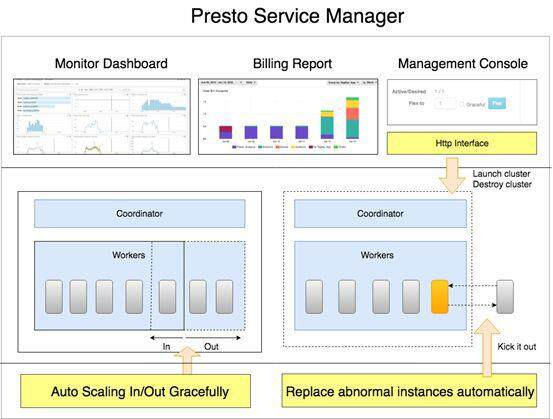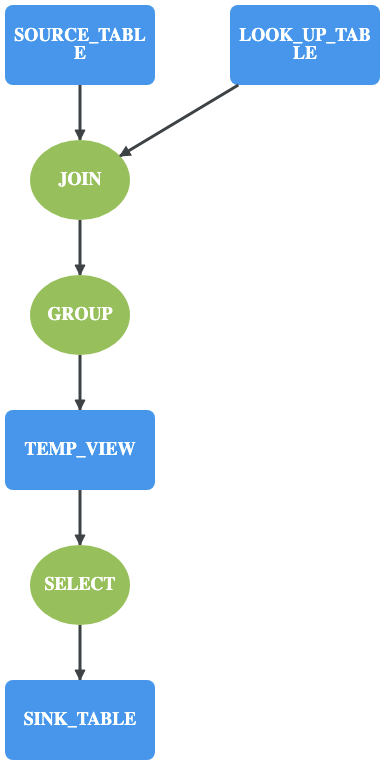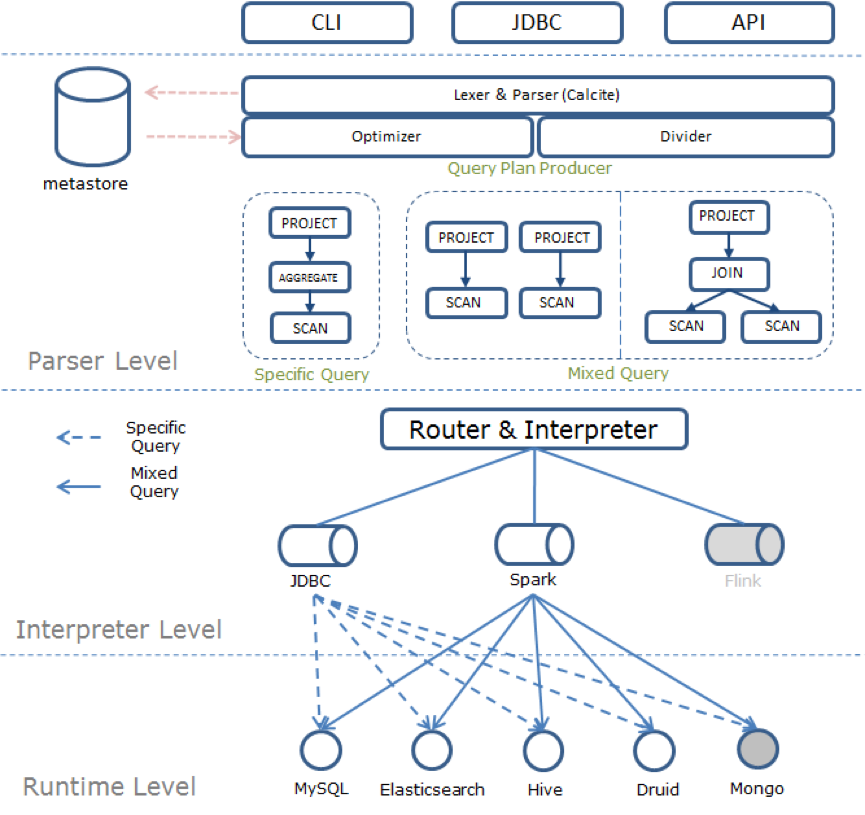
作者 | 卢冕,第四范式开源机器学习数据库 OpenMLDB PMC core member
1.背景介绍
1.1 机器学习闭环
今天,机器学习应用已经在各行各业积累了广泛的应用落地案例。归纳来说,机器学习从开发到上线的全生命周期闭环可以用下图(Figure-1)概括性描述。
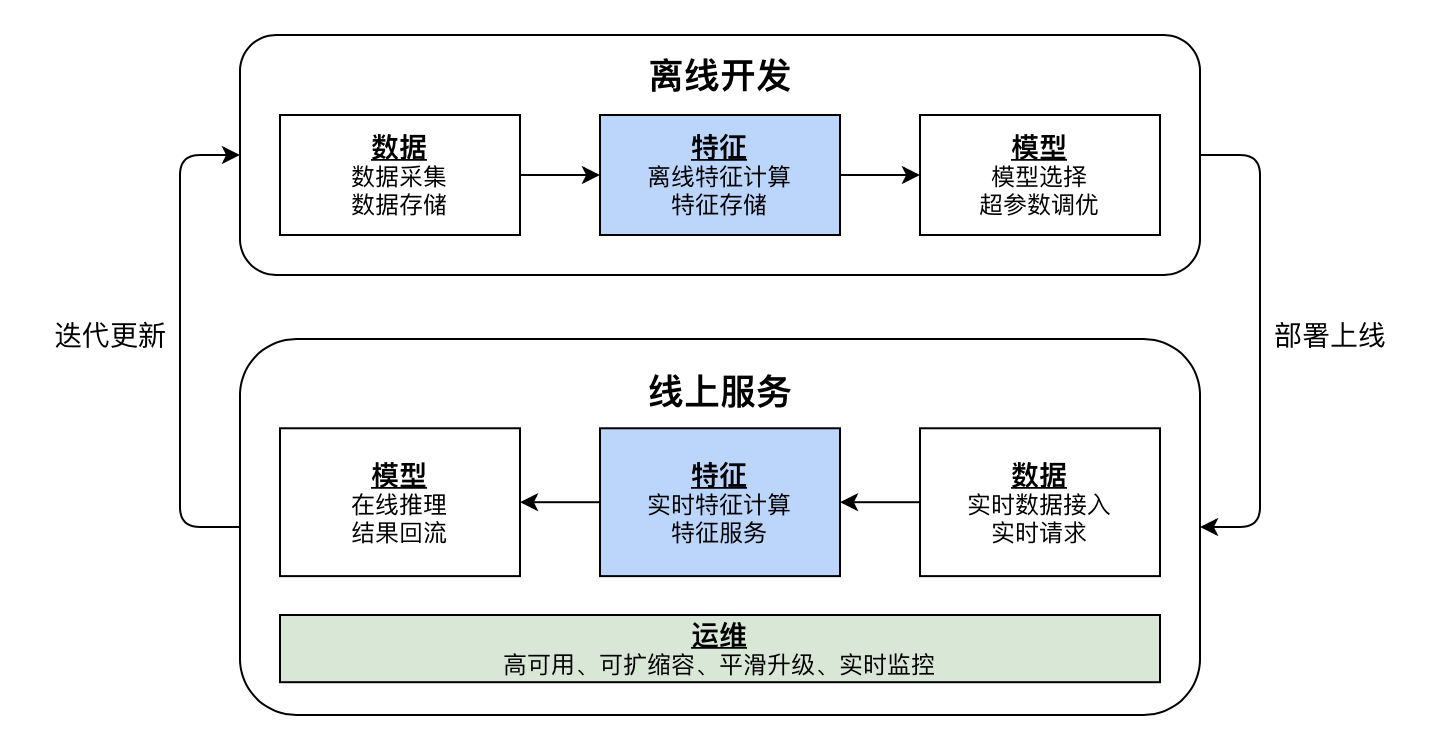
从 Figure-1 可以看到,从横向维度,机器学习全流程被划分成 离线开发 和 线上服务 两个相辅相成的流程。从纵向维度,信息价值承载的形式会经历从数据、特征、再到模型的转换过程。
