1. 背景
第 13 届“国际网络搜索与数据挖掘会议”()于 2 月 3 日在美国休斯敦召开,该会议由 SIGIR、SIGKDD、SIGMOD 和 SIGWEB 四个专委会共同协调筹办,在互联网搜索、数据挖掘领域享有很高学术声誉。本届会议论文录用率仅约 15%,并且 WSDM 历来注重前沿技术的落地应用,每届大会设有的 WSDM Cup 环节提供工业界真实场景中的数据和任务用以研究和评测。
今年的设有 3 个评测任务,吸引了微软、华为、腾讯、京东、中国科学院、清华大学、台湾大学等众多国内外知名机构的参与。美团搜索与 NLP 部继去年获得了WSDM Cup 2019第二名后,今年继续发力,拿下了 WSDM Cup 2020 Task 1:Citation Intent Recognition 榜单的第一名。
本次参与的是由微软研究院提出的 Citation Intent Recognition 评测任务,该任务共吸引了全球近 600 名研究者的参与。本次评测中我们引入高校合作,参评团队 Ferryman 由搜索与 NLP 部-NLP 中心的刘帅朋、江会星及电子科技大学、东南大学的两位科研人员共同组建。团队提出了一种基于 BERT 和 LightGBM 的多模融合检索排序解决方案,该方案同时被 WSDM Cup 2020 录用为专栏论文。

2. 任务简介
任务要求参赛者根据论文中对某项科研工作的描述,从论文库中找出与该描述最匹配的 Top3 论文。举例说明如下。
某论文中对科研工作[1]和[2]的描述如下:
参赛者需要根据这段科研描述从论文库中检索与[1][2]相关工作最匹配论文。
在本例中:
与工作[1]最匹配的论文题目应该是:
与工作[2]最匹配的论文题目应该是:
由上述分析可知,该任务是经典的检索排序任务,即根据文本 Query 从候选 Documents 中找出 Top N 个最相关的 Documents,核心技术包括文本语义理解和搜索排序。
2.1 评测数据
本次评测数据分为论文候选集、训练集、验证集和测试集四个部分,各部分数据的表述如表 1 所示:
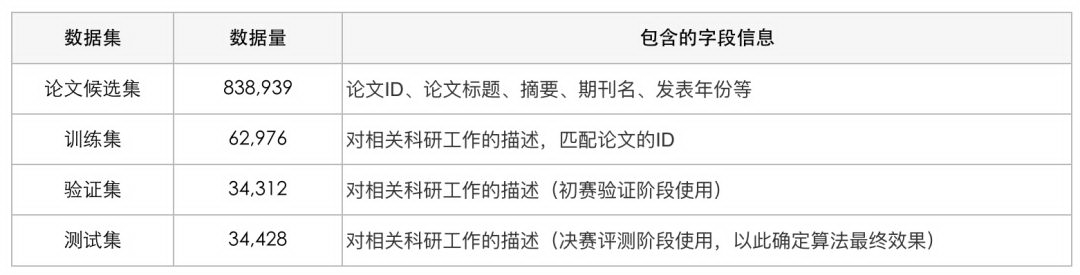
表 1 评测数据分析表
对本次评测任务及数据分析可以发现本次评测存在以下特点:
