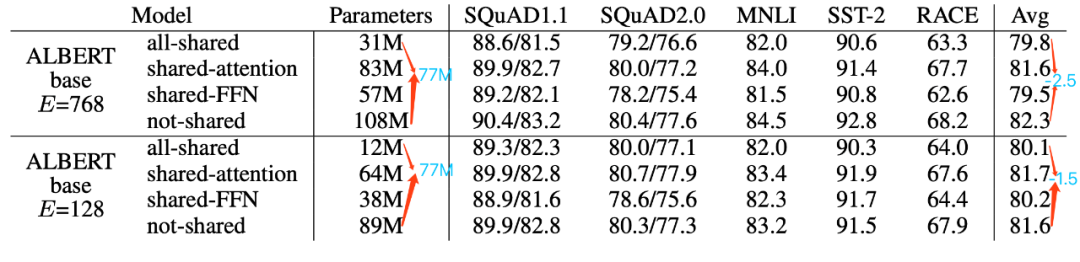
在经过上述的参数优化后,整体参数量有了极大的缩减,训练速度也极大加快。后续作者又在模型变宽和模型变深上做了几组实验。如下:
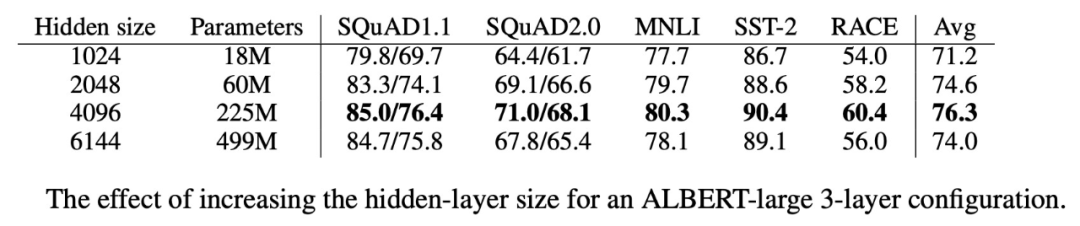
模型变宽
当我们增加 H 大小时,性能会逐渐提高。在 H=6144 时,性能明显下降。如下图所示:
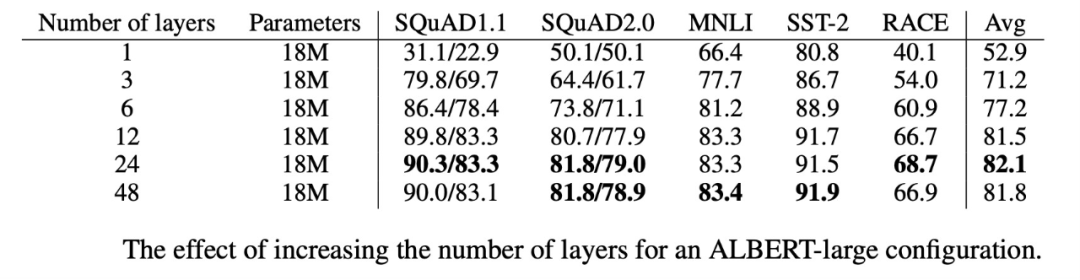
模型变深
在以 ALBERT-large 为基础参数,设置不同的 layer 大小,发现 layer=48 的性能要差于 layer=24 的性能,如下图所示:
一些实验表示 NSP(BERT-style)非但没有作用,反而会对模型带来一些损害。作者接着提出 SOP(ALBERT-style)的优化模式。具体如下:
Inter-sentence coherence loss(句子连贯性)
在 ALBERT 中,为了去除主题识别的影响,提出了一个新的任务 sentence-order prediction(SOP),SOP 的正样本和 NSP 的获取方式是一样的,负样本把正样本的顺序反转即可。SOP 因为是在同一个文档中选的,只关注句子的顺序并没有主题方面的影响。并且 SOP 能解决 NSP 的任务,但是 NSP 并不能解决 SOP 的任务,该任务的添加给最终的结果提升了一个点。

