11 月 08 日>
如果大家想测试这个版本,可以到这里下载。src="https://static001.infoq.cn/resource/image/cc/17/cc643db38a64c6b6e0dcac0af5a11b17.png"/>
Apache Spark 3.0 增加了很多令人兴奋的新特性,包括动态分区修剪(Dynamic Partition Pruning)、自适应查询执行(Adaptive Query Execution)、加速器感知调度(Accelerator-aware Scheduling)、支持 Catalog 的数据源 API(Data Source API with Catalog Supports)、SparkR 中的向量化(Vectorization in SparkR)、支持 Hadoop 3/JDK 11/Scala 2.12 等等。Spark 3.0.0-preview 中主要特性和变化的完整列表请参阅这里。下面我将带领大家解析一些比较重要的新特性。

PS:仔细同学可以看出,Spark 3.0 好像没多少 Streaming/Structed Streaming 相关的 ISSUE,这可能有几个原因:
动态分区修剪(Dynamic Partition Pruning)
所谓的动态分区裁剪就是基于运行时(run time)推断出来的信息来进一步进行分区裁剪。举个例子,我们有如下的查询:
SELECT * FROM dim_iteblogJOIN fact_iteblogON (dim_iteblog.partcol = fact_iteblog.partcol)WHERE dim_iteblog.othercol > 10假设 dim_iteblog 表的 dim_iteblog.othercol > 10 过滤出来的数据比较少,但是由于之前版本的 Spark 无法进行动态计算代价,所以可能会导致 fact_iteblog 表扫描出大量无效的数据。有了动态分区裁减,可以在运行的时候过滤掉 fact_iteblog 表无用的数据。经过这个优化,查询扫描的数据大大减少,性能提升了 33 倍。
这个特性对应的 ISSUE 可以参见 SPARK-11150 和 SPARK-28888。具体请参见一文了解 Apache Spark 3.0 动态分区裁剪(Dynamic Partition Pruning)
自适应查询执行(Adaptive Query Execution)
自适应查询执行(又称 Adaptive Query Optimisation 或者 Adaptive Optimisation)是对查询执行计划的优化,允许 Spark Planner 在运行时执行可选的执行计划,这些计划将基于运行时统计数据进行优化。
早在 2015 年,Spark 社区就提出了自适应执行的基本想法,在 Spark 的 DAGScheduler 中增加了提交单个 map stage 的接口,并且在实现运行时调整 shuffle partition 数量上做了尝试。但目前该实现有一定的局限性,在某些场景下会引入更多的 shuffle,即更多的 stage,对于三表在同一个 stage 中做 join 等情况也无法很好的处理;而且使用当前框架很难灵活地在自适应执行中实现其他功能,例如更改执行计划或在运行时处理倾斜的 join。所以该功能一直处于实验阶段,配置参数也没有在官方文档中提及。这个想法主要来自英特尔以及百度的大牛,具体参见 SPARK-9850,对应的文章可以参见看完这篇文章还不懂 Spark 的 Adaptive Execution。
而 Apache Spark 3.0 的 Adaptive Query Execution 是基于 SPARK-9850 的思想而实现的,具体参见 SPARK-23128。SPARK-23128 的目标是实现一个灵活的框架以在 Spark SQL 中执行自适应执行,并支持在运行时更改 reducer 的数量。新的实现解决了前面讨论的所有限制,其他功能(如更改 join 策略和处理倾斜 join)将作为单独的功能实现,并作为插件在后面版本提供。
加速器感知调度(Accelerator-aware Scheduling)