2.2 评测指标
本次评测使用的评价指标为 Mean Average Precision @3 (MAP@3), 形式如下:
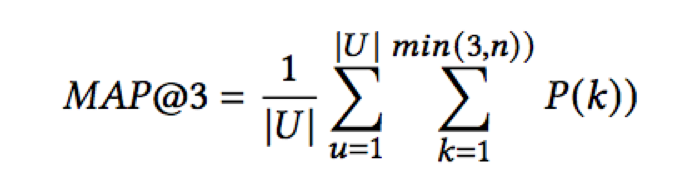
其中,|U|是需要预测的 description 总个数,P(k)是在 k 处的精度,n 是 paper 个数。举例来说,如果在第一个位置预测正确,得分为 1;第二个位置预测正确,得分为 1/2;第三个位置预测正确,得分为 1/3。
3. 模型方法
通过对评测数据、任务和评价指标等分析,综合考量方案的效率和精准性后,本次评测中使用的算法架构包括“检索召回”和“精准排序”两个阶段。其中,检索召回阶段负责从候选集中高效快速地召回候选 Documents,从而缩减问题规模,降低排序阶段的复杂度,此阶段注重召回算法的效率和召回率;精准排序阶段负责对召回数据进行重排序,采用 Learning to Rank 相关策略进行排序最优解求解。
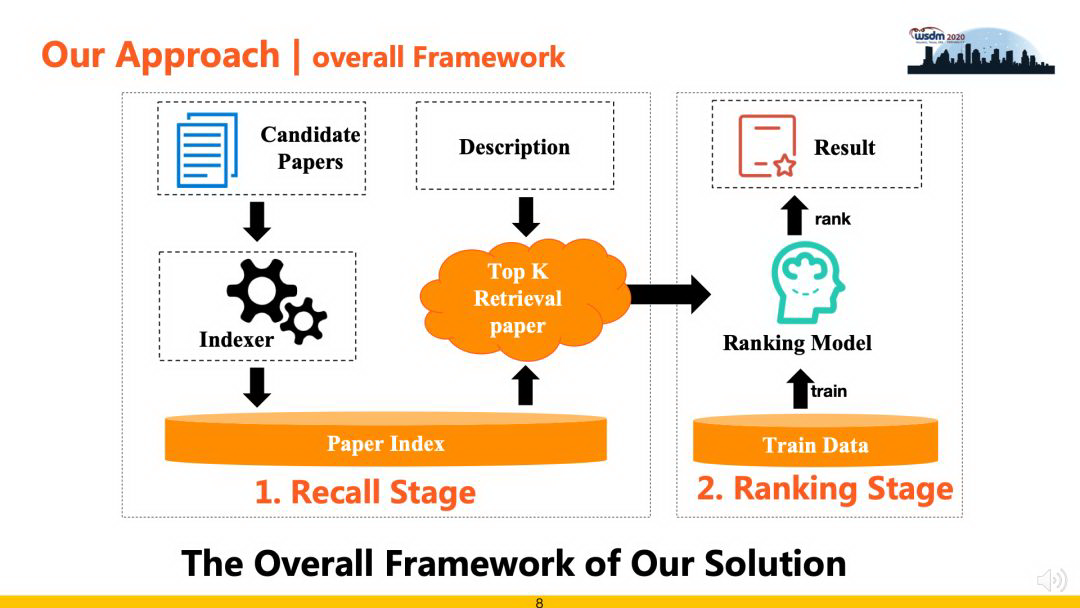
3.1 检索召回
F2EXP 定义如下 :
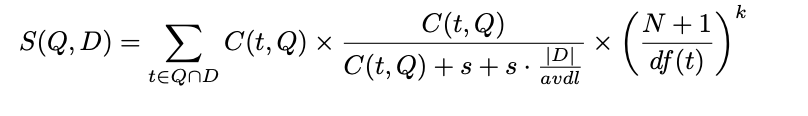
其中,Q 表示查询 query ,D 表示候选文档,C(t, Q)是词 t 在 Q 中的频次,|D|表示文档长度,avdl 为文档的平均长度,N 为文档总数,df(t)为词 t 的文档频率。
为了提升召回算法的效果,我们使用倒排索引技术对数据进行建模,然后在此基础上实现了 F1EXP、DFR、F2EXP、BM25、TFIDF 等多种检索算法,极大了提升了召回部分的运行效率。为了平衡召回率和计算成本,最后使用 F1EXP、BM25、TFIDF 3 种算法各召回 50 条结果融合作为后续精排候选数据,在验证集上测试,召回覆盖率可以到 70%。
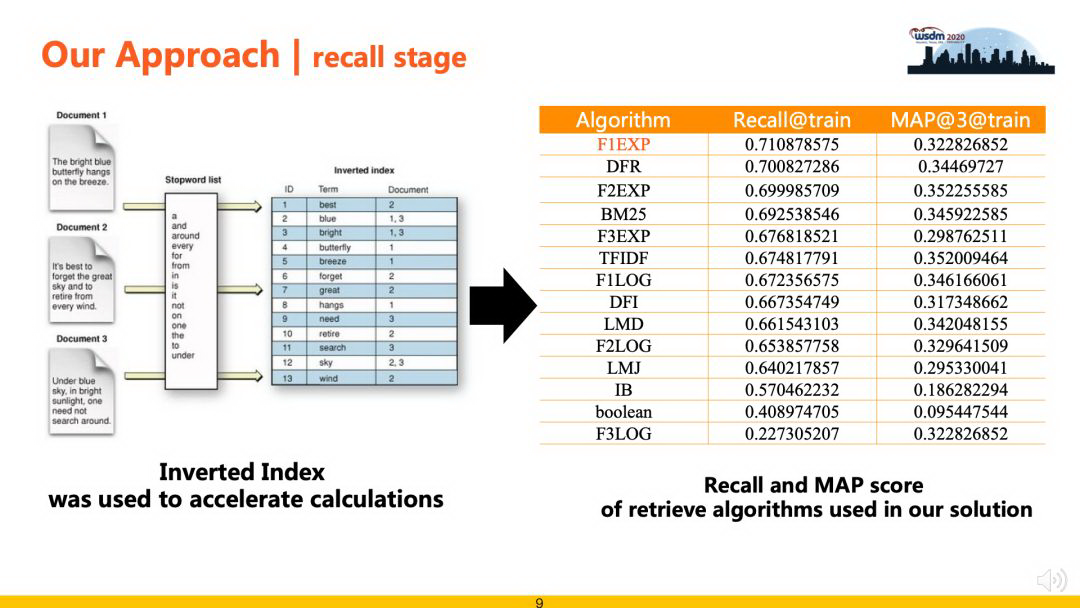
3.2 精准排序
精排阶段基于 Learning to Rank 的思想进行方案设计,提出了两种解决方案,一种是基于 Pairwise-BERT 的方案,另一种是基于 LightGBM 的方案,下面分别进行介绍:
1) 基于 BERT 的排序模型