在后续的实验中, ALBERT 在训练了 100w 步之后,模型依旧没有过拟合,于是乎作者果断移除了 dropout,没想到对下游任务的效果竟然有一定的提升。
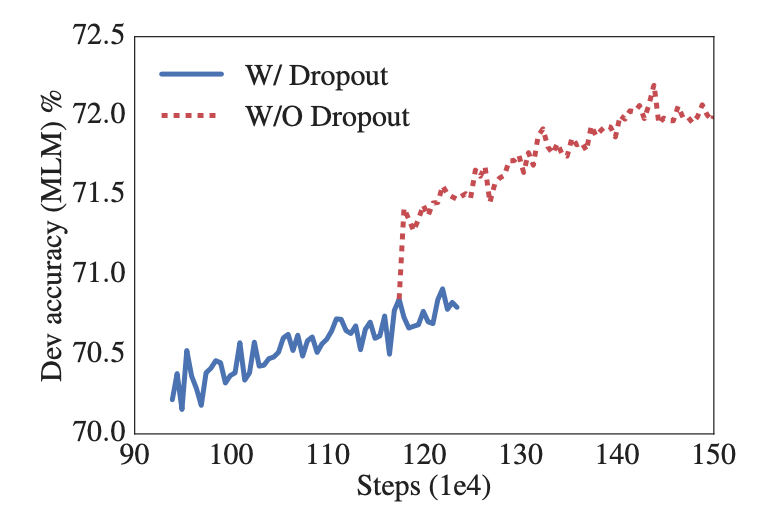
当然作者对于增加训练数据和训练时长也做了详尽的对比和测试,这里不再进行描述。
在最初的 ALBERT 发布时,是只有中文的。感谢数据工程师徐亮以及所在的团队,于 2019 年 10 月,开源了首个中文预训练的中文版 ALBERT 模型。
项目地址 :
top="8285">四、情感分析在舆情的应用实践
业务调研
2019 上半年,舆情服务的整体情感判定框架已经迁移到以 Bert 训练为基础的情感模型上,得出的测试指标 F1 值为 0.86,相较于旧版模型提升显著; 但是虽然数据指标提升明显,业务端实际感受却并不明显。因此我们对代表性客户进行采样调查,辅助我们找出生产指标和实验室指标差异所在。同时针对上文提到的关于舆情业务中情感分析的痛点和难点,进行一次深度业务调研:
1.客户情感满意度调查
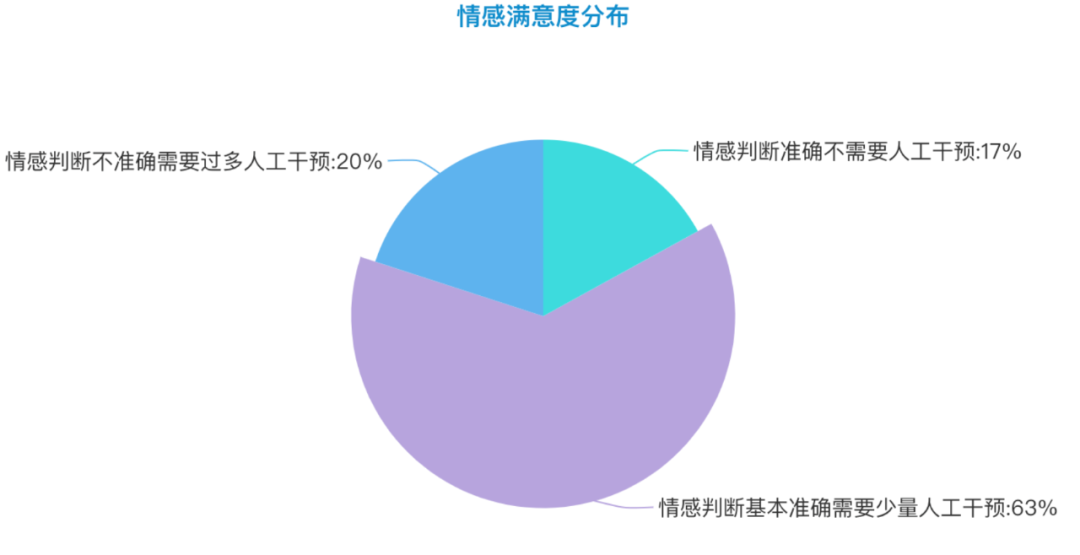
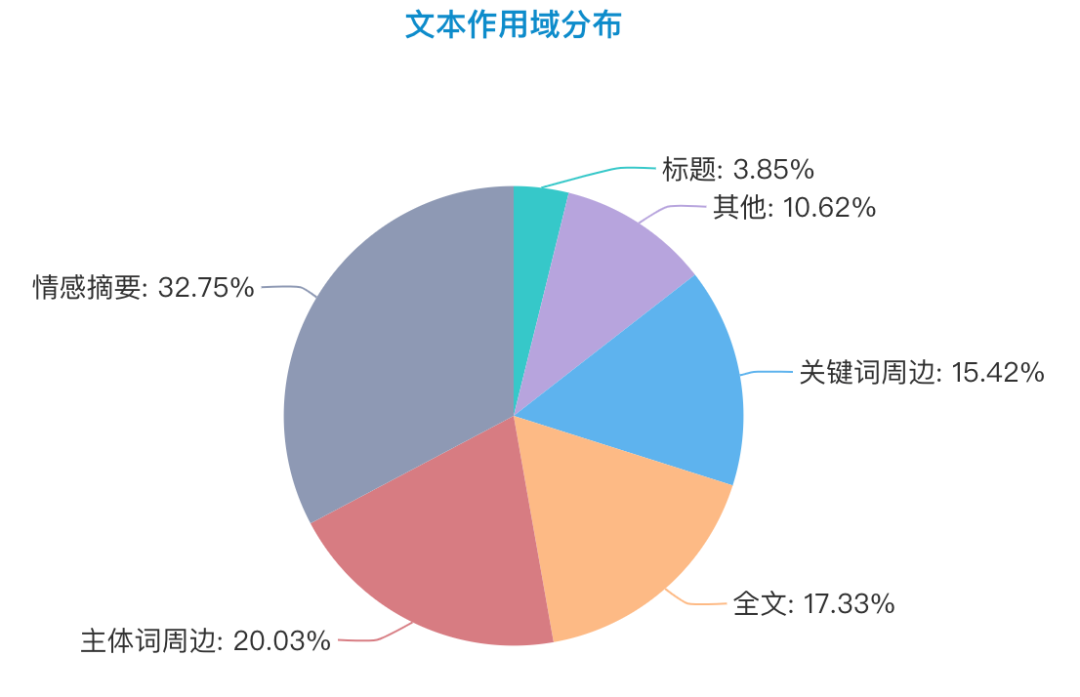
2.文本作用域(模型输入文本选择)调研
这里将文本作用域分为以下几个层次,分布情况如下图所示:
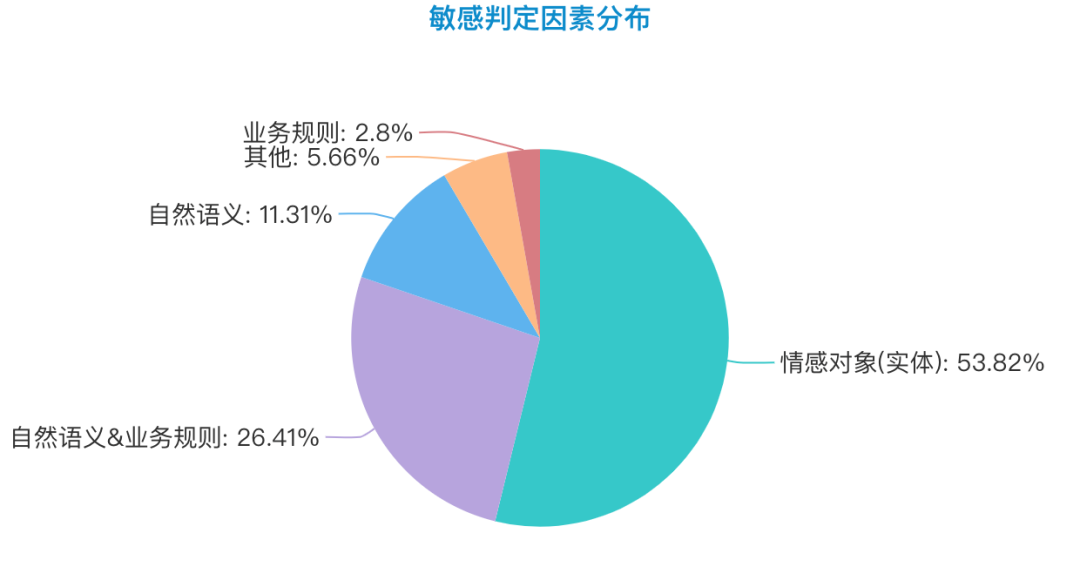
3.情感判定因素
这里对判定因素做以下介绍:
我们针对上述调研结果进行详尽分析,最终确定走情感细粒度模型的道路。
情感分析的落地实践
精简版本的情感架构概览如下:
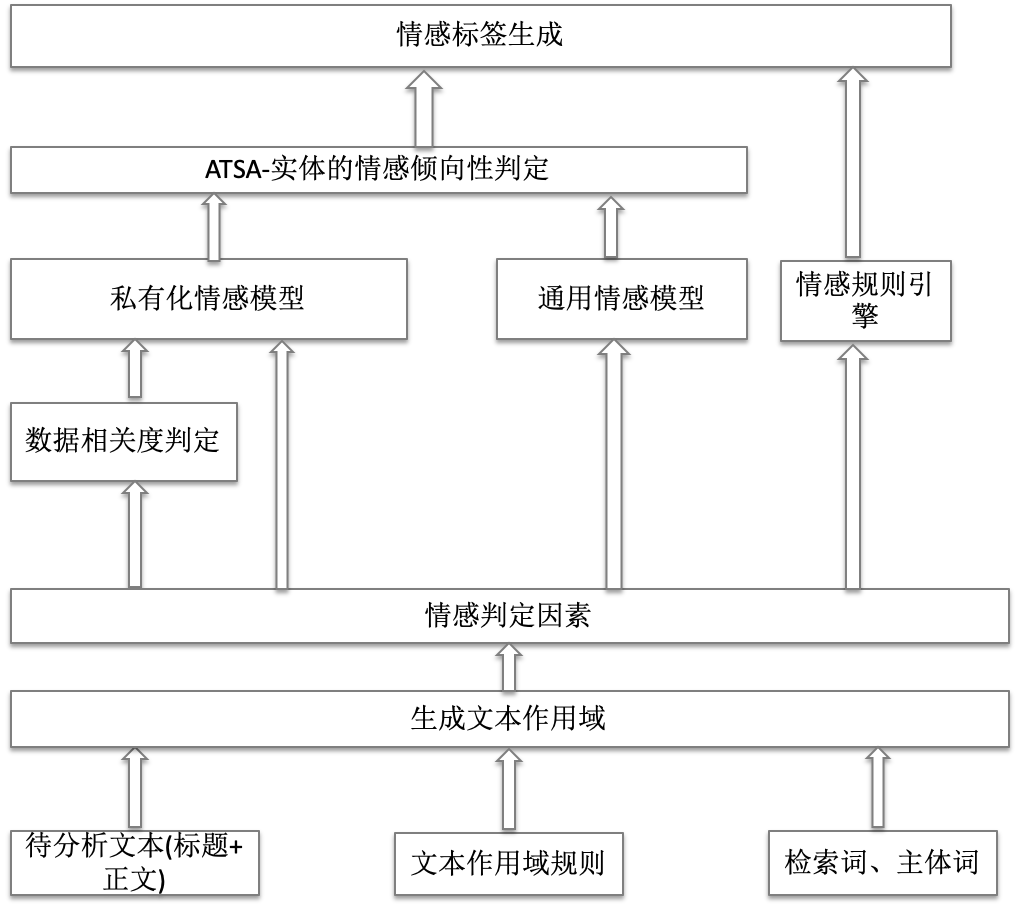
接下来会基于此进行讲述,大致分为如下几个层次:
1.输入层
这里主要是获取相应文本输入,以及客户的文本作用域规则和检索词、主体词,供下游的文本作用域生成提供对应的条件。
2.文本作用域
依据文本作用域规则,生成对应的模型输入,请参照上文对文本作用域的阐述。这里实验内容针对的是情感摘要。首先将文本进行分句,然后依据对每一个句子和检索词进行匹配,通过 BM25 计算相关性。这里限制的文本长度在 256 内。在文本域优化后, 对线上的 10 家客户进行对比分析,实验条件如下:
进行对比分析(客户名称已脱敏),每个客户的情感摘要和文本标题效果依次展示。如下图所示:
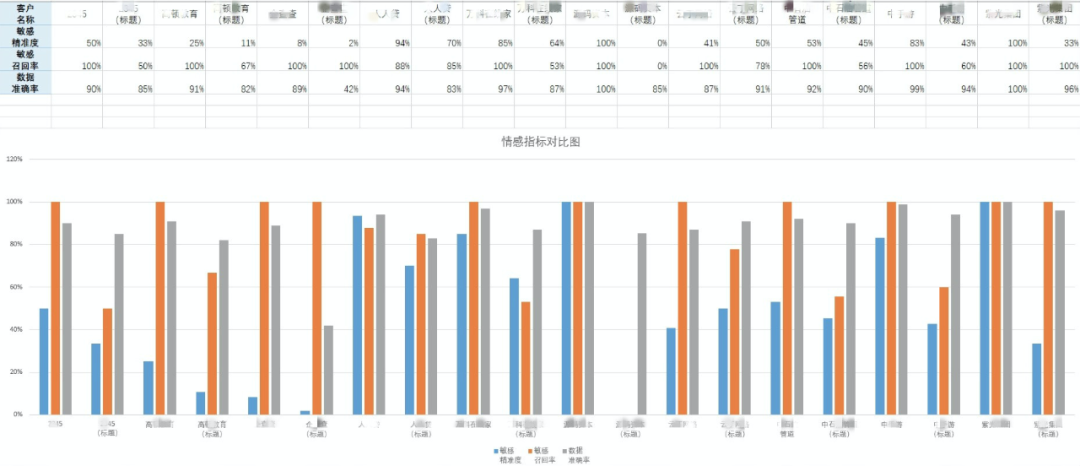
可以发现整体效果是有极大提升的。但是也可以看到部分客户的敏感精准率是偏低的,这个和客户的敏感分布有关,大部分的敏感占比只有总数据量的 10% ~20%,有些甚至更加低。所以面临一个新的问题,如何提升非均匀分布的敏感精准度。这个会在下文进行陈述。
3.情感判定因素
由上文的情感因素分布得知, 情感对象(实体)的因素占 54%,基于实体的情感倾向性判定(ATSA)是一个普适需求。如果这里直接使用通用情感分析判定(SA),在舆情的使用场景中会存在高召回,低精准的的情况。接下来会对此进行相关解决方案的的论述。
4.模型层
在 19 年初, 使用 Bert-Base(12L,768H)进行 fine-tune,得到如下指标:情感准确性:0.866, 敏感精准率: 0.88,敏感召回:0.84,F1: 0.867;后来在 ERNIE1.0 上进行尝试,情感准确性能提升 2 个百分点。不过因为 PaddlePaddle 的生态问题,没有选择 ERNIE。这是一个符合自然语义的情感模型, 但是对于舆情客户来说,这还远远不够。
对生产环境的埋点日志分析,发现客户存在大量的屏蔽操作。选取近一个月屏蔽最多的 10 个话题进行分析,如下图所示:
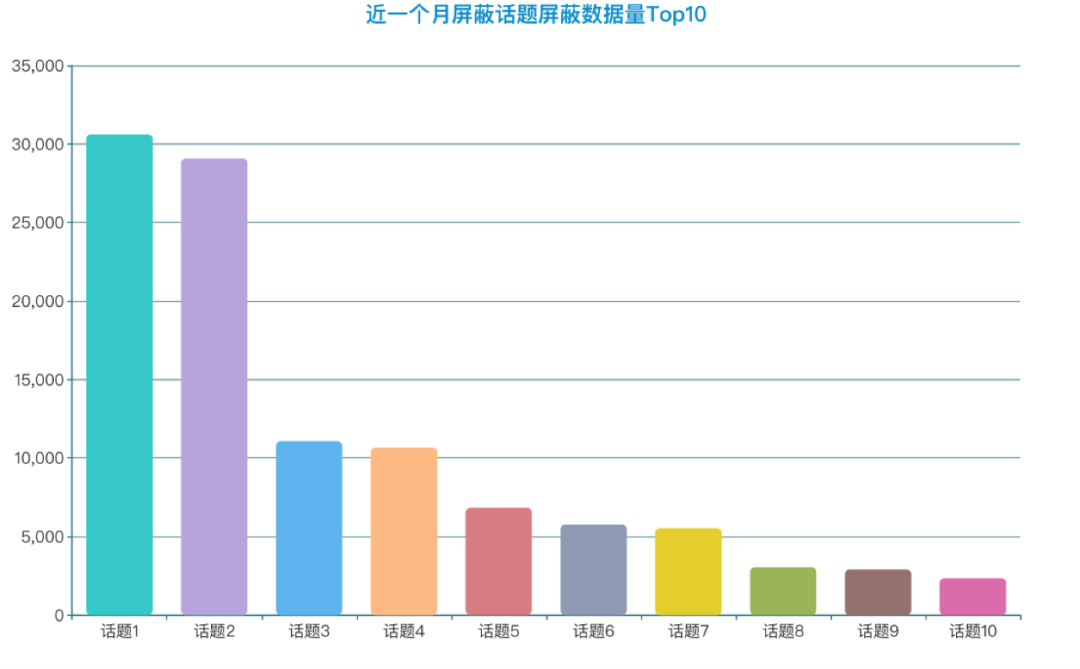
通过调研和分析发现,这些数据虽然命中关键词,但是数据相关度比较低。在情感判定之前引入相关度判定, 对于非相关的数据,一律判定为非敏感。对于精准数据再次进行情感分析判定,大大提升敏感精准率。在工程上选取 ALBERT 进行模型训练可以达到部署多个模型的目的。观测到,单个模型在推理阶段,在 Gpu(RTX 2080)上占用的显存大约在 600MiB,极大节省资源。
部分客户相关度模型效果如下:
| 客户名称 | 准确率 | 正样本数量 | 负样本数量 |
|---|---|---|---|
| 收藏、屏蔽数据 | |||
| 收藏、屏蔽数据 | |||
| 收藏、屏蔽数据 | |||
| 收藏、屏蔽数据 |
部分客户实施相关度判定,由于数据特征比较明显,可以很容易达到比较精准的数据效果,但是并不适用于所有客户。相关度模型的引入,即达到筛选相关数据的目的,也能减少情感判定噪音数据的干扰,提升敏感精准度。
5.ATSA-面向情感实体的情感倾向性分析
ATSA(aspect-term sentiment analysis) 要解决就是在特定情感实体下的情感倾向性判定问题。这里主要借鉴《Utilizing BERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence》文中的思想。这个工作做得非常聪明,它把本来情感计算的常规的单句分类问题,通过加入辅助句子,改造成了句子对匹配任务。很多实验证明了:BERT 是特别适合做句子对匹配类的工作的,所以这种转换无疑能更充分地发挥 BERT 的应用优势。
舆情中要解决的问题如下:

A 公司和 B 公司的情感倾向性是非敏感的, 而 C 公司却是敏感的。要解决这个问题,要面临两个问题:
在舆情的业务场景中,可以简化问题,由于情感实体是提前给定的, 所以不需要做实体识别和信息抽取, 只需要对特定实体的情感倾向性进行判定。整体流程如下:

主要是利用 Bert Sentence-Pair,文本与实体联合训练,得到输出标签。目前实验证明,经过这种问题转换,在保证召回率提升的情况下,准确率和精准率都得到了提高。选取一个客户进行对比测试,如下所示:
| 实验条件 | 实验方式 | 准确率 | 精准率 | 召回率 |
|---|---|---|---|---|
| 按照自然日采样,测试样本为912条,其中敏感数据108条 | ||||
| 情感摘要 |
上述是一个正负样本及其不均匀的情况,增加敏感精准率将提高客户的满意度。目前的实现的机制还略显简单,未来还将持续投入。
6.情感规则引擎
在部分客户场景中, 他们的业务规则是明确的或者是可穷举的。这里会做一些长尾词挖掘、情感新词发现等工作来进行辅助, 同时要支持实时的干预机制,快速响应。比如某些客户的官方微博经常会发很多微博,他们会要求都判定成非敏感。这里不再做过多介绍。
五、长期规划
AI 训练平台的构建
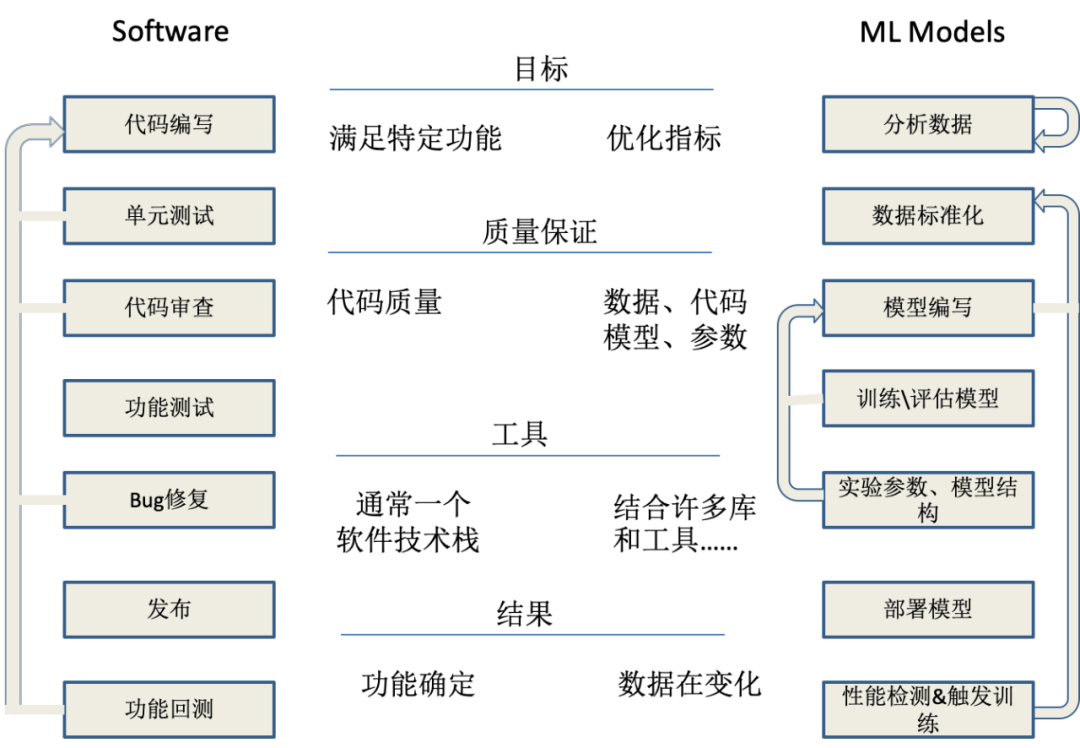
软件开发领域和模型开发领域的流程是不同的,如下所示:
可以看到,构建模型是困难的。在舆情架构发展中,线上多模型是必然的趋势,也就意味着需要一个平台能够快速支持和构建一个定制化模型,来满足真实的应用场景。这就需要从底层的算力资源进行管控、舆情数据的标准化制定和积累、模型的生命周期管理等多方面进行衡量。关于 AI 训练平台的构建以及在舆情领域的应用实践,我们将在后续文章做进一步阐述。
持续学习,增量迭代
随着舆情客户对系统的深度使用,一般会有情感标签的人工纠正。所以需要保证模型可以进行增量迭代,减少客户的负反馈。
多实体的情感倾向分析
对包含有多个实体信息的文本,针对每一个系统识别到的实体,做自动情感倾向性判断(敏感、非敏感),并给出相应的置信度,包括实体库的构建。
提升垂直类情感情感分析效果
在垂类上(App、餐饮、酒店等)情感倾向性分析准确率上加大优化力度。
随着舆情业务的发展,各领域客户都沉淀了大量与业务贴近的优质数据,如何有效使用这些数据,形成情感效果联动反馈机制,为业务赋能,是情感分析领域面临的新的挑战。在 2019 年的实践中,通过场景化的情感分析框架落地应用,对情感效果做到了模型定制化干预,真正提高了客户满意度。这种机制具有整体精度高、定制能力强、业务感知明显的特点。在后续工作中,将以 模型训练自动化与人工反馈相结合的方式,将模型定制能力规模化、平台化,实现情感分析在舆情场景下千人千面的效果。
原文链接 :