对于决策类场景,特征工程的处理逻辑相对灵活和复杂,因此在这一块目前尚未形成标准化的方法论和工具。这也正是本文所要聚焦的领域,通过从设计方法论和架构设计实践的阐述,让大家深刻理解实时特征计算系统及其典型使用流程。
1.2 实时特征计算
本文主要关注具有非常强时效性的实时特征计算,其查询计算的端到端延迟一般设定在几十毫秒的量级。实时特征的常见计算模式,是当事件发生时,基于从当前时间点往前推移的一个时间点,形成一个时间窗口,进行窗口内的相关聚合计算。
如下图 Figure-2 列举了一个典型的风控领域的实时特征计算场景,其产生了十天、一个小时、五分钟三个时间窗口,基于窗口进行了不同的聚合计算。
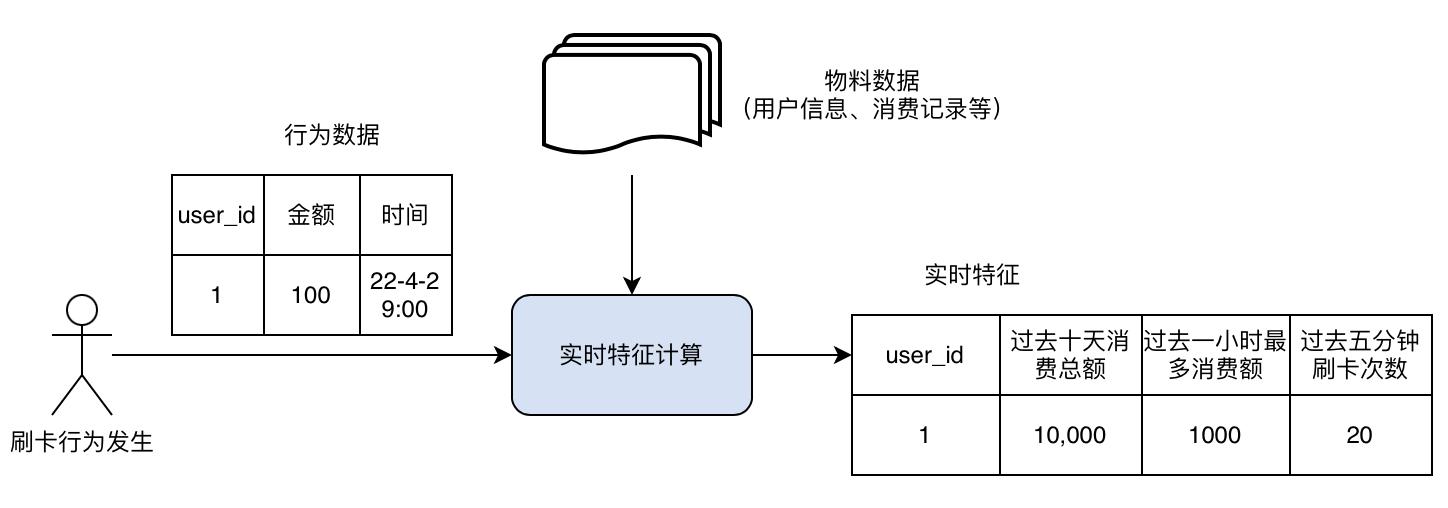
Figure-2: 风控领域的典型实时特征计算举例