BERT 是近年来 NLP 领域最重大的研究进展之一,本次评测中,我们也尝试引入 BERT 并对原始模型使用 Pointwise Approach 的模式进行改进,引入 Pairwise Approach 模式,在排序任务上取得了一定的效果提升。原始 BERT 使用 Pointwise 模式把排序问题看做单文档分类问题,Pointwise 优化的目标是单条 Query 与 Document 之间的相关性,即回归的目标是 label。而 Pairwise 方法的优化目标是两个候选文档之间的排序位次(匹配程度),更适合排序任务的场景。具体来说,对原始 BERT 主要有两点改进,如下图中所示:
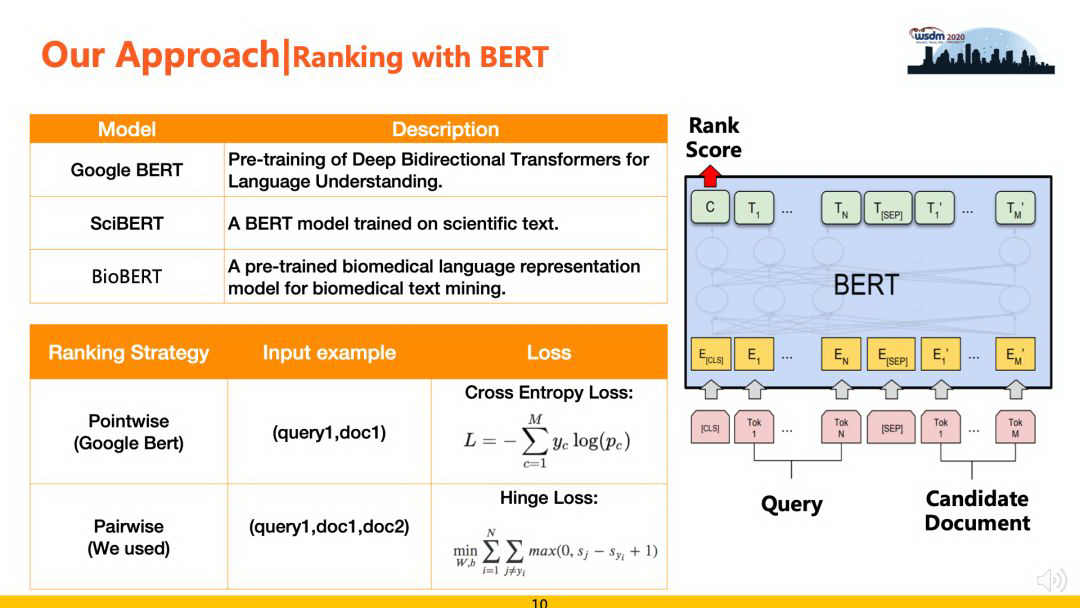
在基于 BERT 进行排序的过程中,由于评测数据多为生命科学领域的论文,我们还使用了 SciBERT 和 BioBERT 等基于特定领域语料的预训练 BERT 模型,相比 Google 的通用 BERT 较大的效果提升。
2) 基于 LightGBM 的排序模型
不过,上面介绍的基于 BERT 的方案构建的端到端的排序学习框架,仍然存在一些不足。首先,BERT 模型的输入最大为 512 个字符,对于数据中的部分长语料需要进行截断处理,这就损失了文本中的部分语义信息;其次,本任务中语料多来自科学论文,跟已有的预训练模型还是存在偏差,这也在一定程度上限制了模型对数据的表征能力。此外,BERT 模型网络结构较为复杂,在运行效率上不占优势。综合上述三方面的原因,我们提出了基于 LightGBM 的排序解决方案。
LightGBM 是微软 2017 年提出,比 Xgboost 更强大、速度更快的模型。LightGBM 在传统的 GBDT 基础上有如下创新和改进:
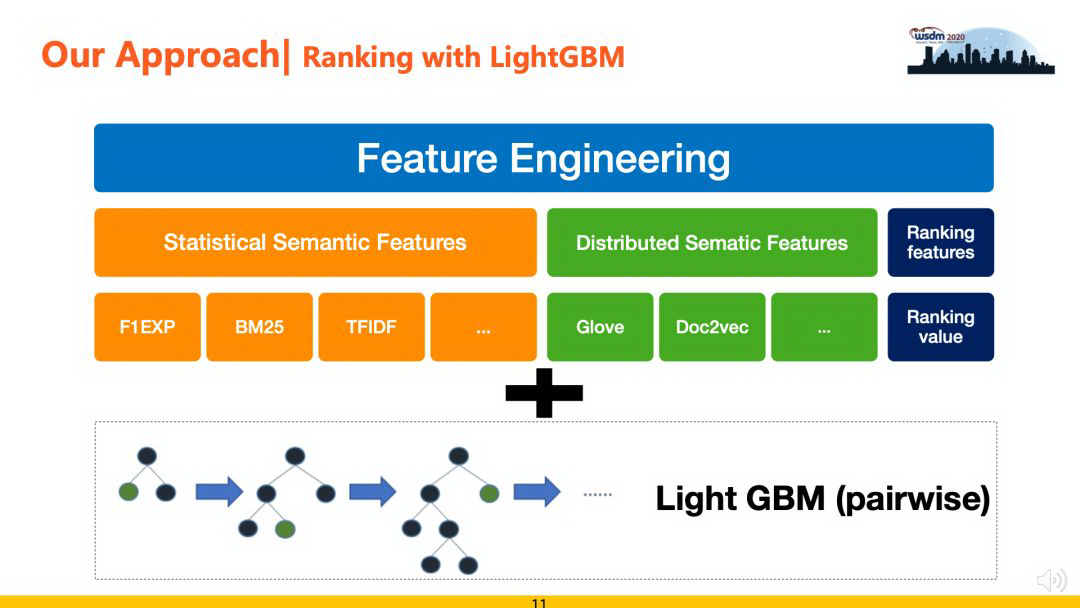
基于 Light GBM 的方案需要特征工程的配合。在我们实践中,特征主要包括 Statistic Semantic Features(包括 F1EXP、F2EXP、TFIDF、BM25 等)、Distributed Semantic Features(包括 Glove、Doc2vec 等)和 Ranking Features(召回阶段的排序序列特征),并且这些特征分别从标题、摘要、关键词等多个维度进行抽取,最终构建成特征集合,配合 LightGBM 的 pairwise 模式进行训练。该方法的优点是运行效率高,可解释性强,缺点是特征工程阶段比较依赖人工对数据的理解和分析。