如今大数据和机器学习已经有了很大的结合,在机器学习里面,因为计算迭代的时间可能会很长,开发人员一般会选择使用 GPU、FPGA 或 TPU 来加速计算。在 Apache Hadoop 3.1 版本里面已经开始内置原生支持 GPU 和 FPGA 了。作为通用计算引擎的 Spark 肯定也不甘落后,来自>

目前 Apache Spark 支持的资源管理器 YARN 和 Kubernetes 已经支持了 GPU。为了让 Spark 也支持 GPUs,在技术层面上需要做出两个主要改变:
因为让 Apache Spark 支持 GPU 是一个比较大的特性,所以项目分为了几个阶段。在 Apache Spark 3.0 版本,将支持在 standalone、 YARN 以及 Kubernetes 资源管理器下支持 GPU,并且对现有正常的作业基本没影响。对于 TPU 的支持、Mesos 资源管理器中 GPU 的支持、以及 Windows 平台的 GPU 支持将不是这个版本的目标。而且对于一张 GPU 卡内的细粒度调度也不会在这个版本支持;Apache Spark 3.0 版本将把一张 GPU 卡和其内存作为不可分割的单元。详情请参见 过往记忆大数据公众号的 Apache Spark 3.0 将内置支持 GPU 调度 文章。
Apache Spark>Data Source API 定义如何从存储系统进行读写的相关 API 接口,比如 Hadoop 的 InputFormat/OutputFormat,Hive 的 Serde 等。这些 API 非常适合用户在 Spark 中使用 RDD 编程的时候使用。使用这些 API 进行编程虽然能够解决我们的问题,但是对用户来说使用成本还是挺高的,而且 Spark 也不能对其进行优化。为了解决这些问题,Spark 1.3 版本开始引入了>
Data Source API V1 为我们抽象了一系列的接口,使用这些接口可以实现大部分的场景。但是随着使用的用户增多,逐渐显现出一些问题:
为了解决>
更多关于 Apache Spark target="_blank">一文理解 Apache Spark top="4019.296875">更好的 ANSI SQL 兼容
PostgreSQL 是最先进的开源数据库之一,其支持 SQL:2011 的大部分主要特性,完全符合 SQL:2011 要求的 179 个功能中,PostgreSQL 至少符合 160 个。Spark 社区目前专门开了一个 ISSUE SPARK-27764 来解决 Spark SQL 和 PostgreSQL 之间的差异,包括功能特性补齐、Bug 修改等。功能补齐包括了支持 ANSI SQL 的一些函数、区分 SQL 保留关键字以及内置函数等。这个 ISSUE 下面对应了 231 个子 ISSUE,如果这部分的 ISSUE 都解决了,那么 Spark SQL 和 PostgreSQL 或者 ANSI SQL:2011 之间的差异更小了。
SparkR 向量化读写
Spark 是从 1.4 版本开始支持 R 语言的,但是那时候 Spark 和 R 进行交互的架构图如下:
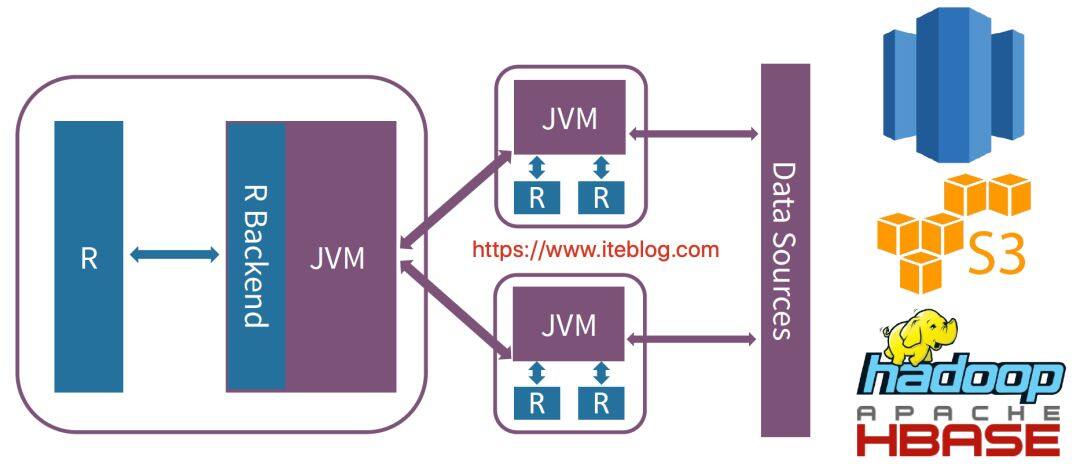
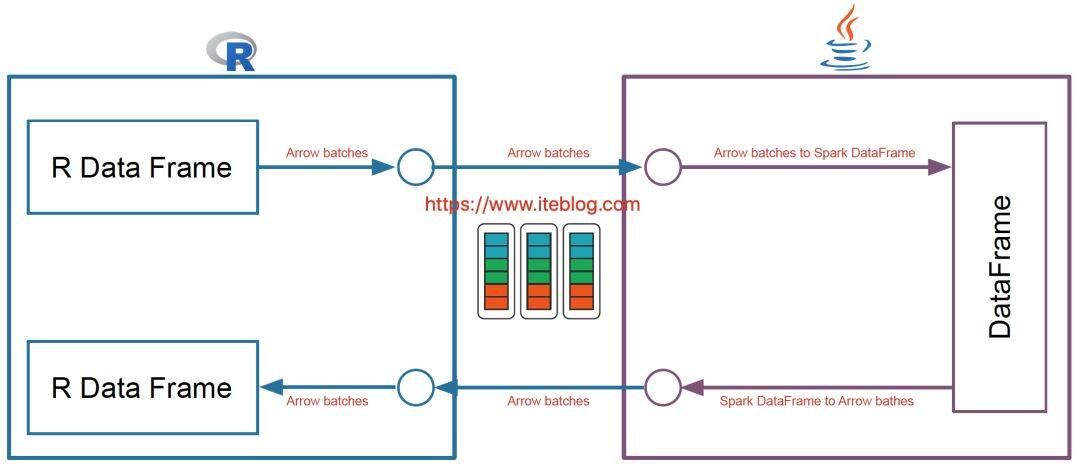
每当我们使用 R 语言和 Spark 集群进行交互,需要经过 JVM ,这也就无法避免数据的序列化和反序列化操作,这在数据量很大的情况下性能是十分低下的!
而且 Apache Spark 已经在许多操作中进行了向量化优化(vectorization optimization),例如,内部列式格式(columnar format)、Parquet/ORC 向量化读取、Pandas UDFs 等。向量化可以大大提高性能。SparkR 向量化允许用户按原样使用现有代码,但是当他们执行 R 本地函数或将 Spark>
可以看出,SparkR 向量化是利用 Apache Arrow,其使得系统之间数据的交互变得很高效,而且避免了数据的序列化和反序列化的消耗,所以采用了这个之后,SparkR 和 Spark 交互的性能得到极大提升。
其他
附:Spark 3.0 重要 ISSUE
原文链接: