背景介绍
网易云音乐从 2018 年开始搭建实时计算平台,到目前为止已经发展至如下规模:

这是网易云音乐实时数仓 18 年的版本,基于 Flink 1.7 版本开发,当时 Flink SQL 的整体架构也还不是很完善。我们使用了 Antlr (通用的编程语言解析器,它只需编写名为 G4 的语法文件,即可自动生成解析的代码,并且以统一的格式输出,处理起来非常简单。由于 G4 文件是通过开发者自行定制的,因此由 Antlr 生成的代码也更加简洁和个性化)自定义了一些 DDL 完善了维表 join 的语法。通过 Antlr 完成语法树的解析以后,再通过 CodeGen(根据接口文档生成代码)技术去将整个 SQL 代码生成一个 Jar 包,然后部署到 Flink 集群上去。
此时还没有统一的元数据管理系统。在 JAR 包任务的开发上,我们也没有任何框架的约束,平台也很难知道 JAR 的任务上下游以及相关业务的重要性和优先级。这套架构我们跑了将近一年的时间,随着任务越来越多,我们发现了以下几个问题:
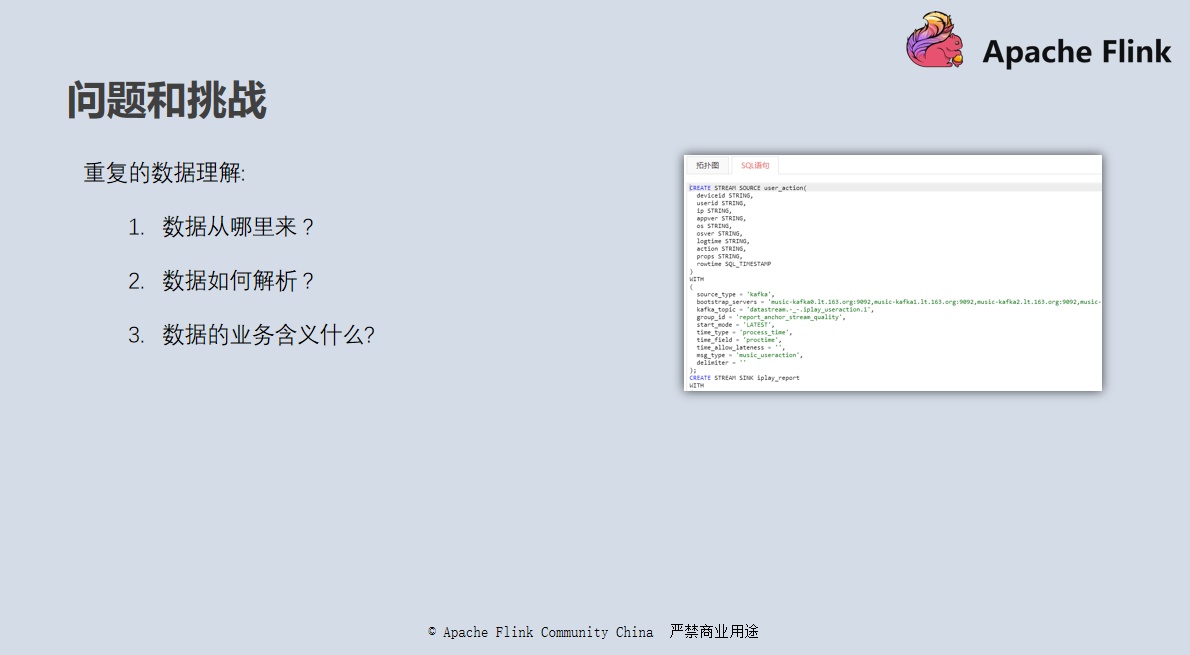
重复的数据理解
由于没有进行统一的元数据管理,每个任务的代码里面都需要预先定义 DDL 语句,然后再进行 Select 等业务逻辑的开发;消息的元数据不能复用,每个开发都需要进行重复的数据理解,需要了解数据从哪里来、数据如何解析、数据的业务含义是什么;整个过程需要多方沟通,整体还存在理解错误的风险;也缺乏统一的管理系统去查找自己想要的数据。

和官方版本越走越远
由于早期版本很多 SQL 的语法都是我们自己自定义的,随着 Flink 本身版本的完善,语法和官方版本差别越来越大,功能完善性上也渐渐跟不上官方的版本,易用性自然也越来越差。如果你本身就是一名熟知 Flink SQL 的开发人员,可能还需要重新学习我们平台自己的语法,整体不是很统一,有些问题也很难在互联网上找到相关的资料,只能靠运维来解决。

任务运维问题
SQL 任务没有统一的元数据管理、上下游的数据源没有统一的登记、JAR 包任务没有统一的框架约束、平台方很难跟踪整个平台数据流的走向,我们不知道平台上运行的几百个任务分别是干什么的,哪些任务读了哪个数据源?输出了什么数据源?任务的种类是什么?是线上的,测试的,重要的还是不重要的。没有这些数据的支撑,导致整个运维工作非常局限。
网易云音乐的业务发展非常快,数据量越来越大,线上库和一些其它的库变更十分频繁,相关的实时任务也要跟着业务架构的调整,变更相关数据源的地址。此时我们就需要知道哪些任务用到了相关的数据源,如果平台没有能力很快筛选出相关任务,整个流程处理起来就十分繁杂了。
首先,需要联系平台所有的开发者确认是否有相关任务的数据源,整个流程非常浪费时间,而且还有可能产生疏漏;其次,假设出现平台流量激增,做运维工作时,如果我们不知道任务在干什么,自然也不能知道的任务的重要性,不知道哪些任务可以限流,哪些任务可以做暂时性的停止,哪些任务要重点保障。
实时数仓建设

带着这些问题,我们开始进行新版本的构建工作。
元数据中心
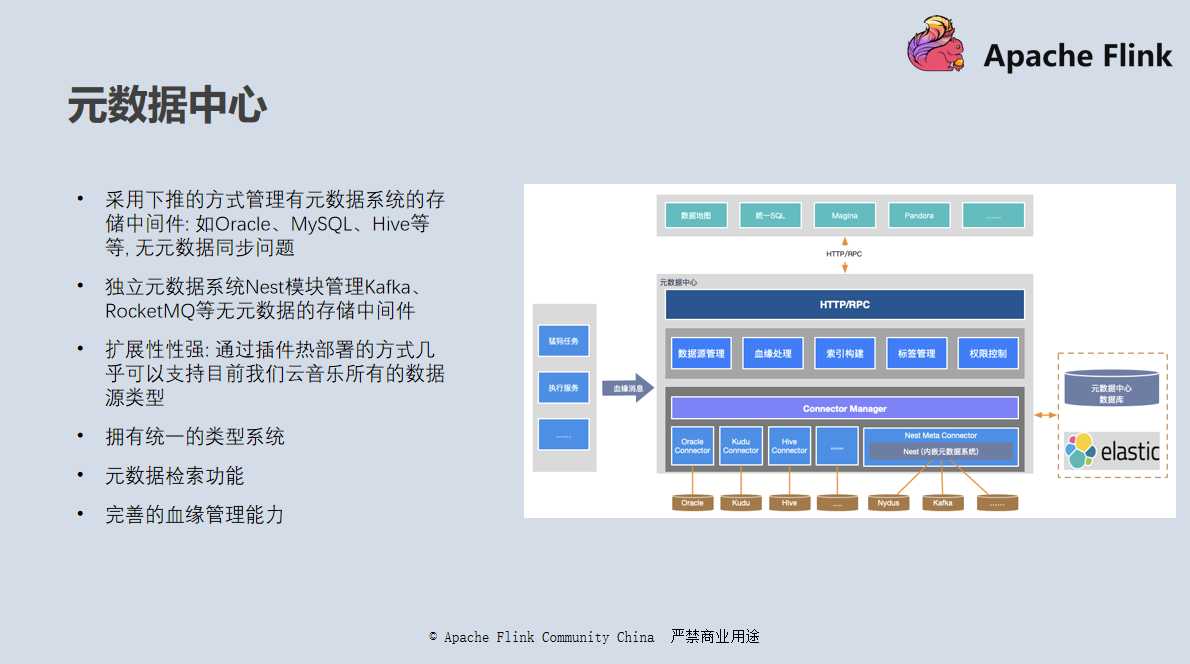
不知道大家有没有用过 Apache Atlas、Netflix 的 Metacat 等工具,网易云音乐的元数据中心顾名思义就是一个元数据管理的程序,用于管理网易云音乐所有数据源的元数据。你有可能在实际的开发中用到 Oracle、Kudu、Hive 等工具,也有可能是自研的分布式数据库。如果没有统一的元数据管理,我们很难知道我们有哪些数据,数据是如何流转的,也很难快速找到自己想要的数据。
我们的元数据中心系统有以下几个特点:
建设流程
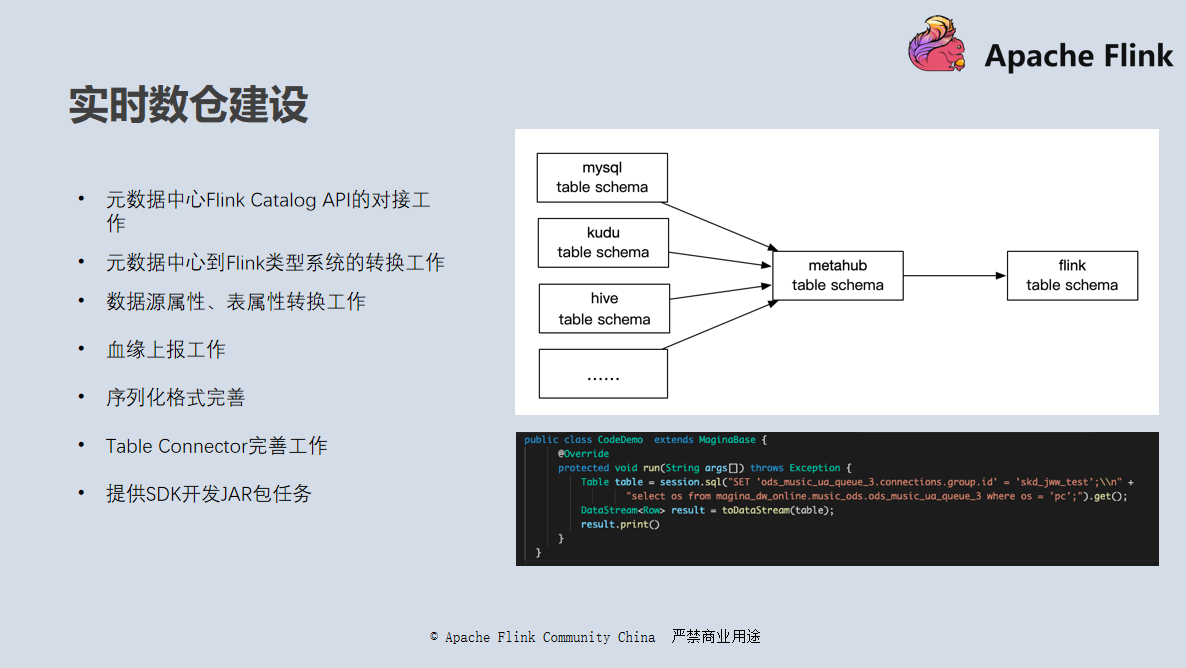
需要进行的工作包括:
完成以上工作后,整体基本就能实现我们的预期。
在一个 Flink 任务的开发中,涉及的数据源主要有三类:
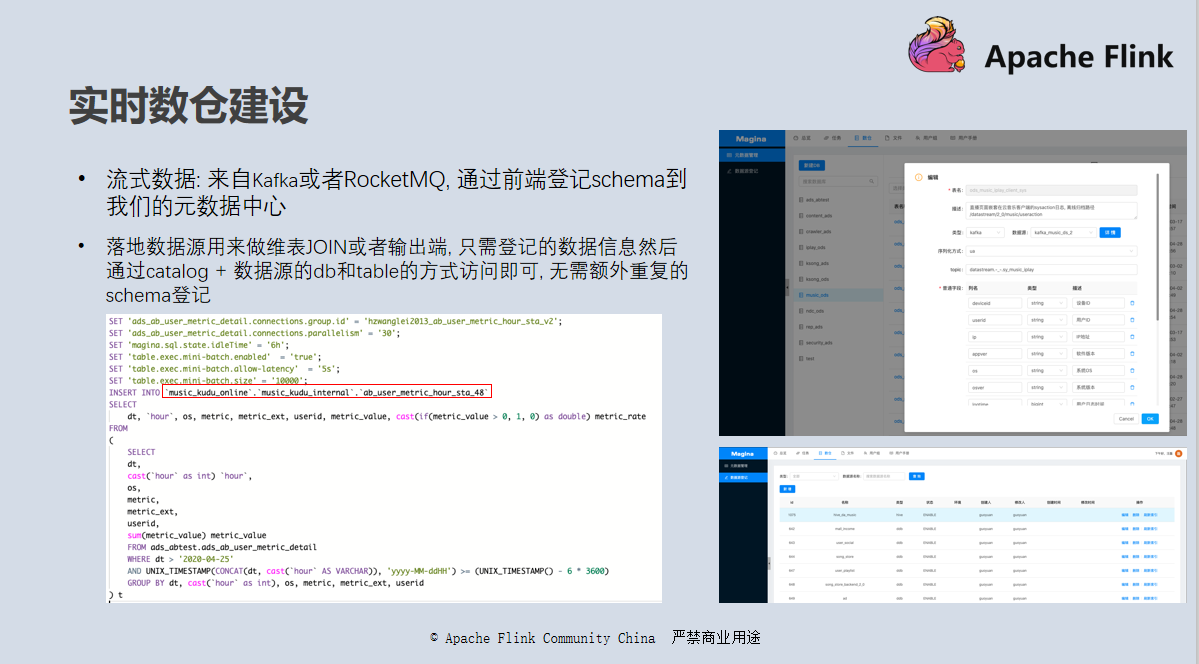
对于流式数据,我们使用元数据中心自带的元数据系统 Nest 登记管理(参考右上角的图);对于维表以及落地数据源等,可以直接通过元数据中心获取库表 Schema 信息,无需额外的 Schema 登记,只需要一次性登记下数据源连接信息即可(参考右下角的图)。整体对应我们系统中数仓模块的元数据管理、数据源登记两个页面。
完成登记工作以后,我们可以通过
[catalog.][db.][table]
等方式访问任一元数据中心中登记的表,进行 SQL 开发工作。其中 Catalog 是在数据源登记时登记的名字;db 和 table 是相应数据源自身的 DB 和 Table,如果是 MySQL 就是 MySQL 自身元数据中的 DB 和 Table。
最终效果可以参考左下角读取实时表数据写入 Kudu 的的例子,其中红框部分是一个 Kudu 数据表,在使用前只需要登记相关连接信息即可,无需登记表信息,平台会从元数据中心获取。
ABTest 项目实践
项目说明

ABTest 是目前各大互联网公司用来评估前端改动或模型上线效果的一种有效手段,它主要涉及了两类数据:第一个是用户分流数据,一个 AB 实验中用户会被分成很多组;然后就是相关指标统计数据,我们通过统计不同分组的用户在相应场景下指标的好坏,来判断相关策略的好坏。这两类数据被分为两张表:
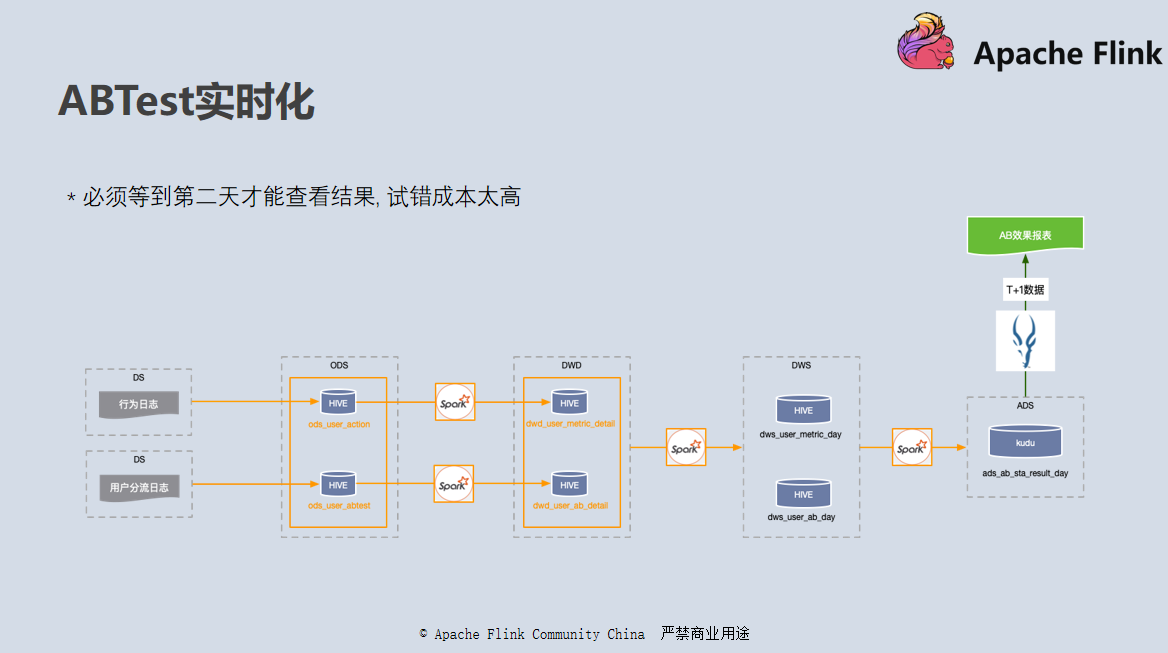
在早期版本中,我们使用 Spark 按照小时粒度完成从 ODS 到 DWD 层数据清洗工作,生成用户分流表和指标统计表。然后再使用 Spark 关联这两张表的数据将结果写入到 Kudu 当中,再使用 Impala 系统对接,供用户进行查询。
这套方案的最大的问题是延迟太高,往往需要延迟一到两个小时,有些甚至到第二天才能看到结果。对于延迟归档的数据也不能及时对结果进行修正。
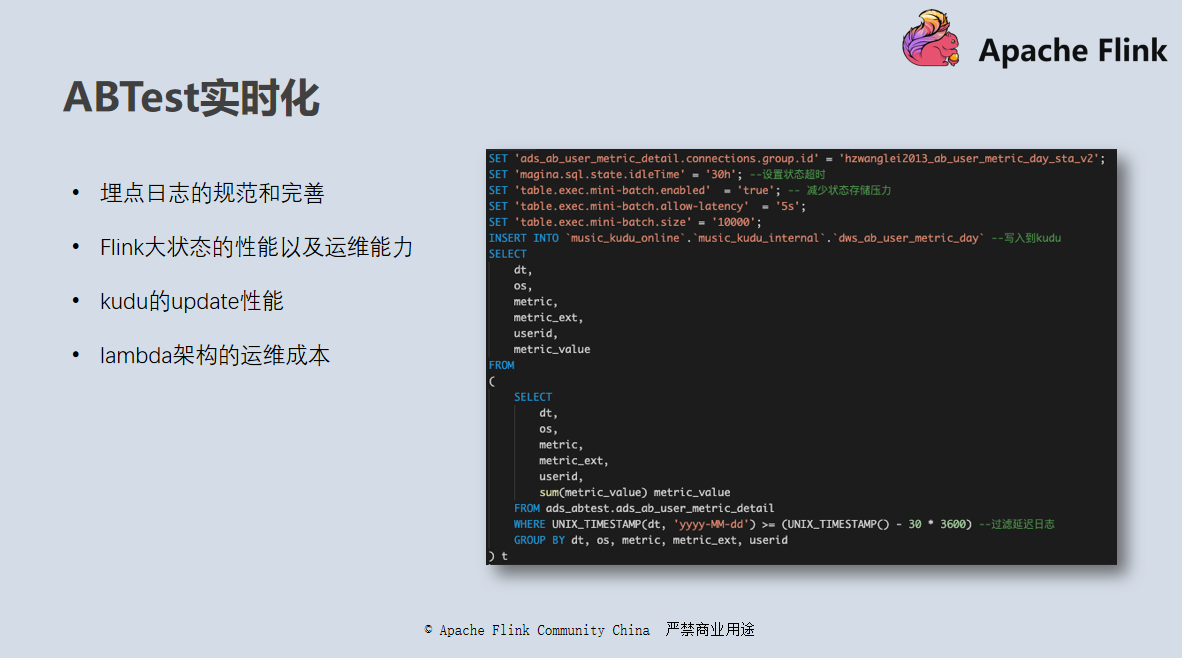
这个方案对我们的业务方比如算法来说,上线一个模型需要等到两个小时甚至第二天才能看到线上的效果,试错成本太高,所以后来使用新版的实时仓开发了一套实时版本。
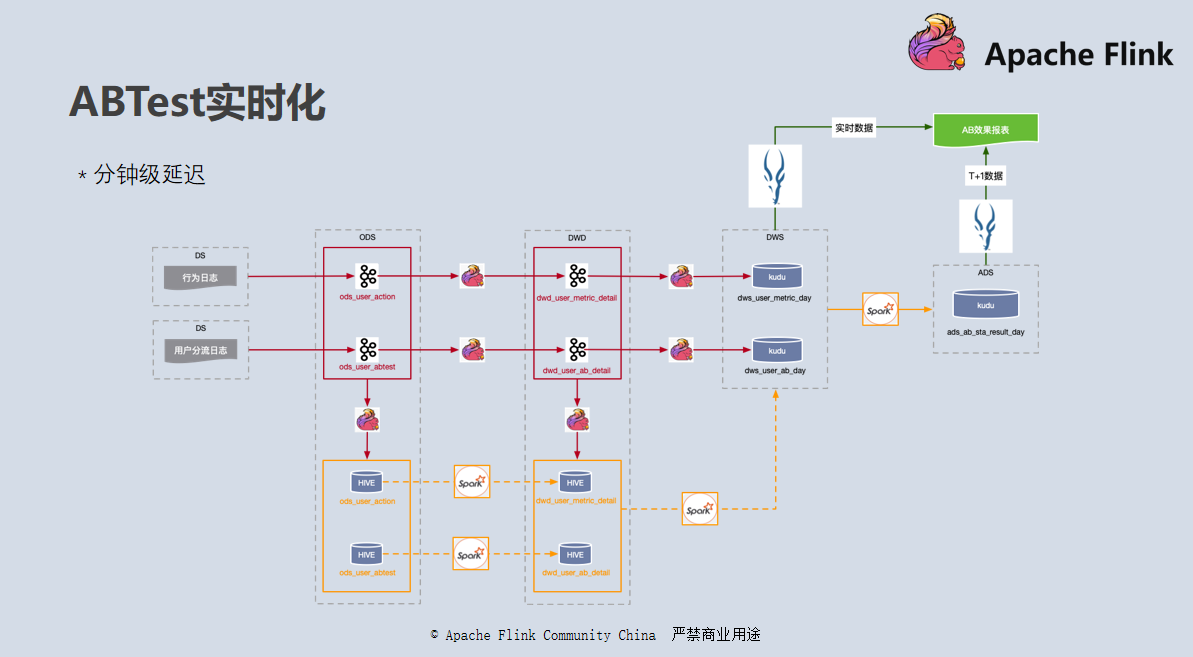
如上图所示,是我们实时版本 ABTest 的数据走向,我们整体采用了 Lambda 架构:
批流一体
前面介绍的 ABTest 实时化整个实现过程就是一套完整的批流一体 Lambda 架构的实现。ODS 和 DWD 层既可以订阅访问,也可以批量读取。DWD 层落地在支持更新操作的 Kudu 当中,和上层 OLAP 引擎对接,为用户提供实时的结果。目前实现上还有一些不足,但是未来批流一体的努力方向应该能看得比较清楚了。
我们认为批流一体主要分以下三个方面:
1. 结果的批流一体
使用数据的人不需要关心数据是批处理还是流处理,在提交查询的那一刻,拿到的结果就应该是截止到目前这一刻最新的统计结果,对于最上层用户来说没有批和流的概念。
2. 存储的批流一体
上面的 ABTest 例子中我们已经看到 DWD、DWS 层数据的存储上还有很多不足,业界也有一些相应解决方案等待去尝试,我们希望的批流一体存储需要以下几个特性:
3.计算引擎的批流一体
做到一套代码解决批流统一场景,降低开发运维成本,这个也是 Flink 正在努力的方向,未来我们也会在上面做一些尝试。