实时特征计算今天已经在越来越多的场景中体现出其重要性,其本质在于抓住最新时间段内的数据特征,为快速决策提供有力支撑。本文主要针对实时特征计算,来进行相关设计理念和架构的阐述。
2.线上线下计算一致性架构
2.1. 痛点:两套开发流程和线上线下计算一致性校验
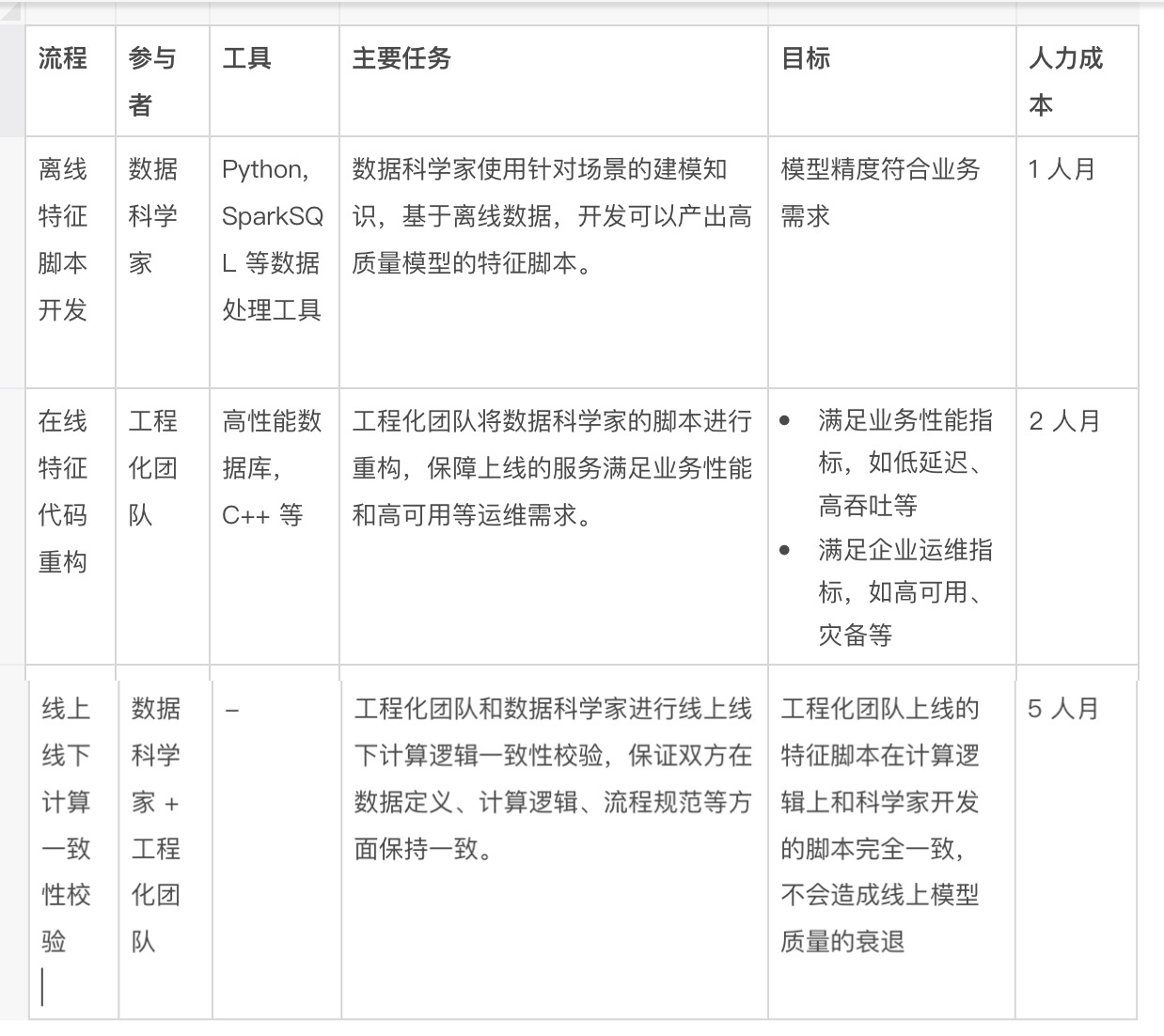
今天,在没有一套合适的方法论和工具链的情况下,如果需要开发上线一套实时特征计算逻辑,主要包含三个步骤,即离线特征脚本开发、在线特征代码重构、以及线上线下计算逻辑一致性校验。其三者的关系如下图 Figure-3 所示。
Figure-3: 在缺少合适的工具情况下的实时特征计算从开发到上线全流程
这三个步骤主要完成的任务以及参与者见下方表格 Table-1。从 Table-1 中可以看到几个关键信息:
造成线上线下计算逻辑不一致的原因有很多种,比如:
2.2. 目标:开发即上线
我们已经认识到,线上线下计算一致性校验是整个系统实现和实施的瓶颈。那么理想中,如果需要改进整体流程,我们期望有一套开发即上线的高效流程。其如下图 Figure-4 所示。
在此套优化过的流程中,数据科学家的脚本可以即刻部署上线,而不需要再经过二次代码重构,也不需要额外的线上线下一致性校验。如果基于此流程的方法论可以实现,将会极大地提高实时特征从开发到上线的整体流程,其人力成本也将会从过去的一共 8 人月大幅缩短到 1 人月。
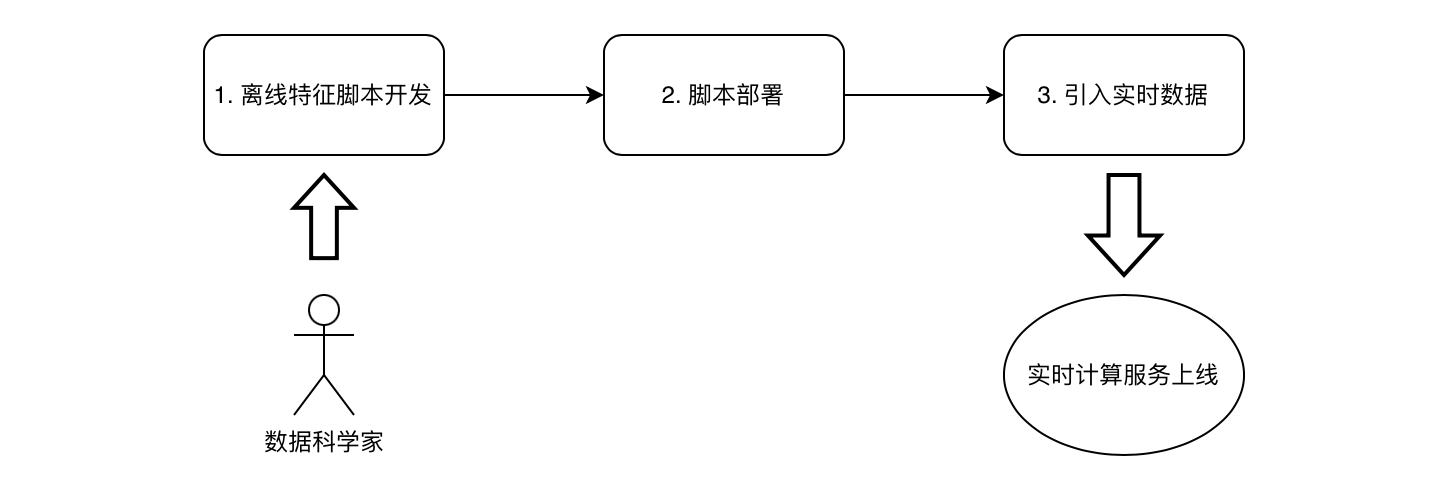
Figure-4: 实时特征计算开发周期的优化目标:开发即上线流程
2.3. 技术需求
如果为了达到开发即上线的优化目标,同时要保证实时计算的高性能,可以总结出整套架构需要满足如下的技术需求:
2.4. 抽象架构
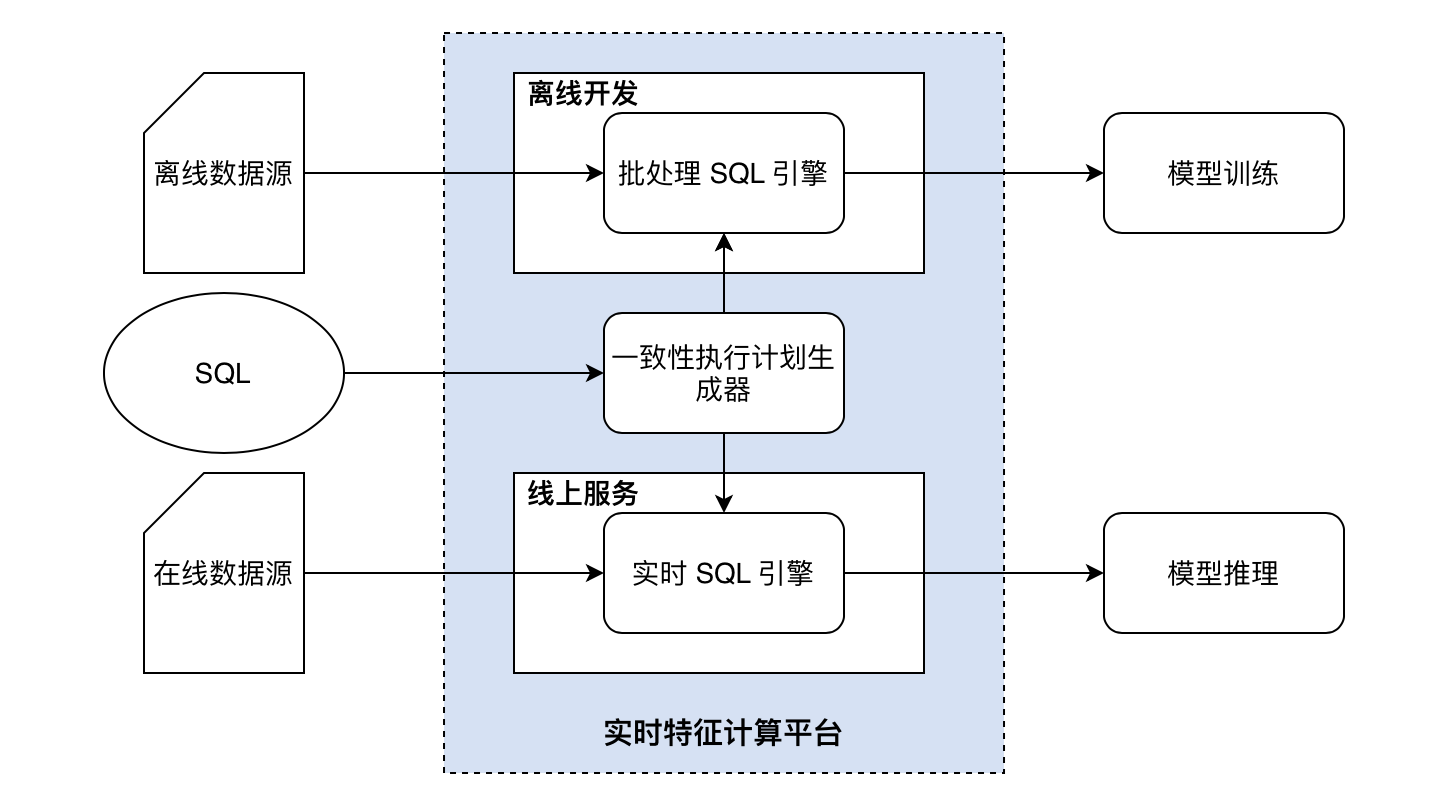
Figure-5: 开发即上线的实时特征平台的抽象架构
为了满足在章节 2.3 里提到的三个技术需求,我们构建出了如上 Figure-5 的抽象架构。可以看到,在这个抽象架构图里有三大模块,分别对应去解决我们所面临的的技术挑战。
以下表格列出了模块的功能要点以及所解决的技术需求。
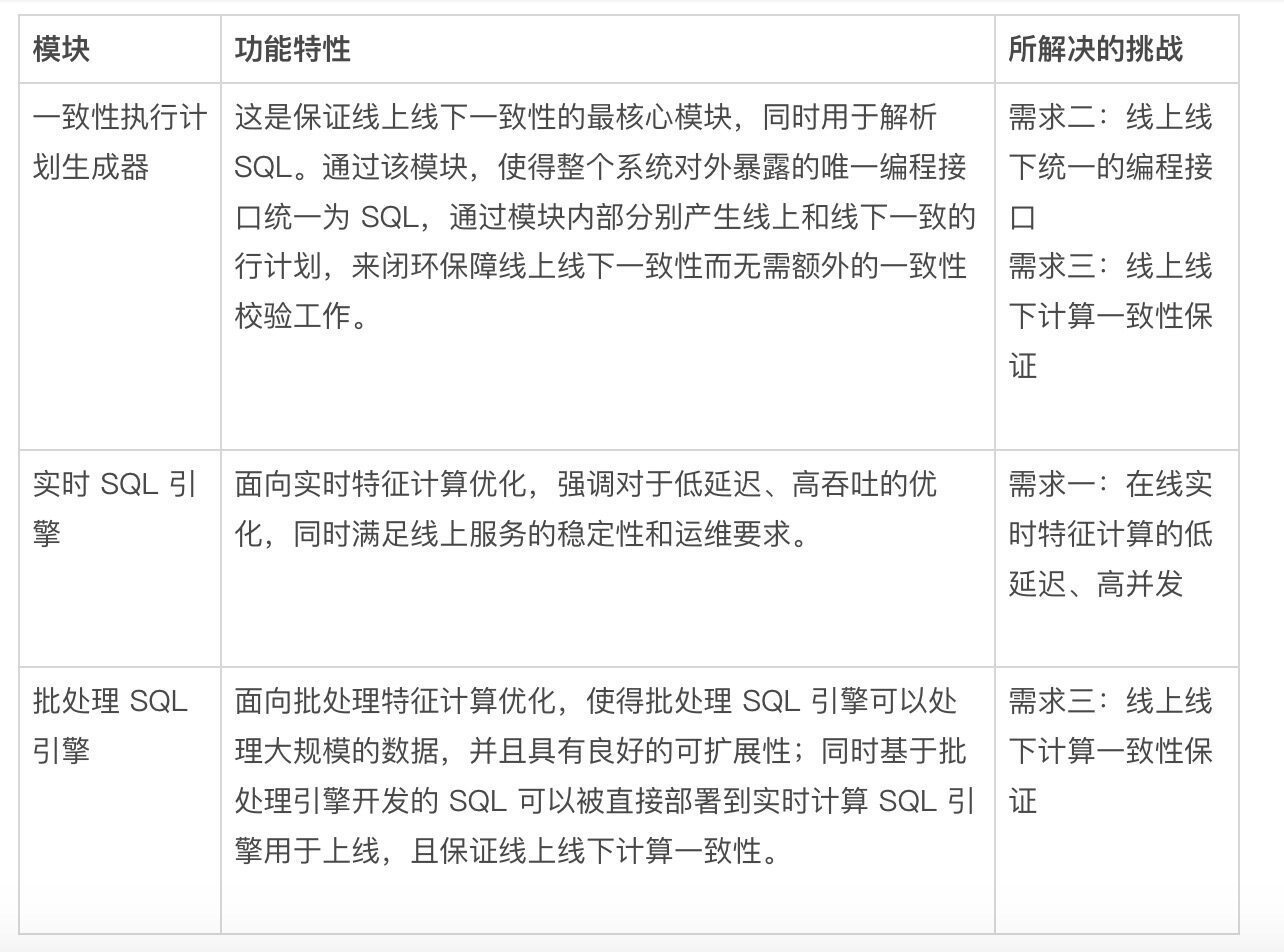
Table-2: 实时特征计算平台架构的核心模块和功能
3.OpenMLDB 的架构设计实践
基于如上分析的 Figure-5 的抽象架构,以及 Table-2 所列举的核心模块功能,我们在此介绍一下 OpenMLDB 的架构实践。
OpenMLDB (是一款开源机器学习数据库,主要面向特征计算场景构建高效解决方案。
OpenMLDB 的架构设计上秉承了 Figure-5 所列的抽象架构,通过基于现有开源软件优化或者自研,来实现具体的功能。其具象化以后的架构如下图 Figure-6 所示。
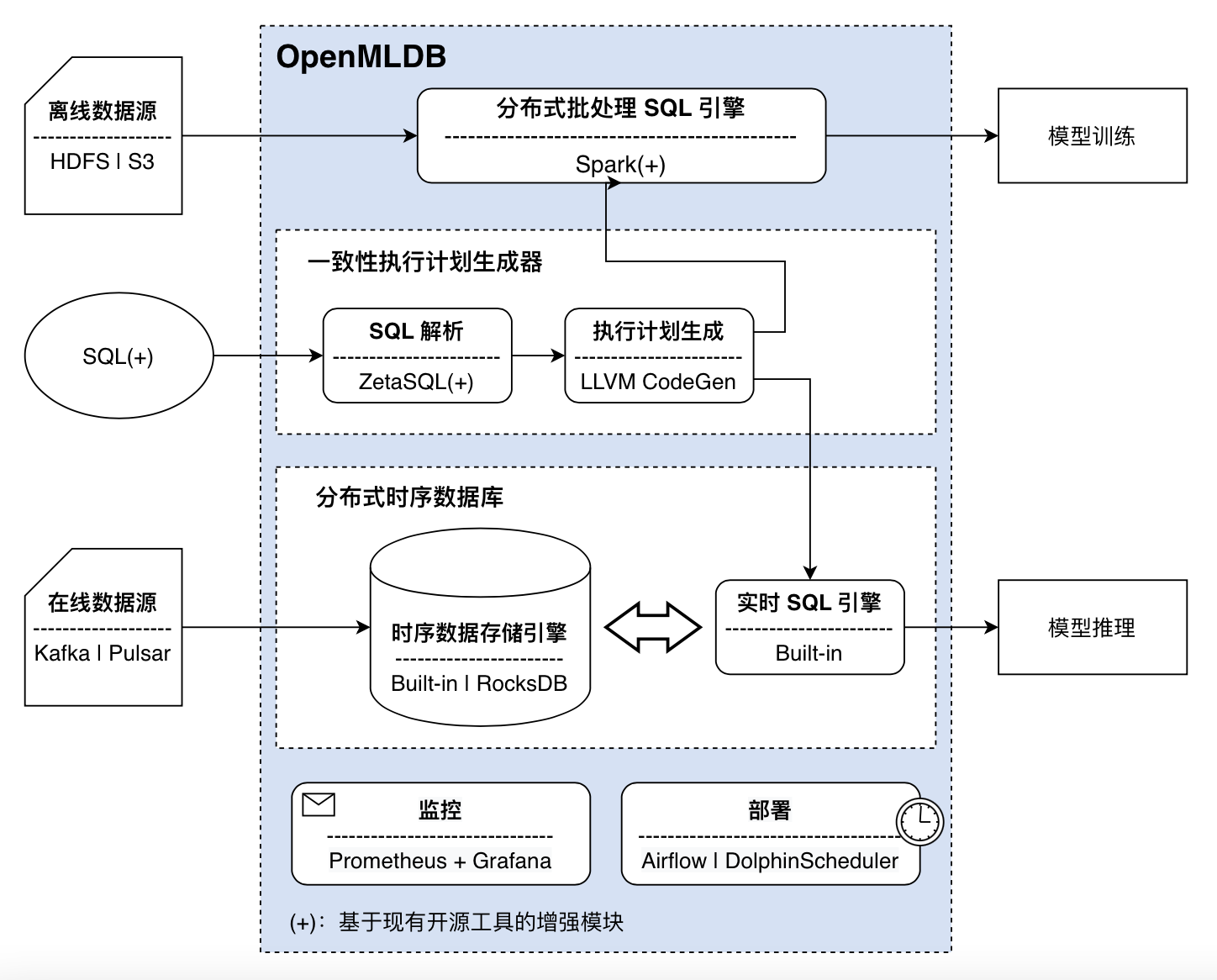
从架构图 Figure-6 上可以看到,OpenMLDB 有几个关键模块,说明如下:
一是,开发团队自研的内存存储引擎(built-in):OpenMLDB 为了优化在线处理的延迟和吞吐,默认采用了基于内存的存储方案,构建了双层跳表(double-layered skip list)的索引结构。此种数据结构特别适合快速找到某个 key 下面的一个按照时间戳排序的数据。