4. 实验结果
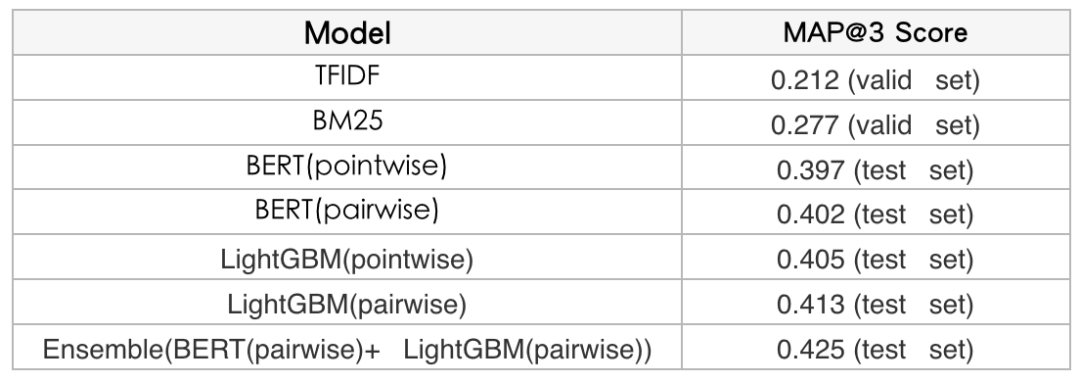
我们分别对比实验了不同方案的效果,可以发现无论是基于 BERT 的排序方案还是基于 LightGBM 的排序方案,Pairwise 的模式都会优于 Pointwise 的模式,具体实验数据如表 2 所示:
表 2 不同方案实验结果
5. 总结与展望
本文主要介绍了美团搜索与 NLP 部在 WSDM Cup 2020 Task 1 评测中的实践方案,我们构建了召回+排序的整体技术框架。在召回阶段引入多种召回策略和倒排索引保证召回的速度和覆盖率;在排序阶段提出了基于 Pairwise 模式的 BERT 排序模型和基于 LightGBM 的排序模型。最终,美团也非常荣幸地取得了榜单第一名的成绩。
当然,在对本次评测进行复盘分析后,我们认为该任务还有较大提升的空间。首先在召回阶段,当前方案召回率为 70%左右,可以尝试新的召回方案来提高召回率;其次,在排序阶段,还可以尝试基于 Listwise 的模式进行排序模型的训练,相比 Pairwise 的模式,Listwise 模式下模型输入空间变为 Query 跟全部 Candidate Doc,理论上可以使模型学习到更好的排序能力。后续,我们还会再不断进行优化,追求卓越。
6. 落地应用
本次评测任务与搜索与 NLP 部智能客服、搜索排序等业务中多个关键应用场景高度契合。目前,我们正在积极试验将获奖方案在智能问答、FAQ 推荐和搜索核心排序等场景进行落地探索,用最优秀的技术解决方案来提升产品质量和服务水平,努力践行“帮大家吃得更好,生活更好”的使命。
参考文献
[1] Fang H, Zhai C X. An exploration of axiomatic approaches to information retrieval[C]//Proceedings of the 28th annual international ACM SIGIR conference on Research and development in informationretrieval. 2005: 480-487.
[2] Wang Y, Yang P, Fang H. Evaluating Axiomatic Retrieval Models in the Core Track[C]//TREC. 2017.
[3] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[4] Lee J, Yoon W, Kim S, et al. BioBERT: a pre-trained biomedical language representation model for biomedical text mining[J]. Bioinformatics, 2020, 36(4): 1234-1240.
[5] Beltagy I, Lo K, Cohan A. SciBERT: A pretrained language model for scientific text[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 3606-3611.
[6] Chen W, Liu S, Bao W, et al. An Effective Approach for Citation Intent Recognition Based on Bert and LightGBM. WSDM Cup 2020, Houston, Texas, USA, February 2020.
[7] Ke G, Meng Q, Finley T, et al. Lightgbm: A highly efficient gradient boosting decision tree[C]//Advances in neural information processing systems. 2017: 3146-3154.
作者介绍 :
帅朋,美团 AI 平台搜索与 NLP 部。
会星,美团 AI 平台搜索与 NLP 部 NLP 中心对话平台负责人,研究员。
仲远,美团 AI 平台搜索与 NLP 部负责人,高级研究员、高级总监。
原文链接 :