此种内存索引结构在时序数据的查找延迟上可以达到毫秒级别 [1],并且性能远好于商业版的内存数据库;二是,基于 RocksDB 的外存存储引擎:如果用户对于性能不太敏感,但是希望降低内存用成本,用户亦可以选择基于 RocksDB 的外存存储引擎。通过以上核心组件的串联,OpenMLDB 可以实现开发即上线的最终优化目标。
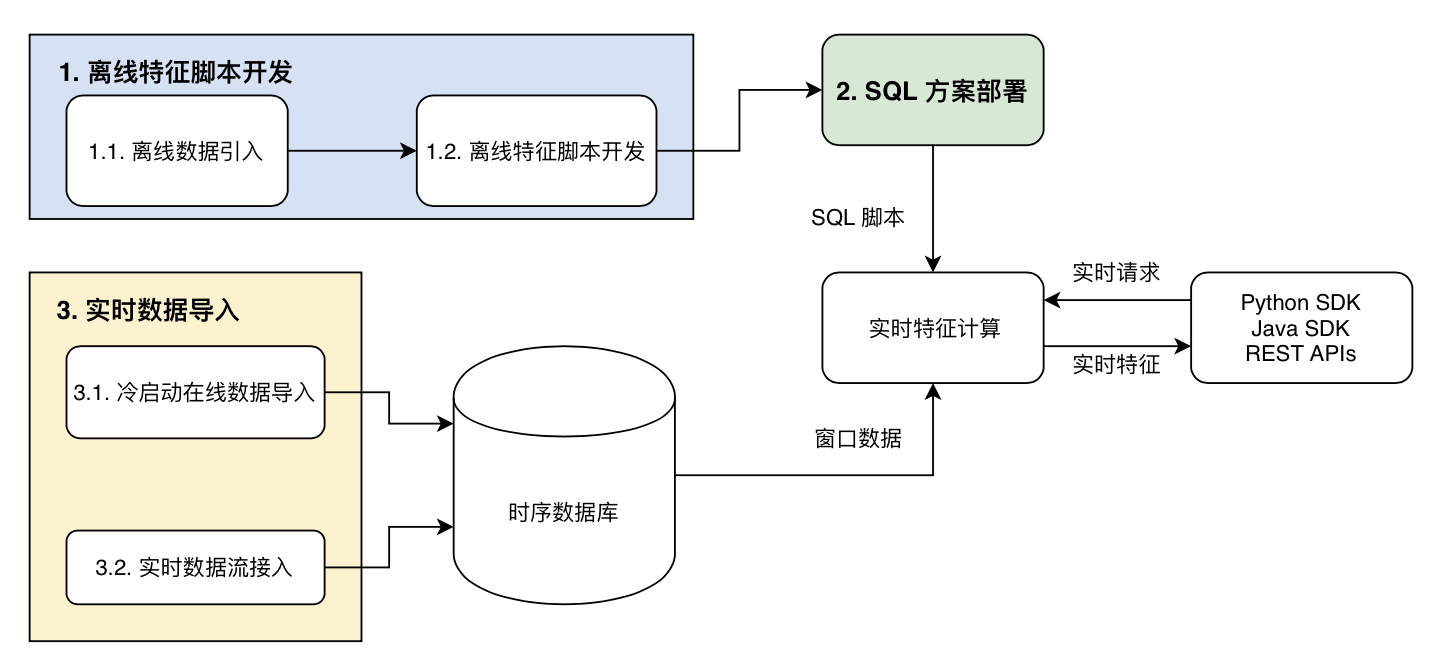
下图 Figure-7 总结了 OpenMLDB 从离线开发到部署上线的整体使用流程。对照 Figure-4 所对应的优化流程目标,我们可以发现,通过 OpenMLDB,从特征开发到上线,很好地践行了开发即上线的核心思想。
Figure-7: OpenMLDB 使用流程
关于 OpenMLDB 的详细信息可以参考以下内容:
4.总结
本文总结了构建实时特征计算平台所面临的工程化挑战,以及工业界所期望的从离线开发到上线的优化目标。基于目标,展开描述了架构设计的方法论和原则。最后介绍了从优化目标出发,基于设计方法论实践的开源解决方案 OpenMLDB 的整体架构。
参考 :
[1] Cheng Chen, Jun Yang, Mian Lu, Taize Wang, Zhao Zheng, Yuqiang Chen, Wenyuan Dai, Bingsheng He, Weng-Fai Wong, Guoan Wu, Yuping Zhao, and Andy Rudoff.Optimizing in-memory>
作者介绍:
卢冕,博士毕业于香港科技大学计算机系;现为 OpenMLDB 社区 PMC core member;就职于第四范式,是数据库团队以及高性能计算团队的 Tech Lead。